Hadoop学习笔记
作者:伍栋梁
编辑:陈人和
1.hadoop安装与介绍
1.1hadoop生态圈介绍
分布式系统—Google三架马车(GFS,mapreduce,Bigtable)。google 公布了发布了这三个产品的详细设计论文,但没有公布这三个产品的源码。Yahoo 资助的 Hadoop 按照这三篇论文的开源 Java 实现:Hadoop 对应 Mapreduce,Hadoop Distributed File System (HDFS)对应Google fs,Hbase对应Bigtable。不过在性能上Hadoop比 Google 要差很多。
1.1.1 GOOGLE三驾马车
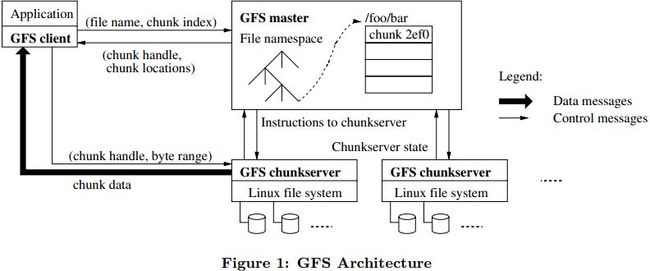
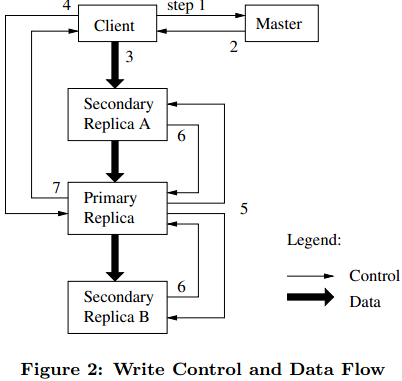
(1)分布式文件系统 GFS :GFS 是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。对外的接口:和文件系统类似,GFS 对外提供 create, delete,open, close,read, 和 write 操作。
(2)分布式计算 mapreduce 【通过并行计算可以处理 T 级别 p 级别 e 级别 z 级别的的数据】
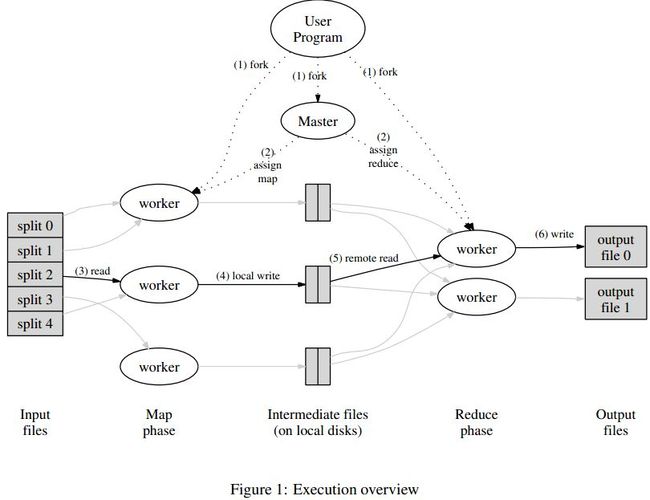
Mapreduce 由 map 与 reduce 组成,map 把数据分发到多个主机上,reduce 是规约,把 map 的worker 计算出来的结果合并出来。Google 的 mapreduce 实现使用 GFS 的数据。Mapreduce的计算使用方式, Distributed Grep,Count of URL Access Frequency, Graph,Distributed Sort。
(3)分布式存储 BIGTABLE【就像文件系统需要数据库来存储结构化数据一样,GFS 也需要 Bigtable 来存储结构化数据。】
* BigTable 是建立在 GFS ,Scheduler ,Lock Service 和 MapReduce 之上的。
*每个 Table 都是一个多维的稀疏图
*为了管理巨大的 Table,把 Table 根据行分割,这些分割后的数据统称为:Tablets。每个Tablets 大概有 100-200 MB,每个机器存储 100 个左右的 Tablets。底层的架构是:GFS。由于 GFS 是一种分布式的文件系统,采用 Tablets 的机制后,可以获得很好的负载均衡。比如:可以把经常响应的表移动到其他空闲机器上,然后快速重建。
Google 新三架马车:
Caffeine : 新版的搜索引擎
Pregel:图算法引擎,
Dremel:交互式数据分析系统
1.1.2 对应的Hadoop部分
(1)HDFS(Hadoop分布式文件系统)
Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS 简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
Client:切分文件;访问 HDFS;与 NameNode 交互,获取文件位置信息;与 DataNode 交互,读取和写入数据。
NameNode:管理 HDFS 的名称空间和数据块映射信息,配置副本策略,处理客户端请求。【Master节点,在 hadoop1.X 中只有一个】
DataNode:存储实际的数据【Slave 节点,汇报存储信息给 NameNode】
Secondary NameNode:定期合并 fsimage 和 fsedits,推送给 NameNode;辅助 NameNode,分担其工作量;紧急情况下,可辅助恢复 NameNode,但 Secondary NameNode 并非NameNode 的热备。

(2)Mapreduce (分布式计算框架)
【MapReduce 是一种计算模型,用以进行大数据量的计算。适合在大量计算机组成的分布式并行环境里进行数据处理。】
Map 对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。
Reduce 则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
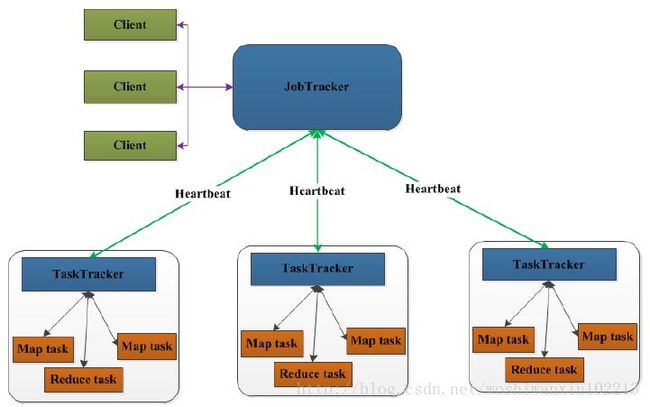
JobTracker:Master 节点,只有一个,管理所有作业,作业/任务的监控、错误处理等;将
任务分解成一系列任务,并分派给 TaskTracker。
TaskTracker:Slave 节点,运行 Map Task 和 Reduce Task;并与 JobTracker交互,汇报任务
状态。
Map Task:解析每条数据记录,传递给用户编写的 map(),并执行,将输出结果写入本地磁
盘(如果为 map-only 作业,直接写入 HDFS)。
Reducer Task:从 Map Task 的执行结果中,远程读取输入数据,对数据进行排序,将数据
按照分组传递给用户编写的 reduce 函数执行。
Mapreduce 处理流程,以 wordCount 为例:
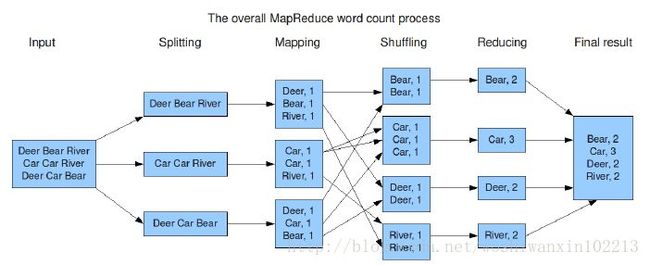
(3)Hbase(分布式列存数据库)
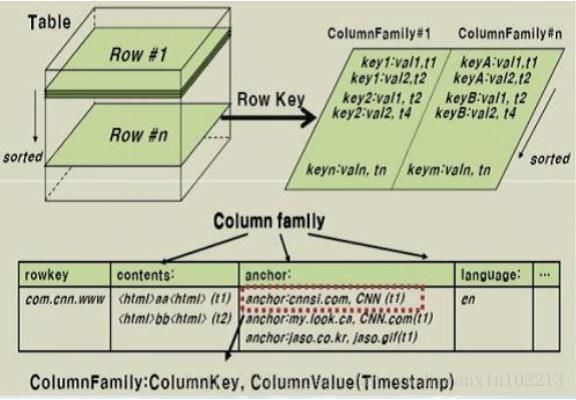
HBase 是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase 采用了 BigTable 的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase 提供了对大规模数据的随机、实时读写访问,同时,HBase 中保存的数据可以使用MapReduce 来处理,它将数据存储和并行计算完美地结合在一起。
数据模型:Schema-->Table-->ColumnFamily-->Column-->RowKey-->TimeStamp-->Value
1.2 hadoop 的生态系统
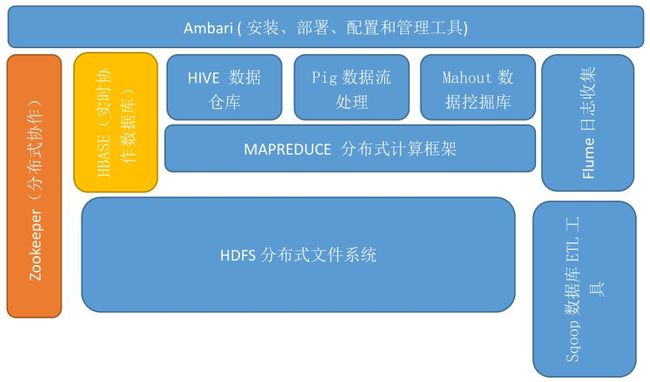
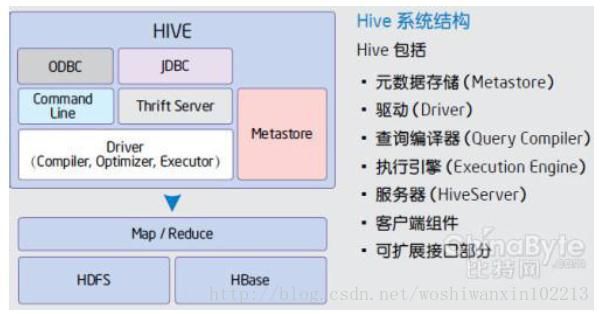
Apache Hive:
数据仓库基础设施,提供数据汇总和特定查询。这个系统支持用户进行有效
的查询,并实时得到返回结果。由 facebook 开源,最初用于解决海量结构化的日志数据统计问题。Hive 定义了一种类似 SQL 的查询语言(HQL),将 SQL 转化为 MapReduce 任务在 Hadoop 上执行。通常用于离线分析。
Apache Spark:
Apache Spark 是提供大数据集上快速进行数据分析的计算引擎。它建立在HDFS 之上,却绕过了 MapReduce 使用自己的数据处理框架。Spark 常用于实时查询、流处理、迭代算法、复杂操作运算和机器学习。
Apache Ambari:
Ambari 用来协助管理 Hadoop。它提供对 Hadoop 生态系统中许多工具的
支持,包括 Hive、HBase、Pig、 Spooq 和 ZooKeeper。这个工具提供集群管理仪表盘,可以跟踪集群运行状态,帮助诊断性能问题。
ApachePig:
Pig 是一个集成高级查询语言的平台,可以用来处理大数据集。基于 Hadoop 的数据流系统,由 yahoo!开源。设计动机是提供一种基于MapReduce 的 ad-hoc(计算在 query 时发生)数据分析工具定义了一种数据流语言—Pig Latin,将脚本转换为 MapReduce 任务在 Hadoop 上执行。通常用于进行离线分析。
Zookeeper (分布式协作服务):
源自 Google 的 Chubby 论文
Sqoop (数据同步工具):Sqoop 是 SQL-to-Hadoop 的缩写,主要用于传统数据库和Hadoop 之前传输数据。数据的导入和导出本质上是Mapreduce 程序,充分利用了MR 的并行化和容错性。
Mahout (数据挖掘算法库):
Mahout 的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout 现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout 还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或 Cassandra)集成等数据挖掘支持架构。
Flume (日志收集工具):
Cloudera 开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在 Flume 中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume 是一个可扩展、适合复杂环境的海量日志收集系统。
资源管理器的简单介绍(YARN和 和 mesos):
随着互联网的高速发展,基于数据密集型应用的计算框架不断出现,从支持离线处理的MapReduce,到支持在线处理的 Storm,从迭代式计算框架 Spark 到流式处理框架 S4,…,各种框架诞生于不同的公司或者实验室,它们各有所长,各自解决了某一类应用问题。而在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方案如下:网页建索引采用 MapReduce 框架,自然语言处理/数据挖掘采用 Spark(网页 PageRank计算,聚类分类算法等,【注】Spark 现在不太成熟,很少有公司尝试使用),对性能要求很高的数据挖掘算法用MPI 等。考虑到资源利用率,运维成本,数据共享等因素,公司一般希望将所有这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样,便诞生了资源统一管理与调度平台,典型代表是 Mesos 和 YARN。
