CVPR 2020——PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation
PointGroup: Dual-Set Point Grouping for 3D Instance Segmentation
- Abstract
- (一) Introduction
- (二) Related Work
- (三) Our Method
- 3.1. Architecture Overview
- 3.2. Backbone Network
- 3.3. Clustering Algorithm
- 3.4. ScoreNet
- 3.5. Network Training and Inference
- (四)Experiments
- 4.1. Experimental Setting
- 4.2. Evaluation on ScanNet
- 4.3. Evaluation on S3DIS
- (五) Conclusion
论文:https://arxiv.org/abs/2004.01658
源码:https://github.com/Jia-Research-Lab/PointGroup
Abstract
- 介绍了PointGroup,这是一种新的端到端自下而上的体系结构,着重关注于通过探索对象之间的空隙空间更好地对点进行分组。
- 设计了一个两分支网络来提取点特征并预测语义标签和偏移量,以将每个点移向其各自的实例质心。
- 后接一个聚类,以利用原始点和偏移位移点坐标集的优势。
- 制定ScoreNet来评估候选实例,然后使用非最大抑制(NMS)来删除重复项。
- 在两个数据集ScanNet v2和S3DIS上进行了实验,获得最高的性能,分别为63.6%和64.0%。
(一) Introduction
目前存在的困难:
- 实例分割不仅需要预测语义标签,而且还需要预测场景中每个对象的实例ID。
- 卷积神经网络提高了二维实例分割的性能。但是,在无序和无结构的3D点云的情况下,不能将2D方法直接扩展到3D点,并使3D点仍然非常具有挑战性。
应用:
- 在自动驾驶,机器人导航等在室外和室内环境中的有潜在应用。
改进: 通过探索3D对象之间的空隙空间以及语义信息来更好地分割,从而解决了具有挑战性的3D点云实例分割任务。
流程:
- 利用语义分割骨架来提取描述性特征并预测每个点的语义标签。
- 采用偏移分支来学习相对偏移,以将每个点移至其各自的ground-truth实心质心。通过这种方式,可以将同一对象实例的点移向同一质心并将其收集得更近,从而可以更好地将点分组为对象并分离同一类别的附近对象。
- 借助预测的语义标签和偏移量,采用一种简单而有效的算法将点分组为聚类。
- 对于每个点,以其坐标为参考,将其与相同标签的附近点分组,然后逐步扩展该组。
- 在两个单独的通道中考虑了两个坐标集–原始点位置和那些偏移了预测偏移的位置。此过程为 “Dual-Set Point Grouping.”。 两种结果互为补充,以实现更好的性能。
- 设计了ScoreNet来评估和选择候选组。
- 最后采用非最大抑制来消除重复的预测。
贡献:
- 提出了一个名为PointGroup的自底向上3D实例分割框架,以处理具有挑战性的3D实例分割任务。
- 提出一种基于双坐标集(即原始和移动集)的点聚类方法。与新的ScoreNet一起,可以更好地分割对象实例。
- 所提出的方法在各种具有挑战性的数据集上均达到了最新水平,证明了其有效性和普遍性。
(二) Related Work
看论文吧~~
(三) Our Method
3.1. Architecture Overview
为了获得3D对象的实例级分割标签,考虑两个问题:
- 首先是分开将3D空间中的内容分成单个对象。
- 第二个是确定每个对象的语义标签。
与2D图像不同,在3D场景中不存在视图遮挡问题,散布在3D中的对象通常被空白空间自然分隔。 因此,利用3D对象的这些特征,根据语义信息将3D内容分组为对象实例。
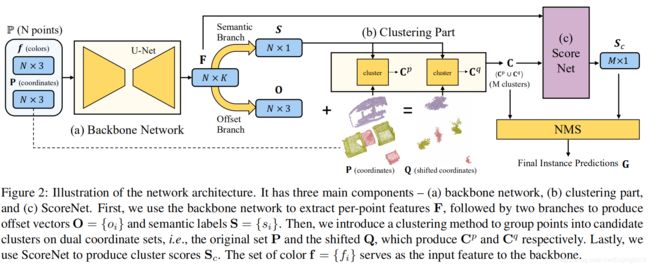
图释:
- 网络体系结构,该体系结构包含三个主要组件,即(a)骨干网,(b)聚类部分和(c)ScoreNet ;
- 骨干网的输入(a)是一个 N N N点的点集 P P P。每个点都有一个颜色 f i = ( r i , g i , b i ) f_{i}=\left ( r_{i},g_{i},b_{i}\right ) fi=(ri,gi,bi)和3D坐标 p i = ( x i , y i , z i ) p_{i}=\left ( x_{i},y_{i},z_{i}\right ) pi=(xi,yi,zi),其中 i ∈ { 1 , . . . , N } i\in \left \{1,...,N\right \} i∈{1,...,N}。
