【SparkCore】RDD的持久化与缓存(HDFS与内存磁盘)
目录
内存或磁盘
介绍
持久化/缓存API详解
代码
存储级别
总结
HDFS
介绍
代码
总结
-
内存或磁盘
介绍
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率
持久化/缓存API详解
persist方法和cache方法
RDD通过persist或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。通过查看RDD的源码发现cache最终也是调用了persist无参方法(默认存储只存在内存中)
代码
启动集群和spark-shell
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-all.sh
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-shell
将一个RDD持久化,后续操作该RDD就可以直接从缓存中拿
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
//缓存/持久化
rdd2.cache
//触发action,会去读取HDFS的文件,rdd2会真正执行持久化
rdd2.sortBy(_._2,false).collect
//触发action,会去读缓存中的数据,执行速度会比之前快,因为rdd2已经持久化到内存中了
rdd2.sortBy(_._2,false).collect
存储级别
默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的
| 持久化级别 |
说明 |
| MEMORY_ONLY(默认) |
将RDD以非序列化的Java对象存储在JVM中。 如果没有足够的内存存储RDD,则某些分区将不会被缓存,每次需要时都会重新计算。 这是默认级别。 |
| MEMORY_AND_DISK (开发中可以使用这个) |
将RDD以非序列化的Java对象存储在JVM中。如果数据在内存中放不下,则溢写到磁盘上.需要时则会从磁盘上读取 |
| MEMORY_ONLY_SER (Java and Scala) |
将RDD以序列化的Java对象(每个分区一个字节数组)的方式存储.这通常比非序列化对象(deserialized objects)更具空间效率,特别是在使用快速序列化的情况下,但是这种方式读取数据会消耗更多的CPU。 |
| MEMORY_AND_DISK_SER (Java and Scala) |
与MEMORY_ONLY_SER类似,但如果数据在内存中放不下,则溢写到磁盘上,而不是每次需要重新计算它们。 |
| DISK_ONLY |
将RDD分区存储在磁盘上。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2等 |
与上面的储存级别相同,将持久化数据存为两份,备份每个分区存储在两个集群节点上。 |
| OFF_HEAP(实验中) |
与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。 (即不是直接存储在JVM内存中) 如:Tachyon-分布式内存存储系统、Alluxio - Open Source Memory Speed Virtual Distributed Storage |
总结
1.RDD持久化/缓存的目的是为了提高后续操作的速度
2.缓存的级别有很多,默认只存在内存中,开发中使用memory_and_disk
3.只有执行action操作的时候才会真正将RDD数据进行持久化/缓存
4.实际开发中如果某一个RDD后续会被频繁的使用,可以将该RDD进行持久化/缓存
-
HDFS
介绍
问题
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等
解决
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用
代码
格式:
//设置永久存储HDFS的目录
SparkContext.setCheckpointDir("目录")
//使用checkpoint进行保存
RDD.checkpoint()
例:
//设置检查点目录,会立即在HDFS上创建一个空目录
sc.setCheckpointDir("hdfs://node01:8020/ckpdir")
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//对rdd1进行检查点保存
rdd1.checkpoint()
//Action操作才会真正执行checkpoint
//后续如果要使用到rdd1可以从checkpoint中读取
rdd1.collect
总结
开发中如何保证数据的安全性性及读取效率
可以对频繁使用且重要的数据,先做缓存/持久化,再做checkpint操作
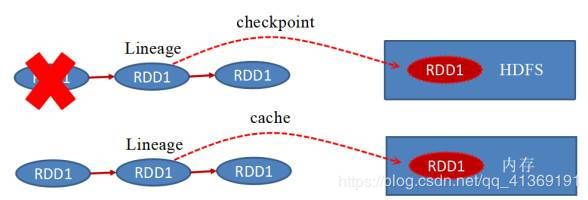
持久化和Checkpoint的区别
位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存--实验中)
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上
生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法
Checkpoint的RDD在程序结束后依然存在,不会被删除
RDD依赖关系(Lineage,血统)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链