其他的一些开源组件:
1) cloudrea impala:
一个开源的 Massively Parallel Processing(MPP)查询引擎 。与 Hive 相同的元数据、SQL 语法、ODBC 驱动程序和用户接口(Hue Beeswax),可以直接在 HDFS 或 HBase 上提供快速、交互式 SQL 查询。Impala 不再使用缓慢的Hive+MapReduce 批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从HDFS 或者 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
2)spark
Spark 是个开源的数据分析集群计算框架,建立于 HDFS 之上。Spark 与 Hadoop 一样,用于构建大规模、低延时的数据分析应用。Spark 采用 Scala 语言实现,使用 Scala 作为应用框架。Spark 采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。与Hadoop 不同的是,Spark 和 Scala 紧密集成,Scala 像管理本地 collective 对象那样管理分布式数据集。Spark支持分布式数据集上的迭代式任务,实际上可以在 Hadoop 文件系统上与Hadoop 一起运行(通过 YARN、Mesos 等实现)。
3) storm
Storm 是一个分布式的、容错的实时计算系统, 属于流处理平台,多用于实时计算并更新数据库。也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式 RPC”,以并行的方式运行昂贵的运算。
2.HDFS
Hadoop整合了众多文件系统,在其中有一个综合性的文件系统抽象,它提供了文件系统实现的各类接口,Hadoop提供了许多文件系统的接口,用户可以使用URI方案选取合适的文件系统来实现交互。提供了一个高层的文件系统抽象类org.apache.hadoop.fs.FileSystem,这个抽象类展示了一个分布式文件系统,并有几个具体实现,如下图(hadoop文件系统)所示。【HDFS只是这个抽象文件系统的一个实例。】
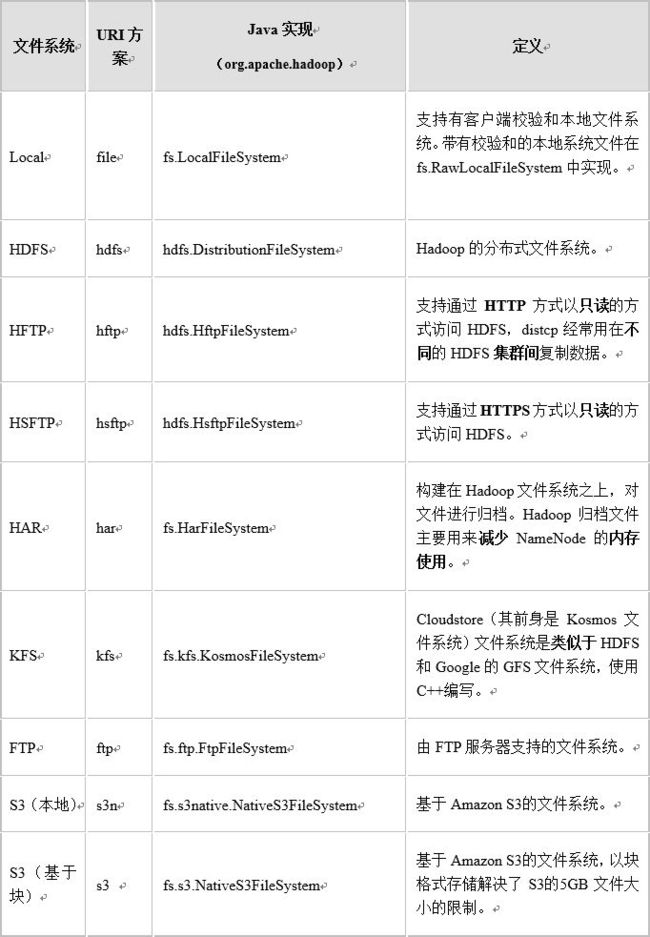
2.1 基础知识
2.1.1基本概念
分布式文件系统
(1)特点
分布式文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。
分布式文件系统的基于客户机/服务器模式。通常,一个分布式文件系统提供多个供用户访问的服务器。
分布式文件系统一般都会提供备份和容错的功能
分布式文件系统一般都基于操作系统的本地文件系统
ext3, ext4
NTFS
(2)为什么需要分布式文件系统
传统文件系统最大的问题是容量和吞吐量的限制,多用户多应用的并行读写是分布式文件系统产生的根源,一块硬盘的读写性能,比不上多块硬盘同时读写的性能【1 HDD=75MB/sec
1000 HDDs = 75GB/sec】。
扩充存储空间的成本低廉,可提供冗余备份,可以为分布式计算提供基础。
hdfs:
(1)概念
Hadoop Distributed File System是一个基于*nix的使用Java实现的、分布式的、可横向扩展的文件系统,是Hadoop的核心组件。是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(LargeData Set)的应用处理带来了很多便利。
(2)设计目标
A、基于廉价的普通硬件,可以容忍硬件出错,系统中的某一台或几台服务器出现故障的时候,系统仍可用且数据保持完整
B、大数据集(大文件),HDFS适合存储大量文件,总存储量可以达到PB,EB级,HDFS适合存储大文件,单个文件大小一般在百MB级之上,文件数目适中。
C、简单的一致性模型,HDFS应用程序需要一次写入,多次读取一个文件的访问模式,支持追加(append)操作,但无法更改已写入数据。
D、顺序的数据流访问,HDFS适合用于处理批量数据,而不适合用于随机定位访问。
E、侧重高吞吐量的数据访问,可以容忍数据访问的高延迟。
F、为把“计算”移动到“数据”提供基础和便利。
数据块:
HDFS(HadoopDistributed File System)默认的最基本的存储单位是64M的数据块,【可针对每个文件配置,由客户端指定,每个块有一个自己的全局ID】。和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。与传统文件系统不同的是,如果实际数据没有达到块大小,则并不实际占用磁盘空间【如果一个文件是200M,则它会被分为4个块: 64+64+64+8。尽管64m为基本存储单位,但10m的文件仍然只占10m的空间】
使用块的好处:
当一个文件大于集群中任意一个磁盘的时候,文件系统可以充分利用集群中所有的磁盘。管理块使底层的存储子系统相对简单。块更加适合备份,从而为容错和高可用性的实现带来方便。
块的冗余备份:
每个块在集群上会存储多份(replica),默认复制份数为3,【可针对每个文件配置,由客户端指定,可动态修改】。
某个块的所有备份都是同一个ID,系统无需记录“哪些块其实是同一份数据”。
系统可以根据机架的配置自动分配备份位置,第一份在集群的某个机架的某台机器上,其他两份在另外的一个机架的两台机器上。【此策略是性能与冗余性的平衡,机架信息需要手工配置】。
元数据
元数据包括:
文件系统目录树信息:文件名,目录名、文件和目录的从属关系、 文件和目录的大小,创建及最后访问时间、权限
文件和块的对应关系:文件由哪些块组成
块的存放位置:机器名,块ID
数据存储的方法:
元数据存储在一台指定的服务器上(NameNode)
实际数据储存在集群的其他机器的本地文件系统中(DataNode)
Namenode
NameNode是用来管理文件系统命名空间的组件【一个HDFS集群只有一台NameNode一个命名空间,一个根目录】,其上存放了HDFS的元数据。一个HDFS集群只有一份元数据,目前有单点故障的问题。
元数据节点是分布式文件系统中的管理者,用来管理文件系统的命名空间,集群配置信息和存储块的复制等。其将所有的文件和文件夹的元数据保存在一个文件系统树中。这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)。还保存了一个文件包括哪些数据块,分布在哪些数据节点上。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
元数据保存在NameNode的内存当中,以便快速查询。【1G内存大致可以存放1,000,000个块对应的元数据信息】,按缺省每块64M计算,大致对应64T实际数据。这些信息是在系统启动的时候从数据节点收集而成的。
Datanode
数据节点是文件系统中真正存储数据的地方。客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data。 其周期性的向元数据节点回报其存储的数据块信息。
每个块会在本地文件系统产生两个文件,一个是实际的数据文件,另一个是块的附加信息文件,其中包括数据的校验和,生成时间。客户端读取/写入数据的时候直接与DataNode通信。
【DataNode通过心跳包(Heartbeat)与NameNode通讯,这两类节点分别承担Master和Worker具体任务的执行节点。】
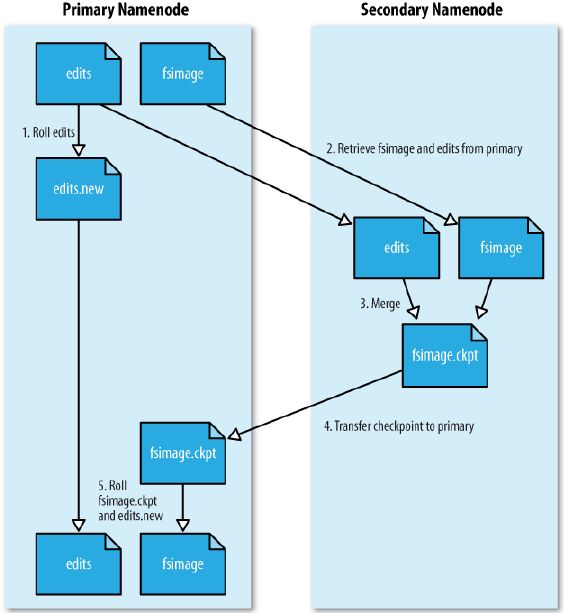
Secondary namenode
从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。其主要功能就是周期性将元数据节点的命名空间镜像文件【fsimage】和修改日志【edits】合并,以此来控制edits的文件大小在合理的范围。合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
为了缩短集群重启时NameNode重建fsimage的时间,在NameNode硬盘损坏的情况下,Secondary NameNode也可用作数据恢复,但绝不是全部。一般情况下Secondary Namenode运行在不同与NameNode的主机上,并且它的内存需求和NameNode是一样的。
nn,dn,snn总结
1namenode
记录源数据的命名空间
数据分配到那些datanode保存
协调客户端对文件访问
2.datanode
负责所在物理节点的储存管理
一次写入,多次读取(不能修改)
文件由数据块组成,典型的块大小是64M
数据块尽量散步到各个节点
3.secondarynamenode (辅助)
当NameNode重启的时候,会合并硬盘上的fsimage文件和edits文件,得到完整的Metadata信息。这个fsimage文件可以看做是一个过时的Metadata信息文件(最新的Metadata修改信息在edits文件中)。如果edits文件非常大,那么这个合并过程就非常慢,导致HDFS长时间无法启动,如果定时将edits文件合并到fsimage,那么重启NameNode就可以非常快。SecondaryNameNode就做这个合并的工作。