- 主干网络提取每个点的特征 F i F_i Fi, F = { F i } ∈ R N × K F=\left \{F_i\right \}\in R^{N\times K} F={Fi}∈RN×K,K是通道数。
- 将F馈入两个分支,一个分支用于语义分割,另一个分支用于预测每点偏移向量,使用两个分支生成偏移向量 O = { o i } O=\left \{o_{i}\right \} O={oi}和语义标签 S = { s i } S=\left \{s_{i}\right \} S={si}, o i = ( △ x i , △ y i , △ z i ) o_{i}=(\triangle x_{i},\triangle y_{i},\triangle z_{i}) oi=(△xi,△yi,△zi)。
- 获取语义标签后,根据对象之间的空白空间将点分组为实例簇。将彼此接近的点归为同一聚类(如果它们具有相同的语义标签)。(直接基于点坐标集 P = { p i } P = \left \{p_i\right \} P={pi}进行聚类可能无法分离在3D空间中彼此靠近的相同类别的对象并对其进行错误分组,例如,两张并排悬挂的图片墙)。
- 将学习到的偏移 o i o_{i} oi去位移点 i i i朝向其各自的实例质心,并获得位移坐标 q i = p i + o i ∈ R 3 q_i = p_i +o_i∈R^3 qi=pi+oi∈R3。
- 对于与 p i p_i pi不同的属于同一对象实例的点,偏移的坐标 q i q_i qi围绕同一质心。因此,通过基于移动的坐标集 Q = { q i } Q = \left \{q_i\right \} Q={qi}进行聚类,即使它们具有相同的语义标签,也可以更好地分离附近的对象。
- 但是,对于靠近对象边界的点,预测的偏移可能不准确。聚类算法使用“dual”点坐标集,即原始坐标 P P P和移动坐标 Q Q Q。在 P P P上进行聚类可能会将附近的同一类别的对象误分组,而在 Q Q Q上进行聚类则不会出现此问题,但可能无法处理大对象的边界点。
- 将聚类结果 C C C表示为 C p = { C 1 P , . . . , C M p p } C^{p}=\left \{C_{1}^{P},...,C_{M_{p}}^{p}\right \} Cp={C1P,...,CMpp}和 C q = { C 1 q , . . . , C M q q } C^{q}=\left \{C_{1}^{q},...,C_{M_{q}}^{q}\right \} Cq={C1q,...,CMqq}的并集,分别是基于 P P P和 Q Q Q发现的聚类。 M p M_p Mp, M q M_q Mq分别表示 C p C_p Cp和 C q C_q Cq中的簇数, M = M p + M q M = M_p+M_q M=Mp+Mq表示总数。
- 构建ScoreNet(c)处理点聚类 C = C p ∪ C q C =Cp∪Cq C=Cp∪Cq,并为每个聚类生成一个聚类得分 S c S_c Sc。
- 将NMS应用于具有分数的提案,以生成最终实例预测。
- 将实例预测表示为 G = { G 1 , . . . , G M p r e d } ⊆ C G=\left \{G_{1},...,G_{M_{pred}}\right \}\subseteq C G={G1,...,GMpred}⊆C,实例 ground-truth 表示为 I = { I 1 , . . . , I M g t } I=\left \{I_{1},...,I_{M_{gt}}\right \} I={I1,...,IMgt}, G i G_i Gi和 I i I_i Ii是 P P P的子集, M p r e d M_{pred} Mpred和 I i I_{i} Ii代表 G G G和 I I I中实例数量, N i I N_i^I NiI和 N i G N_i^G NiG代表 I i I_i Ii和 G i G_i Gi中点数。
3.2. Backbone Network
首先对这些输入点进行体素化,并构建具有子流形稀疏卷积(SSC)和稀疏卷积(SC)的U-Net。然后,从体素中恢复点以获取逐点特征。 U-Net可以很好地提取上下文和几何信息,该U-Net为以后的处理提供了可区分的逐点特征 F F F。可以使用任何点特征提取网络作为骨干网(图2(a))。
Semantic Segmentation Branch.
