SVM分类方法
http://blog.csdn.net/v_july_v/article/details/7624837
1
、要对特征值
Xi
进行分类,可设决策函数是所有
Xi
的函数,分类函数是这样的:

或者
f
(
x
)=
W'*x+b;W=
Σαi*yi*xi
分类函数由所有特征值
Xi
的权重
αi
和阀值
b
决定。
当f(x)>0为正确分类,f(x)=0为分类边界Optimal Hyper Plane,如下图中间红线,改变W和b可以使距分类边界最近的点f(x)=1,如下图红线两边的线,其到Optimal Hyper Plane的几何距离为1/||w||,最佳分类将使其最大,意味着分的最开。
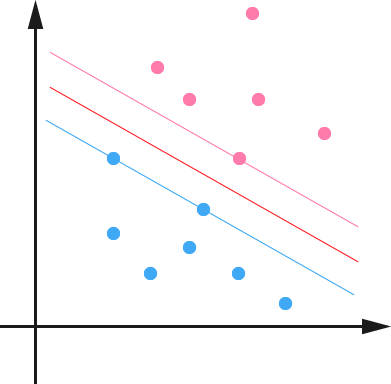
maximum margin classifier 的目标函数
通过最大化
margin
,我们使得该分类器对数据进行分类时具有了最大的
confidence
。但,这个最大分类间隔器到底是用来干嘛的呢?很简单,
SVM 通过使用最大分类间隙Maximum Margin Classifier 来设计决策最优分类超平面
,而为何是最大间隔,却不是最小间隔呢?因为最大间隔能获得最大稳定性与区分的确信度,从而得到良好的推广能力
(
超平面之间的距离越大,分离器的推广能力越好
。)
So
,对于什么是
Support Vector Machine
,我们可以先这样理解,如上图所示,我们可以看到
hyper plane
两边的那个
gap
分别对应的两条平行的线(在高维空间中也应该是两个
hyper plane
)上有一些点,显然两个超平面
hyper plane
上都会有点存在,否则我们就可以进一步扩大
gap
,也就是增大
1/||w||
的值了。这些点,就叫做
support vector
。
到底什么是
Support Vector
可以看到两个支撑着中间的 gap 的超平面,它们到中间的纯红线separating hyper plane 的距离相等,即我们所能得到的最大的 geometrical margin
γ˜ 。而“支撑”这两个超平面的必定会有一些点,而这些“支撑”的点便叫做支持向量Support Vector。
2
、
Optimal Hyper Plane:
找到距红线为
1/||w||
的
Support Vector
的点(其
f(x)=1
)后,可以看到,非
Support Vector
的点对分类没有影响,其增减都不影响
Optimal Hyper Plane
即
f(x)=0
的位置,所以非
Support Vector
的点的影响系数
αi
为
0
如何找到这个最优的
Optimal Hyper Plane?

等价于

通过给每一个约束条件加上一个 Lagrange multiplier(拉格朗日乘值):
α,我们可以将约束条件融和到目标函数里去(也就是说把条件融合到一个函数里头,现在只用一个函数表达式便能清楚的表达出我们的问题)
:
在约束条件下L(w,b,α)≤L(w,b),“=”在max()成立。
min[
然后我们令
我们现在的目标函数变成了:

这个问题和我们最初的问题是等价的。不过,现在我们来把最小和最大的位置交换一下(
稍后,你将看到,当下面式子满足了一定的条件之后,这个式子
d
便是上式
P
的对偶形式表示):

当然,交换以后的问题不再等价于原问题,这个新问题的最优值用d*来表示。并且我们有 d*<=p* ,这在直观上也不难理解,最大值中最小的一个总也比最小值中最大的一个要大吧! 总之,
第二个问题的最优值 d* 在这里提供了一个第一个问题的最优值 p* 的一个下界,在满足某些条件的情况下,这两者相等,这个时候我们就可以通过求解第二个问题来间接地求解第一个问题。
上段说
“在满足某些条件的情况下
”
,这所谓的
“
满足某些条件
”
就是要满足
KKT
条件。而什么是
KKT
条件呢?据网上给的资料介绍是
(
更多见维基百科:
KKT 条件)
。
经过论证,我们这里的问题是满足
KKT
条件的,因此现在我们便转化为求解第二个问题。也就是说,现在,咱们的原问题通过满足一定的条件,已经转化成了对偶问题。而求解这个对偶学习问题,分为两个步骤,首先要让L(w,b,a) 关于
w 和
b 最小化,
然后求对
α的极大。
(1)、首先固定
α,要让
L 关于
w 和
b 最小化,我们分别对w,b求偏导数,即令
∂
L
/∂
w 和
∂
L
/∂
b 等于零:
∂
L
∂
w
=0⇒w=∑αiyixi
∂
L
∂
b
=0⇒∑αiyi=0
带回上述的
L
:
 ,得到:
,得到:

(2)、求对α的极大,即是关于对偶变量dual variable α的优化问题
得到α后,据 ,即可求出w。然后通过
,即可求出w。然后通过 ,即可求出b
,即可求出b
求α如下:
(细心的读者读至此处,对于:“转换成求maxL(w,b,α)后怎么求α的值呢?”,可能依然心存疑惑,没关系,我告诉你,在本文文末的参考文献及推荐阅读的条目9:统计学习方法[李航著],中的第7章第7.4节、SMO-序列最小最优化算法的内有提到关于a的求解过程,读者有兴趣可以参考之)
KKT条件可参考:http://blog.csdn.net/johnnyconstantine/article/details/46335763
SMO见http://blog.csdn.net/yclzh0522/article/details/6900707