总体结构:
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。【Client就是需要获取分布式文件系统文件的应用程序。】
HDFS典型的部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。

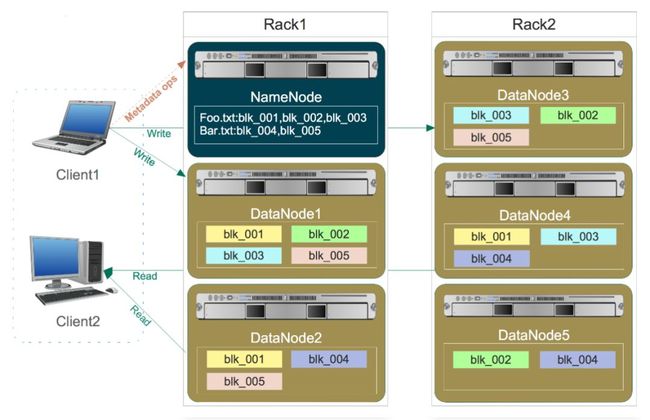
文件读入读出:
1)文件写入
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
2)文件读取
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
2.1.2 HDFS特性和原理
HDFS优点
1)处理超大文件
这里的超大文件通常是指百MB、设置数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。
2)流式的访问数据
HDFS的设计建立在更多地响应"一次写入、多次读写"任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。
3)运行于廉价的商用机器集群上
Hadoop设计对硬件需求比较低,只须运行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。廉价的商用机也就意味着大型集群中出现节点故障情况的概率非常高。这就要求设计HDFS时要充分考虑数据的可靠性,安全性及高可用性。
HDFS缺点
1)不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:对于那些有低延时要求的应用程序,HBase是一个更好的选择。通过上层数据管理项目来尽可能地弥补这个不足。在性能上有了很大的提升,它的口号就是goes real time。使用缓存或多master设计可以降低client的数据请求压力,以减少延时。还有就是对HDFS系统内部的修改,这就得权衡大吞吐量与低延时了,HDFS不是万能的银弹。
2)无法高效存储大量小文件
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没法实现了。还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。举个例子,处理10000M的文件,若每个split为1M,那就会有10000个Maptasks,会有很大的线程开销;若每个split为100M,则只有100个Maptasks,每个Maptask将会有更多的事情做,而线程的管理开销也将减小很多。
改进策略:要想让HDFS能处理好小文件,有不少方法。
利用SequenceFile、MapFile、Har等方式归档小文件,这个方法的原理就是把小文件归档起来管理,HBase就是基于此的。对于这种方法,如果想找回原来的小文件内容,那就必须得知道与归档文件的映射关系。
横向扩展,一个Hadoop集群能管理的小文件有限,那就把几个Hadoop集群拖在一个虚拟服务器后面,形成一个大的Hadoop集群。google也是这么干过的。
多Master设计,这个作用显而易见了。正在研发中的GFS II也要改为分布式多Master设计,还支持Master的Failover,而且Block大小改为1M,有意要调优处理小文件啊。
附带个Alibaba DFS的设计,也是多Master设计,它把Metadata的映射存储和管理分开了,由多个Metadata存储节点和一个查询Master节点组成。
3)不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。目前HDFS还不支持多个用户对同一文件的写操作,以及在文件任意位置进行修改。
HDFS客户端
(1)命令行客户端
同一个Hadoop安装包
(2)API客户端
Java库
非POSIX接口
封装了通信细节
元数据的持久化
NameNode里使用两个非常重要的本地文件来保存元数据信息:
Fsimage:
保存了文件系统目录树信息,保存了文件和块的对应关系
edits
保存文件系统的更改记录(journal),当客户端对文件进行写操作(包括新建或移动)的时候,操作首先记入edits,成功后才会更改内存中的数据,并不会立刻更改硬盘上的fsimage
块的位置信息并不做持久化
元数据的载入和更新
NameNode启动时:
通过fsimage读取元数据,载入内存。执行edits中的记录,在内存中生成最新的元数据
清空edits,保存最新的元数据到fsimage。收集DataNode汇报的块的位置信息
NameNode运行时:
对文件创建和写操作,记录到edits,更新内存中的元数据,收集DataNode汇报的块的创建和复制信息。
HDFS创建文件流程
客户端
客户端请求NameNode在命名空间中建立新的文件元信息。
如果不能创建文件则 NameNode 会返回失败。【文件已存在,资源不足】
如创建成功,客户端得到此文件的写保护锁。
NameNode
Namenode检查集群和文件状态。
创建写保护锁来保证只有一个客户端在操作该文件。
建立该文件的元信息。
把创建文件这个事件加入edits。
为该文件分配块,以及块的冗余备份位置。
HDFS的读操作流程
客户端与NameNode通讯获取文件的块位置信息,其中包括了块的所有冗余备份的位置信息:DataNode的列表
客户端获取文件位置信息后直接同有文件块的DataNode通讯,读取文件。如果第一个DataNode无法连接,客户端将自动联系下一个DataNode
如果块数据的校验值出错,则客户端需要向NameNode报告,并自动联系下一个DataNode,
Namenode并不参与数据实际传输
HDFS写操作流程
客户端写一个文件并不是直接写到HDFS上,HDFS客户端接收用户数据,并把内容缓存在本地,当本地缓存收集足够一个HDFS块大小的时候,客户端同NameNode通讯注册一个新的块。注册块成功后,NameNode会给客户端返回一个DataNode的列表,列表中是该块需要存放的位置,包括冗余备份。
客户端向列表中的第一个DataNode写入块,当完成时第一个DataNode 向列表中的下个DataNode发送写操作,并把数据已收到的确认信息给客户端,同时发送确认信息给NameNode,之后的DataNode重复之上的步骤,当列表中所有DataNode都接收到数据并且由最后一个DataNode校验数据正确性完成后,返回确认信息给客户端。
收到所有DataNode的确认信息后,客户端删除本地缓存,客户端继续发送下一个块,重复以上步骤。当所有数据发送完成后,写操作完成。
(客户端请求namenode创建新文件客户端将数据写入DFSOutputStream建立pipetine依次将目标数据块写入各个datanode,建立多个副本)
HDFS追加写(append)的操作流程
客户端与NameNode通讯,获得文件的写保护锁及文件最后一个块的位置(DataNode列表)
客户端挑选一个DataNode作为主写入节点,并对其余节点上的该数据块加锁,开始写入数据,与普通写入流程类似,依次更新各个DataNode上的数据,更新时间戳和校验和,最后一个块写满,并且所有备份块都完成写入后,向NameNode申请下一个数据块。
Secondary NameNode的运行过程
Secondary NameNode根据配置好的策略决定多久做一次合并
fs.checkpoint.period 和 fs.checkpoint.size
通知NameNode现在需要回滚edits日志,此时NameNode的新操作将写入新的edits 文件
Secondary NameNode通过HTTP从NameNode取得fsimage 和 edits
Secondary NameNode将fsimage载入内存,执行所有edits中的操作,新建新的完整的fsimage
Secondary NameNode将新的fsimage传回NameNode
NameNode替换为新的fsimage并且记录此checkpoint的时间
2.1.3 hdfs高级特性
hdfs作用
1.提供分布式储存机制,提供可线形增长的海量储存能力
2.自动数据冗余,无须使用raid,无须另行备份
3.为进一步分析计算提供数据基础
(可以在任意节点上使用HDFS储存,不用在namenode节点,datanode也可以)
hdfs设计基础与目标
1.硬件错误是常态,因此需要冗余(因为hadoop储存都比较廉价)
2.流式数据访问.即数据批量读取而非随机读写,hadoop擅长做的是数据分析而不是事务处理
3.大数据处理
4.简单一致性模型,为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即文件一经写入, 关闭,就再也不能修改了.
5.程序采用"数据就近"分配节点执行
元数据目录
[hadoop@h1 ~]$ cd/tmp/hadoop-hadoop/dfs/name
[hadoop@h1 name]$ ls
current image in_use.lock previous.checkpoint
[hadoop@h1 name]$ cd current/
[hadoop@h1 current]$ ls
edits fsimage fstime VERSION
[hadoop@h1 current]$ strings VERSION
#Thu Aug 27 13:13:39 CST 2015