- 将 M L P MLP MLP应用于 F F F,以针对 N N N个类上的 N N N个点生成语义评分 S C = { s c 1 , . . . , s c N } ∈ R N × N c l a s s SC=\left \{sc_{1},...,sc_{N}\right \}\in R^{N\times N_{class}} SC={sc1,...,scN}∈RN×Nclass;
- 通过交叉熵损失 L s e m L_{sem} Lsem来对结果进行正则化;
- 预测的语义标签 s i s_i si对于点 i i i是得分最高的类别,即 s i = a r g m a x ( s c i ) s_i= argmax(sc_i) si=argmax(sci)。
Offset Prediction Branch.
偏移分支对 F F F进行编码,以生成 N N N个点的 N N N个偏移矢量 O = { o 1 , . . . , o N } ∈ R N × 3 O=\left \{o_{1},...,o_{N}\right \}\in R^{N\times 3} O={o1,...,oN}∈RN×3。对于属于同一实例的点,我将它们的学习偏移量通过 L 1 L_1 L1回归损失约束为:
L o _ r e g = 1 ∑ i m i ∑ i ∥ o i − ( c ^ i − p i ) ∥ ⋅ m i − − − − − − − − ( 1 ) L_{o\_reg}=\frac{1}{\sum_{i}^{ }m_{i}}\sum_{i}^{}\left \| o_{i}-(\hat{c}_{i}-p_{i})\right \|\cdot m_{i}--------(1) Lo_reg=∑imi1i∑∥oi−(c^i−pi)∥⋅mi−−−−−−−−(1)
注释:
- m = { m 1 , . . . m N } m=\left \{m_{1},...m_{N}\right \} m={m1,...mN}是二进制掩码。如果点 i i i在实例上,则 m i = 1 m_i = 1 mi=1;否则, m i = 0 m_i = 0 mi=0。
- c ^ i \hat{c}_{i} c^i是点 i i i所属实例的质心
c ^ i = 1 N g ( i ) I ∑ j ∈ I g ( i ) P j − − − − − − − − ( 2 ) \hat{c}_i=\frac{1}{N_{g(i)}^{I}}\sum_{j\in _{Ig(i)}}^{}P_{j}--------(2) c^i=Ng(i)I1j∈Ig(i)∑Pj−−−−−−−−(2)
注释:
- g ( i ) g(i) g(i)将点 i i i映射为其对应的真实实例的索引,即包含点i的实例。
- N g ( i ) I N_{g(i)}^{I} Ng(i)I是实例 I g ( i ) I_{g(i)} Ig(i)中的点数。
注意:
- 上述机制看起来类似于VoteNet 中的投票产生策略。但是,不是根据几个子采样种子点的投票对边界框进行回归,而是预测每个点的偏移矢量来收集公共实例质心周围的实例点,以便更好地将相关点聚类到同一实例中。
发现:
- 从点到其实例质心的距离通常具有较小的值(0到1m)。

图释:
- 3b给出了ScanNet数据集中此类距离分布的统计分析。
发现:
- 考虑到不同类别的不同对象大小,网络很难回归精确的偏移量,尤其是对于大型对象的边界点,因为这些点距离实例质心相对较远。
解决方案:
- 制定方向损失来约束预测偏移向量的方向。将损耗定义为减去余弦相似度的一种方法,即:
L o _ d i r = − 1 ∑ i m i ∑ i o i ∥ o i ∥ 2 ⋅ c ^ i − p i ∥ c ^ i − p i ∥ 2 ⋅ m i − − − − − − − ( 3 ) L_{o\_dir}=-\frac{1}{\sum_{i}^{}m_{i}}\sum_{i}^{}\frac{o_{i}}{\left \| o_{i}\right \|_{2}}\cdot \frac{\hat{c}_{i}-p_{i}}{\left \| \hat{c}_{i}-p_{i}\right \|_{2}}\cdot m_{i}-------(3) Lo_dir=−∑imi1i∑∥oi∥2oi⋅∥c^i−pi∥2c^i−pi⋅mi−−−−−−−(3)