namespaceID=1025320819 (命名空间)
cTime=0 (创建的时间,升级后会改变)
storageType=NAME_NODE (储存类型)
layoutVersion=-19 (hdfs版本)
[hadoop@h1 current]$【
fsimage(映像文件,namenode主要在内存中工作,检查点时候先到fsimage中)edits (操作动作写到edits 类似于redo文件,fsimage写一次 之前的的内容被清空)
[hadoop@h1 ~]$ cd/tmp/hadoop-hadoop/dfs/namesecondary/
[hadoop@h1 namesecondary]$ ls
current image in_use.lock
[hadoop@h1 namesecondary]$
】
查看datanode节点
[
[hadoop@h2 ~]$ cd /tmp/hadoop-hadoop/dfs/
[hadoop@h2 dfs]$ ls
data
[hadoop@h2 dfs]$ cd data/current/
[hadoop@h2 current]$ ls
blk_5351326362188108637 dncp_block_verification.log.curr
blk_5351326362188108637_1154.meta VERSION【blk开头的为数据块】
HDFS负载均衡
[hadoop@h91 hadoop-0.20.2-cdh3u5]$bin/start-balancer.sh -threshold 10;
(如果节点间 数据使用量的偏差 小于10% 就认为正常 )
机架感知
添加节点(删节点)
1)在新节点安装好hadoop
2)把namenode的有关配置文件复制到该节点
3)修改masters和staves文件,增加该节点
4)设置ssh免密码进出该节点
5)单独启动该节点上的datanode和tasktracker (hadoop-daemon.sh start datanode/tasktracker)
6)运行start-batancensh进行数据负载均衡
*是否要重启集群?
hadoop 压缩
对Hadoop来说,有两个地方需要用到压缩:其一,在HDFS上存储数据文件,压缩之后数据体积更小,有利存储;其二,集群间的通讯需要压缩数据,这样可以提高网络带宽的利用率。如果用MapReduce处理压缩文件,那么要求压缩算法能支持文件分割,因为MapReduce的过程需要将文件分割成多个切片,如果压缩算法不支持分割,就不能做切片了。
在Java里,一切输入输出都用流的方式进行。一个可以读取字节序列的对象叫输入流。文件,网络连接,内存区域,都可以是输入流。一个可以写入字节序列的对象叫输出流。文件,网络连接,内存区域,都可以是输出流。
Hadoop如何压缩?假设,输入流是A,输出流是B。A和B有很多种可能,可以是文件,网络连接,内存区域,标准输入,标准输出的两两组合。做压缩的话,先选择压缩算法,然后根据压缩算法创建相应的压缩器,然后用压缩器和输出流B创建压缩输出流C,最后,将数据从输入流A复制到压缩输出流C即可进行压缩并输出结果。
如果是解压缩,先选择解压缩算法,然后根据解压缩算法创建相应的解压缩器,然后用解压缩器和输入流A创建压缩输入流C,最后,将数据从输入流C复制到输出流B即可进行解压缩并输出结果。
1、编代码
viCprsF2F.java
importjava.net.URI;
importjava.io.InputStream;
importjava.io.OutputStream;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.io.compress.CompressionCodec;
importorg.apache.hadoop.io.IOUtils;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.fs.FileSystem;
importorg.apache.hadoop.util.ReflectionUtils;
publicclass CprsF2F{
public static void main(String[] args) throwsException{
if (args.length != 3){
System.err.println("Usage: CprsF2Fcmps_name src target");
System.exit(2);
}
Class codecClass =Class.forName(args[0]); //反射机制
Configuration conf = new Configuration();
CompressionCodec codec =(CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
//重构对象,org.apache.hadoop.io.compress.GzipCodec 加入新的属性,构成一个新的对象
InputStream in = null;
OutputStream out = null;
FileSystem fs =FileSystem.get(URI.create(args[1]), conf);
try{
in = fs.open(new Path(args[1]));
out =codec.createOutputStream(fs.create(new Path(args[2])));
IOUtils.copyBytes(in, out, conf);
}finally{
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}2、演示
[[email protected]]$ usr/jdk1.7.0_25/bin/javac CprsF2F.java[[email protected]]$ /usr/jdk1.7.0_25/bin/jar -cvf CprsF2F.jar CprsF2F.class
[[email protected]]$ echo "hellowrod">a.txt
[[email protected]]$ bin/hadoop fs -put a.txt a.txt
【压缩a.txt 压缩文件为b.txt】
[[email protected]]$ bin/hadoop jar CprsF2F.jar CprsF2Forg.apache.hadoop.io.compress.GzipCodec /user/hadoop/a.txt /user/hadoop/b.txt
[[email protected]]$ bin/hadoop fs -cat b.txt
???/???Yμ- (乱码)
[[email protected]]$ bin/hadoop fs -cat b.txt|gunzip
hellowrod2.1.4 HDFS可靠性
1)冗余副本策略
[hadoop@h1 ~]$ cd/usr/local/hadoop-1.2.1/conf/
[hadoop@h1 conf]$ cat hdfs-site.xml
Datanode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列 表(bbckreport)汇报给namenode
2)机架策略
集群_般放在不同机架上,机架间带宽要比机架内带宽要小
HDFS的"机架感知"(设置同一机架的脚本)
((RackAware.py
#!/usr/bin/python #-*-coding:UTF-8 importsys
rack ={"hadoop-node-31":"rackl",
"hadoop-node-32":"rackl",
"hadoop-node-49":"rack2",
"hadoop-node-50":"rack2",
"hadoop-node-51":"rack2",
"192.168.1.31":"rackl",
"192.168.1.32":"rackl",
"192.168.1.49":"rack2",
"192.168.1.50":"rack2",
"192.168.1.51":"rack2",
core-site.xml配置文件
topology.script.file.name
/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.py
topology.script.number.args
20
))一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丟失数据,也可以提高带宽利用率。
3)心跳机制
Namenode周期性从datanode接收心跳信号和块报告,Namenode根据块报告验证元数据没有按时发送心跳的datanode会被标记为宕机,不会再给它任何I/O请求,如果datanode失效造成副本数量下降,并且低于预先设置的阈值,namenode会检测 出这些数据块,并在合适的时机进行重新复制,引发重新复制的原因还包括数据副本本身损坏、磁盘错误,复制因子被增大等
4)安全模式
Namenode启动时会先经过一个"安全模式〃阶段 ,安全模式阶段不会产生数据写,在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是"安全"的。,在一定比例(可设置)的数据块被确定为"安全"后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数?
[hadoop@h1 hadoop-1.2.1]$ bin/hadoopdfsadmin -safemode enter (进入安全模式)
Safe mode is ON
[hadoop@h1 input]$ cd /home/hadoop/input/
[hadoop@h1 input]$ touch ab
[hadoop@h1 input]$ cd/usr/local/hadoop-1.2.1/
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs-put /home/hadoop/input/abc ./in
(传递文件到hdfs中不能成功,因为处于安全模式)
put:org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create/user/hadoop/in/abc. Name node is in safe mode.
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -ls./in(查看下,abc文件没有被拷入)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs-rmr ./in/test1.txt
(删除文件也报错,安全模式下不允许删除)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoopdfsadmin -safemode leave (退出安全模式)
Safe mode is OFF5)校验和
在文件创立时,每个数据块都产生校验和,校验和保存在.meta文件内 ,客户端获取数据时可以检査校验和是否相同,从而发现数据块是否损坏。如果正在读取的数据块损坏,则可以继续读取其它副本。
[hadoop@h2 ~]$ cd /tmp/hadoop-hadoop/dfs(datanode节点)
[hadoop@h2 dfs]$ cd data/current/
[hadoop@h2 current]$ ls (会看到数据块,拷贝到hdfs保存的数据,分散到各个节点)
blk_7094582618848038271_1003.meta (.meta后缀的为保存块的校验码)6)回收站
删除文件时,其实是放入回收站/trash。回收站里的文件可以快速恢复。可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值,就被彻底删除, 并且释放占用的数据块。
(开启回收站功能)
[hadoop@h1 ~]$ cd/usr/local/hadoop-1.2.1/conf
[hadoop@h1 conf]$ vi core-site.xml (添加下面一段,10080为保留时间,单位分钟)
fs.trash.interval
10080
Number of minutes between trashcheckpoints.
If zero, the trash feature is disabted
[hadoop@h1 conf]$ cd ..
[hadoop@h1 hadoop-1.2.1]$ bin/stop-all.sh
[hadoop@h1 hadoop-1.2.1]$ bin/start-all.sh(重启 回收站功能生效)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -ls./in
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs-rmr ./in/test1.txt (删除test1.txt)
Moved to trash:hdfs://h1:9000/user/hadoop/in/test1.txt
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -ls(发现多了个.Trash目录)
drwxr-xr-x - hadoop supergroup 0 2013-11-26 14:47 /user/hadoop/.Trash
drwxr-xr-x - hadoop supergroup 02013-11-26 14:47 /user/hadoop/in
drwxr-xr-x - hadoop supergroup 02013-11-26 12:19 /user/hadoop/out
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -ls./.Trash/Current/user/hadoop/in (发现了我们删除的test1.txt)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -mv./.Trash/Current/user/hadoop/in/test1.txt ./in (恢复文件)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs -ls./in (又回来了)
[hadoop@h1 hadoop-1.2.1]$ bin/hadoop fs-expunge(清空回收站)7)元数据保护
映像文件刚和事务日志是Namenode的核心数据。可以配置为拥有多个副本,副本会降低Namenode的处理速度,但增加安全性,Namenode依然是单点,如果发生故障要手工切换。
8、Zookeeper
8.1
8.1.1 Zookeeper数据模型
zookeeper使用了一个类似⽂文件系统的树结构,数据可以挂在某个节点上,可以对这节点进行删改。
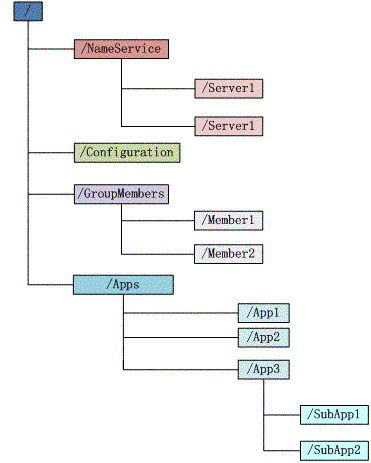
(1)每个节点在 zookeeper 中叫做 znode,并且其有⼀一个唯⼀一的路径标识,Znode 可以有⼦znode(临时节点除外),并且 znode 里可以存数据。
(2)Znode 中的数据可以有多个版本,比如某⼀一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本。
(3)znode 可以被监控,包括这个目录节点中存储的数据的修改,⼦子节点目录的变化等,一旦变化可以通知设置监控的客户端。这个功能是 zookeeper 对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等等。
(4)ZooKeeper 的数据结构, 与普通的⽂文件系统极为类似.每个 znode 由 3 部分组成
stat. 此为状态信息, 描述该 znode 的版本, 权限等信息.
data. 与该 znode 关联的数据.
children. 该 znode 下的⼦子节点.
8.1.2 ZooKeeper 命令
连接 server:zkCli.sh –server master
列出指定 node 的⼦子 node:ls /
创建 znode 节点, 并指定关联数据:create/rongxin hello【创建节点/hello, 并将字符串"world"关联到该节点中.】
获取 znode 的数据和状态信息:get /rongxin
删除 znode: delete /rongxin
【delete 命令可以删除指定 znode. 但当该 znode 拥有子 znode 时, 必须先删除其所有⼦ znode, 否则操作将失败。rmr 是⼀一个递归删除命令, 如果发⽣生指定节点拥有⼦子节点时, rmr 命令会首先删除⼦子节点.】
ls2(查看当前节点数据并能看到更新次数等数据) ,
set(修改节点)
8.1.3 znode 节点
znode节点的状态信息
【使用 get 命令获取指定节点的数据时, 同时也将返回该节点的状态信息, 称为 Stat.】
czxid. 节点创建时的 zxid.
mzxid. 节点最新⼀一次更新发⽣生时的zxid.
ctime. 节点创建时的时间戳.
mtime. 节点最新⼀一次更新发⽣生时的时间戳.
dataVersion. 节点数据的更新次数.
cversion. 其⼦子节点的更新次数.
aclVersion. 节点 ACL(授权信息)的更新次数.
ephemeralOwner. 如果该节点为ephemeral 节点,ephemeralOwner 值表示与该节点绑定的 session id. 如果该节点不是 ephemeral
节点, ephemeralOwner 值为 0. ⾄至于什么是ephemeral 节点, 请看后面的讲述.
dataLength. 节点数据的字节数.
numChildren. ⼦子节点个数.
zxid
znode 节点的状态信息中包含 czxid 和 mzxid, 那么什么是 zxid 呢?
ZooKeeper 状态的每一次改变, 都对应着一个递增的Transaction id, 该 id 称为 zxid. 由于 zxid 的递增性质, 如果 zxid1 小于zxid2, 那么 zxid1 肯定先于 zxid2 发⽣生. 创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致 Zookeeper 状态发⽣生改变, 从⽽而导致 zxid 的值增加。
session
在 client 和 server 通信之前, 首先需要建立连接, 该连接称为 session. 连接建立后, 如果发⽣生连接超时, 授权失败, 或者显式关闭连接, 连接便处于 CLOSED 状态, 此时 session 结束.
节点类型【临时、永久、有序】
永久节点:persistent 节点不和特定的 session 绑定, 不会随着创建该节点的 session 的结束⽽而消失, ⽽而是⼀一直存在, 除非该节点被显式删除.
临时节点:ephemeral节点是临时性的, 如果创建该节点的 session 结束了, 该节点就会被自动删除. ephemeral 节点不能拥有⼦子节点. 虽然 ephemeral 节点与创建它的session 绑定, 但只要该该节点没有被删除, 其他 session 就可以读写该节点中关联的数据. 。【Zookeeper 的客户端和服务器通信采用长连接⽅方式,每个客户端和 服务器通过⼼心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个session 失效,znode 也就删除了】使用-e参数指定创建ephemeral节点,如create –e/rongxin/test hello
有序节点:sequence 并非节点类型中的一种 sequence 节点既可以是 ephemeral 的, 也可以是 persistent 的. 创建sequence 节点时, ZooKeeperserver 会在指定的节点名称后加上⼀个数字序列, 该数字序列是递增的. 因此可以多次创建相同的sequence 节点, ⽽而得到不同的节点.使用-s 参数指定创建 sequence 节点.如create –s /hello/item/word

watch监听感兴趣的事件
在命令⾏行中, 以几个命令可以指定是否监听相应的事件。
(1) ls 命令: ls /rongxin true
【ls 命令的第⼀一个参数指定 znode, 第⼆二个参数如果为 true, 则说明监听该 znode 的⼦子节点的增减, 以及该 znode 本身的删除事件。】
(2)get 命令:get /rongxin true
【get 命令的第⼀一个参数指定 znode, 第⼆二个参数如果为 true, 则说明监听该 znode 的更新和删除事件.】
(3)stat 命令
【stat 命令用于获取 znode 的状态信息. 第⼀一个参数指定 znode, 如果第⼆二个参数为 true, 则监听该 node 的更新和删除事件.】
8.1.4 java 代码使用 zookeeper
Zookeeper 的使用主要是通过创建其jar 包下的 Zookeeper 实例,并且调用其接⼝口⽅方法进⾏行的,主要的操作就是对 znode 的增删改操作,监听 znode 的变化以及处理。
znode应用实例:实时更新服务器列表
(1)场景描述
在分布式应用中, 我们经常同时启动多个 server, 调用⽅方(client)选择其中之一发起请求.分布式应用必须考虑⾼高可用性和可扩展性: server 的应用进程可能会崩溃, 或者 server 本身也可能会宕机. 当 server 不够时, 也有可能增加 server 的数量. 总⽽而⾔言之, server 列表并非一成不变, ⽽而是一直处于动态的增减中.那么 client 如何才能实时的更新 server 列表呢? 解决的⽅方案很多, 本⽂文将讲述利用 ZooKeeper 的解决⽅方案.
(2)思路
启动 server 时, 在 zookeeper 的某个znode(假设为/sgroup)下创建一个子节点. 所创建的⼦子节点的类型应该为 ephemeral,这样一来, 如果 server 进程崩溃, 或者 server 宕机, 与 zookeeper 连接的 session 就结束了, 那么其所创建的⼦子节点会被zookeeper自动删除. 当崩溃的 server 恢复后, 或者新增 server 时, 同样需要在/sgroup 节点下创建新的子节点.对于 client, 只需注册/sgroup 子节点的监听, 当/sgroup 下的子节点增加或减少时, zookeeper 会通知 client, 此时 client 更新server 列表.
9、Shuffle阶段与mapreduce设置参数
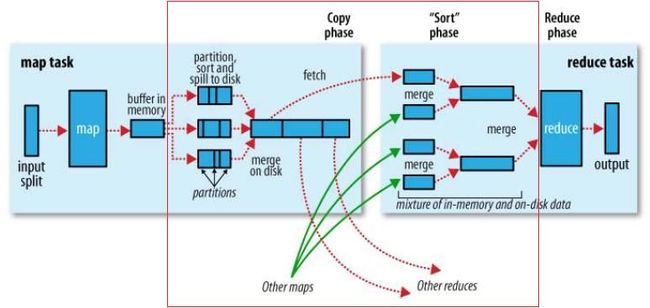
官方对Shuffle过程的描述图
(1)Shuffle 的大致范围:怎样把 maptask 的输出结果有效地传送到 reduce 端。也可以这样理解,Shuffle 描述着数据从 map task 输出到 reduce task 输入的这段过程。
(2)在 Hadoop 这样的集群环境中,大部分map task 与 reduce task 的执行是在不同的节点上。当然很多情况下 Reduce执行时需要跨节点去拉取其它节点上的 map task 结果。如果集群正在运行的job 有很多,那么task的正常执行对集群内部的网络资源消耗会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。还有在节点内,相比于内存,磁盘 IO 对 job 完成时间的影响也是可观的。
(3)我们对 Shuffle 过程的期望可以有:
完整地从 map task 端拉取数据到reduce 端。
在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
减少磁盘 IO 对task 执行的影响。
【能优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。】
9.1 shuffle阶段详解
以 WordCount 为例,假设它有 8 个 map task 和 3 个 reduce task。Shuffle 过程横跨 map与 reduce 两端,所以下面我也会分两部分来展开。
map端:
整个流程分了四步。简单些可以这样说,每个 map task 都有一个内存缓冲区,存储着map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个 map task 结束后再对磁盘中这个 maptask 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待 reducetask来拉数据。
1、map阶段
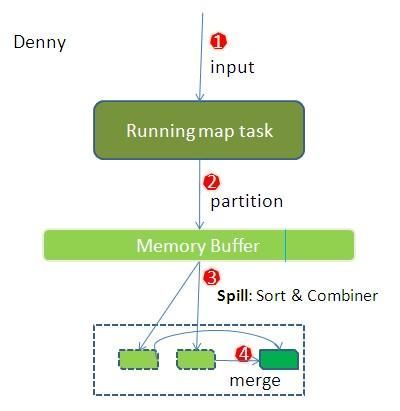
1)input
在 map task 执行时,它的输入数据来源于HDFS 的 block,当然在 MapReduce 概念中,map task 只读取 split。Split 与 block 的对应关系可能是多对一,默认是一对一。在 WordCount 例子里,假设 map 的输入数据都是像“hello”这样的字符串。
2)partition
在经过 mapper 的运行后,我们得知mapper 的输出是这样一个 key/value 对: key 是“hello”,value 是数值 1。因为当前 map 端只做加 1 的操作,在 reduce task 里才去合并结果集。前面我们知道这个job 有 3 个 reduce task,到底当前的“hello”应该交由哪个 reduce 去做呢,是需要现在决定的。
MapReduce提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量来决定当前的这对输出数据最终应该交由哪个reduce task 处理。默认对 key hash 后再以 reduce task 数量取模。默认的取模方式只是为了平均 reduce 的处理能力,如果用户自己对Partitioner 有需求,可以订制并设置到 job 上。
在我们的例子中,“hello”经过 Partitioner 后返回 0,也就是这对值应当交由第一个 reducer 来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map 结果,减少磁盘IO 的影响。我们的 key/value 对以及 Partition 的结果都会被写入缓冲区。当然写入之前,key 与 value 值都会被序列化成字节数组。整个内存缓冲区就是一个字节数组,它的字节索引及 key/value 存储结构我没有研究过。
3)spill sort combiner
内存缓冲区是有大小限制的(io.sort.mb),默认是 100MB。当 map task 的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。【这个从内存往磁盘写数据的过程被称为 Spill,中文可译为溢写】这个溢写是由单独线程来完成,不影响往缓冲区写 map 结果的线程。
溢写线程启动时不应该阻止map 的结果输出,所以整个缓冲区有个溢写的比例spill.percent(io.sort.spill.percent)。这个比例默认是 0.8,也就是当缓冲区的数据已经达到阈值(buffer size *spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这 80MB 的内存,执行溢写过程。Map task 的输出结果还可以往剩下的 20MB 内存中写,互不影响。当溢写线程启动后,需要对这 80MB 空间内的key 做排序(Sort)。排序是 MapReduce 模型默认的行为,这里的排序也是对序列化的字节做的排序。
因为 map task 的输出是需要发送到不同的 reduce 端去,而内存缓冲区没有对将发送到相同 reduce 端的数据做合并,那么这种合并应该是体现是磁盘文件中的。写到磁盘中的溢写文件是对不同的 reduce 端的数值做过合并。所以溢写过程一个很重要的细节在于,如果有很多个 key/value 对需要发送到某个reduce 端去,那么需要将这些 key/value 值拼接到一块,减少与 partition 相关的索引记录。
在针对每个 reduce 端而合并数据时,有些数据可能像这样:"hello"/1,
“hello"/1。对于WordCount 例子,就是简单地统计单词出现的次数,如果在
同一个 map task 的结果中有很多个像“hello”一样出现多次的 key,我们就应该把它们的值合并到一块,这个过程叫 reduce 也叫 combiner【MapRed
uce 的术语中,reduce 只指 reduce 端执行从多个 map task 取数据做计算的
过程。除 reduce 外,非正式地合并数据只能算做 combine 了。MapReduce 中
将 Combiner 等同于 Reducer。】如果 client 设置过 Combiner,那么现在就
是使用 Combiner 的时候了。将有相同 key 的 key/value 对的value 加起来
,减少溢写到磁盘的数据量。
Combiner 会优化 MapReduce 的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用 Combiner 呢?从这里分析,Combiner的输出是 Reducer 的输入,Combiner 绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce 的输入key/value与输出key/value 类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner 如果用好,它对 job 执行效率有帮助,反之会影响 reduce 的最终结果。
4)Merge
每次溢写会在磁盘上生成一个溢写文件,如果 map 的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当 map task 真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果 map 的输出结果很少,当 map 执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做 Merge。
Merge 是怎样的?如前面的例子,“aaa”从某个 map task 读取过来时值是 5,从另外一个 map 读取时值是 8,因为它们有相同的 key,所以得 merge 成 group。什么是 group。对于“hello”就是像这样的:{“hello”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。请注意,因为 merge 是将多个溢写文件合并到一个文件,所以可能也有相同的 key存在,在这个过程中如果 client 设置过 Combiner,也会使用 Combiner来合并相同的 key。至此,map 端的所有工作都已结束,最终生成的这个文件也存放在 TaskTracker够得着的某个本地目录内。每个 reduce task 不断地通过 RPC 从 JobTracker 那里获取map task 是否完成的信息,如果reduce task得到通知,获知某台 TaskTracker 上的 map task 执行完成,Shuffle 的后半段过程开始启动。
2、reduce阶段

1)copy
Copy 过程,简单地拉取数据。Reduce 进程启动一些数据 copy 线程(Fetcher),通过 HTTP(jetty)方式请求 map task 所在的TaskTracker 获取 map task 的输出文件。因为 map task 早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2)merge
这里的 merge 如 map 端的 merge 动作,只是数组中存放的是不同map 端 copy 来的数值。Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM的 heap size 设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用。
merge 有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge。与 map 端类似,这也是溢写的过程,这个过程中如果你设置有 Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种 merge 方式一直在运行,直到没有map 端的数据时才结束,然后启动第三种磁盘到磁盘的 merge 方式生成最终的那个文件。
3)input
Reducer 的输入文件。不断地 merge 后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为 Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,后面有时间我再说。当 Reducer 的输入文件已定,整个Shuffle 才最终结束。然后就是 Reducer 执行,把结果放到 HDFS 上。
9.2 mapreduce重要设置参数
内存管理
可以通过 mapred.child.ulimit 参数配置子进程可使用的最大虚拟内存。
【
注意:该属性对单个进程设置最大限制,单位为 KB,值必须大于等于最大堆内存(通过-Xmx 设置)。
注意:mapred.child.java.opts 只对从 tasktracker 分配和管理的子 JVM 进程有效。其他 hadoop 守护进程内存参数配置详见Configuring the Environment of the Hadoop Daemons。
】
mapred.task.maxvmem
int类型 以字节为单位指定单个map 或 reduce 任务的最大虚拟内存。如果任务超过该值就被kill
mapred.task.maxpmem
int类型 以字节为单位指定单个map 或 reduce 任务的最大 RAM。这个值被调度器(Jobtracer)参考作为分配 map\reduce 任务的依据,避免让一个节点超RAM 负载使用。
Map 参数
io.sort.mb
int类型 默认100 以 MB 为单位设置序列化和元数据 buffer 的大小。
io.sort.spill.percent
float类型默认0.80 元数据和序列化数据 buffer 空间阀值。当两者任何一个 buffer 空间达到该阀值,数据将被 spill 到磁盘。
【假设io.sort.record.percent=r,io.sort.mb=x,io.sort.spill.percent=q,那么在 map 线程 spill 之前最大处理的记录量为 r*x*q*2^16。
注意:较大的值可能降低spill 的次数甚至避免合并,但是也会增加 map 被阻塞的几率。通过精确估计 map 的输出尺寸和减少 spill 次数可有效缩短 map 处理时间。】
io.sort.record.percent
float类型默认0.05 map 记录序列化后数据元数据 buffer 所占总 buffer 百分比值。为了加速排序,除了序列化后本身尺寸外每条序列化后的记录需要 16 字节的元数据io.sort.mb 值被占用的百分比值超过设定值机会发生 spill。对输出记录较少的 map,值越高越可降低
spill 发生的次数。
Shuffle/Reduce 参数
io.sort.factor
int类型默认值 10 指定同时可合并的文件片段数目。参数限制了打开文件的数目,压缩解码器。如果文件数超过了该值,合并将分成多次。这个参数一般适用于 map 任务,大多数作业应该配置该项。
子 JVM重用
可以通过指定mapred.job.reuse.jvm.num.tasks 作业配置参数来启用 jvm 重用。默认是 1,jvm 不会被重用(每个 jvm 只处理 1 个任务)。如果设置为-1,那么一个 jvm 可以运行同一个作业的任意任务数目。用户可以通过 JobConf.setNumTasksToExecutePerJvm(int)指定一个大于 1 的值。
-------------------------------------------------------------------------------------------------
附录
1. Hadoop 1.0 安装1.a1 192.168.9.1 (master)
a2192.168.9.2 (slave1)
a3192.168.9.3 (slave2)
修改/etc/hosts
2.3台机器 创建hadoop 用户
hadoop 密码:123
3.安装JDK (3台都安装)
[root@a1 ~]# chmod 777jdk-6u38-ea-bin-b04-linux-i586-31_oct_2012-rpm.bin
[root@a1 ~]#./jdk-6u38-ea-bin-b04-linux-i586-31_oct_2012-rpm.bin
[root@a1 ~]# cd /usr/java/jdk1.6.0_38/
[root@a1 jdk]# vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_25
export JAVA_BIN=/usr/java/jdk1.7.0_25/bin
export PATH=$PATH:$JAVA_HOME/bin
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
重启你的系统 或 source/etc/profile
[root@a1 ~]#/usr/java/jdk1.7.0_25/bin/java-version
java version "1.6.0_38-ea"
Java(TM) SE Runtime Environment (build1.6.0_38-ea-b04)
Java HotSpot(TM) Client VM (build20.13-b02, mixed mode, sharing)
4.安装hadoop (3台都安)
[root@a1 ~]# tar zxvf hadoop-0.20.2-cdh3u5.tar.gz-C /usr/local
编辑hadoop 配置文件
[root@a1 ~]# cd/usr/local/hadoop-0.20.2-cdh3u5/conf/
[root@a1 conf]# vi hadoop-env.sh
添加
export JAVA_HOME=/usr/java/jdk1.7.0_25
设置namenode启动端口
[root@a1 conf]# vi core-site.xml
添加
设置datanode节点数为2
[root@a1 conf]# vi hdfs-site.xml
添加
设置jobtracker端口
[root@a1 conf]# vim mapred-site.xm
[root@a1 conf]# vi masters
改为 a1(主机名)
[root@a1 conf]# vi slaves
改为
a2
a3
拷贝到其他两个节点
[root@a1 conf]# cd /usr/local/
[root@a1 local]# scp -r./hadoop-0.20.2-cdh3u5/ h2:/usr/local/
[root@a1 local]# scp -r./hadoop-0.20.2-cdh3u5/ h3:/usr/local/
在所有节点上执行以下操作,把/usr/local/hadoop-0.20.2-cdh3u5的所有者,所有者组改为hadoop并su成该用户
[root@a1 ~]# chown hadoop.hadoop/usr/local/hadoop-0.20.2-cdh3u5/ -R
[root@a2 ~]# chown hadoop.hadoop/usr/local/hadoop-0.20.2-cdh3u5/ -R
[root@a3 ~]# chown hadoop.hadoop/usr/local/hadoop-0.20.2-cdh3u5/ -R
[root@a1 ~]# su - hadoop
[root@a2 ~]# su - hadoop
[root@a3 ~]# su - hadoop
所有节点上创建密钥
[hadoop@a1 ~]$ ssh-keygen -t rsa
[hadoop@a2 ~]$ ssh-keygen -t rsa
[hadoop@a3 ~]$ ssh-keygen -t rsa
[hadoop@a1 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a1
[hadoop@a1 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a2
[hadoop@a1 ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.puba3
[hadoop@a2 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a1
[hadoop@a2 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a2
[hadoop@a2 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a3
[hadoop@a3 ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.puba1
[hadoop@a3 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a2
[hadoop@a3 ~]$ ssh-copy-id -i/home/hadoop/.ssh/id_rsa.pub a3
格式化 namenode
[hadoop@a1 ~]$ cd/usr/local/hadoop-0.20.2-cdh3u5/
[hadoop@a1 hadoop-0.20.2-cdh3u5]$ bin/hadoopnamenode -format
开启
[hadoop@a1 hadoop-0.20.2-cdh3u5]$bin/start-all.sh
在所有节点查看进程状态验证启动
[hadoop@a1 hadoop-0.20.2-cdh3u5]$ jps
8602 JobTracker
8364 NameNode
8527 SecondaryNameNode
8673 Jps
[hadoop@a2 hadoop-0.20.2-cdh3u5]$ jps
10806 Jps
10719 TaskTracker
10610 DataNode
[hadoop@a3 hadoop-0.20.2-cdh3u5]$ jps
7605 Jps
7515 TaskTracker
7405 DataNode
[hadoop@a1 hadoop-0.20.2-cdh3u5]$bin/hadoop dfsadmin -report
2. HDFS 操作与基本api编写(1)操作
创建目录
[hadoop@h101 hadoop-1.2.1]$ hadoop fs-mkdir output
列出文件
[hadoop@h101 ~]$ hadoop fs -ls
列出某个文件夹中的文件
[hadoop@h101 ~]$ hadoop fs -ls output
上传abc文件,并命名为test
[hadoop@h101 ~]$ hadoop fs -put /home/hadoop/abc test
复制文件到本地 文件系统
[hadoop@h101 ~]$ hadoop fs -get test /home/hadoop/cba
删除HDFS 中的文件
[hadoop@h101 ~]$ hadoop fs -rmr test
查看HDFS 中的文件
[hadoop@h101 ~]$ hadoop fs -cat test
报告HDFS 基本统计信息
[hadoop@h101 ~]$ hadoop dfsadmin –report
【安全模式:
NameNode在启动的时候首先进入安全模式,如果 datanode 丢失的block达到一定的比例(1-dfs.safemode.threshold.pct),则系统会一直处于安全模式状态即只读状态。 dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
】
退出安全模式
[hadoop@h101 ~]$ hadoop dfsadmin -safemodeleave
进入安全模式
[hadoop@h101 ~]$ hadoop dfsadmin -safemodeenter
(2)api
1) 环境准备:
拷贝hadoop 的jar包到java下
[root@h101 ~]# cd/usr/jdk1.7.0_25/jre/lib/ext/
[root@h101 ext]# cp/home/hadoop/hadoop-1.2.1/lib/*.jar .
[root@h101 ext]# cp/home/hadoop/hadoop-1.2.1/*.jar .
[root@h101 ~]# chmod -R 777/usr/jdk1.7.0_25/
另几个节点同样配置
把core-site.xml和hdfs-site.xml放到自己编写的java文件所在目录下
[hadoop@h101 jdk1.7.0_25]$ cp/home/hadoop/hadoop-1.2.1/conf/core-site.xml .
[hadoop@h101 jdk1.7.0_25]$ cp/home/hadoop/hadoop-1.2.1/conf/hdfs-site.xml .
2)hdfs api
A、上传文件到 hdfs中
vi CopyFile.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Pathsrc =new Path("/home/hadoop/bbb/b1");
Path dst =newPath("hdfs://h101:9000/user/hadoop");
hdfs.copyFromLocalFile(src, dst);
System.out.println("Uploadto"+conf.get("fs.default.name"));
FileStatus files[]=hdfs.listStatus(dst);
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
}B、 hdfs中创建文件
vi CreateFile.java
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("hdfs://h101:9000/user/hadoop/hellow.txt");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}C、 创建HDFS目录
vi CreateDir.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateDir {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path dfs=new Path("hdfs://h101:9000/user/hadoop/TestDir");
hdfs.mkdirs(dfs);
}
}D、 hdfs 重命名文件
vi Rename.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename{
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path frpaht=new Path("hdfs://h101:9000/user/hadoop/b1"); //旧的文件名
Path topath=newPath("hdfs://h101:9000/user/hadoop/bb111"); //新的文名
booleanisRename=hdfs.rename(frpaht, topath);
String result=isRename?"成功":"失败";
System.out.println("文件重命名结果为:"+result);
}
}D、删除hdfs 上的文件
vi DeleteFile.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("hdfs://h101:9000/user/hadoop/bb111");
boolean isDeleted=hdfs.delete(delef,false);
//递归删除
//boolean isDeleted=hdfs.delete(delef,true);
System.out.println("Delete?"+isDeleted);
}
}E、查看文件是否存在
vi CheckFile.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CheckFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path findf=newPath("hdfs://h101:9000/user/hadoop/hellow.txt");
boolean isExists=hdfs.exists(findf);
System.out.println("Exist?"+isExists);
}
}F、查看HDFS文件最好修改时间
vi GetLTime.java
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetLTime {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath =newPath("hdfs://h101:9000/user/hadoop/hellow.txt");
FileStatus fileStatus=hdfs.getFileStatus(fpath);
long modiTime=fileStatus.getModificationTime();
System.out.println("file1.txt的修改时间是"+modiTime);
}
}file1.txt的修改时间是1406749398648
****时间格式:Coordinated Universal Time(CUT) 协调世界时
G、 查看 hdfs文件
vi URLcat.java
import java.io.InputStream;
import java.net.URL;
importorg.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class URLcat{
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = newURL(args[0]).openStream();
IOUtils.copyBytes(in,System.out, 4086, false);
} finally {
IOUtils.closeStream(in);
}
}
}[hadoop@h101 jdk1.7.0_25]$/usr/jdk1.7.0_25/bin/javac URLcat.java
[hadoop@h101 jdk1.7.0_25]$
/usr/jdk1.7.0_25/bin/java URLcathdfs://h101:9000/user/hadoop/test.txt
(3)客户端和HDFS服务器端配置文件的关系
客户端的配置文件名与服务器端相同,字段名也相同
客户端不会从HDFS集群端同步配置文件
客户端只使用部分配置信息
fs.default.name
dfs.block.size
dfs.replication
如果客户端没有配置信息,则使用客户端Hadoop程序包里的缺省值
而不是服务器端的值
(4)HDFS的安全性和用户认证
缺省情况下,Hadoop不启用认证
采用客户端系统的登录用户名
或可以通过API设置
从而,虽然HDFS有权限控制,但并没有安全性可言
可以在NameNode上启用用户认证
目前只支持Kerberos
可以与LDAP集成
3.Zookeeper 的主流应用场景实现思路
配置管理
集中式的配置管理在应用集群中是非常常见的,⼀般商业公司内部都会实现一套集中的配置管理中⼼心,应对不同的应用集群对于共享各自配置的需求,并且在配置变更时能够通知到集群中的每一个机器。
Zookeeper 很容易实现这种集中式的配置管理:
(1)将 APP1 的所有配置配置到/APP1 znode 下。
(2)APP1 所有机器一启动就对/APP1 这个节点进⾏行监控(zk.exist("/APP1",true)),并且实现回调⽅方法 Watcher。
(3)在 zookeeper 上/APP1 znode 节点下数据发⽣生变化的时候,每个机器都会收到通知,Watcher ⽅方法将会被执⾏。
(4)那么应用再取下数据即可(zk.getData("/APP1",false,null))。
【以上这个例⼦子只是简单的粗颗粒度配置监控,细颗粒度的数据可以进⾏行分层级监控,这⼀一切都是可以设计和控制的。】

集群管理
应用集群中,我们常常需要让每⼀一个机器知道集群中(或依赖的其他某一个集群)哪些机器是活着的,并且在集群机器因为宕机,⽹网络断链等原因能够不在人⼯介⼊的情况下迅速通知到每⼀个机器。
Zookeeper 同样很容易实现这个功能:
(1)我在 zookeeper 服务器端有⼀一个 znode 叫/APP1SERVERS,那么
(2)集群中每⼀一个机器启动的时候都去这个节点下创建⼀一个 EPHEMERAL 类型的节点,比如 server1 创建/APP1SERVERS/SERVER1(可以使用 ip,保证不重复),server2 创建/APP1SERVERS/SERVER2,
(3)SERVER1 和 SERVER2 都 watch /APP1SERVERS 这个父节点,那么也就是这个父节点下数据或者子节点变化都会通知对该节点进行 watch 的客户端。
【因为 EPHEMERAL 类型节点有一个很重要的特性,就是客户端和服务器端连接断掉或者 session 过期就会使节点消失,那么在某一个机器挂掉或者断链的时候,其对应的节点就会消失,然后集群中所有对/APP1SERVERS 进⾏行 watch 的客户端都会收到通知,然后取得最新列表即可。】
集群选 master
一旦master 挂掉能够马上能从 slave 中选出一个master,实现步骤和前者⼀一样
(1)机器在启动的时候在 APP1SERVERS 创建的节点类型变为EPHEMERAL
_SEQUENTIAL类型,这样每个节点会自动被编号,【例如 :zookeeperTest2.java】
(2) 我们默认规定编号最小的为 master。
所以当我们对/APP1SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么 master 就被选出,⽽而这个 master 宕机的时候,相应的 znode 会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为 master,这样就做到动态master 选举。

4.Mapreduce实现WordCount算法

机器学习算法全栈工程师
一个用心的公众号

长按,识别,加关注
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助