损失与偏移矢量范数无关,并确保了点朝其实例质心移动。
3.3. Clustering Algorithm
给定预测的语义标签和偏移量矢量,通过聚类算法将输入点分组为实例。算法1:

表释:
- 对于点 i i i,将半径r的球内的点以 x i x_i xi(点i的坐标)为中心,并将具有与点i相同的语义标签的点归为同一簇。
- r用作聚类中的空间约束,因此不会对距离大于r的两个类别内对象进行分组。
- 使用广度优先搜索将同一实例的点分组为一个群集。
- 对于场景中的点,可以在聚类之前并行找到r球体内的相邻点以提高速度。
3.4. ScoreNet
输入: 一组候选聚类 C = { C 1 , . . . , C M } C=\left \{C_{1},...,C_{M}\right \} C={C1,...,CM}
- M M M表示候选聚类的总数
- C i C_i Ci代表第i个聚类
- N i N_i Ni代表 C i C_i Ci中的点数。
目标: 预测每个聚类的得分,以便可以在NMS中精确保留更好的聚类。
图释:
- 对于每个聚类,从 F ∈ R N × K F∈R^{N×K} F∈RN×K(由主干网络提取的特征)中收集点特征,对于聚类 C i C_i Ci形成 F C i = { F h ( C i , 1 ) , . . . , F h ( C i , N 1 ) } F_{C_{i}}=\left \{F_{h(C_{i},1)},...,F_{h(C_{i},N_1)}\right \} FCi={Fh(Ci,1),...,Fh(Ci,N1)}。
- h h h映射 C i C_i Ci中的点索引到 P P P中对应的点索引。
- 用 P C i = { p h ( C i , 1 ) , . . . , p h ( C i , N 1 ) } P_{C_{i}}=\left \{p_{h(C_{i},1)},...,p_{h(C_{i},N_1)}\right \} PCi={ph(Ci,1),...,ph(Ci,N1)}表示 C i C_i Ci中点的坐标。
- 采用 F C i F_{C_i} FCi和 P C i P_{C_i} PCi作为初始特征和坐标,并像在骨干网开始时一样对聚类进行体素化。
- 每个体素的特征均与该体素中点的初始特征进行平均池化。
- 将它们输入带有SSC和SC的小型U-Net中,以进一步编码功能。
- 最大池化,对于每个聚类产生单个聚类特征向量 f C i ∈ R 1 × K c f_{C_i}∈R^{1×Kc} fCi∈R1×Kc。
- 最终聚类得分 S c = { s 1 c , . . . , s M c } ∈ R M S_c = \left \{s_1^c,...,s_M^c\right \}∈R^M Sc={s1c,...,sMc}∈RM表示为:
S c = S i g m o i d ( M L P ( F C ) ) − − − − − − − ( 4 ) S_c=Sigmoid(MLP(F_C))-------(4) Sc=Sigmoid(MLP(FC))−−−−−−−(4)其中 F c = { f C 1 , . . . , f C M } ∈ R M × K c F_{c}=\left \{f_{C_{1}},...,f_{C_M}\right \}\in R^{M\times K_{c}} Fc={fC1,...,fCM}∈RM×Kc
为了保证分数中聚类的质量,使用软标签代替二进制0/1标签来监督预测聚类得分,
s i ^ c = { 0 i o u i < θ l 1 i o u i > θ h 1 θ h − θ l ⋅ ( i o u i − θ l ) o t h e r w i s e − − − − − − − − ( 5 ) \hat{s_i}^{c}=\left\{\begin{matrix} 0 & iou_{i}< \theta _{l}\\ 1 & iou_{i}> \theta _{h}\\ \frac{1}{\theta _{h}-\theta _{l}}\cdot (iou_i-\theta _{l}) & otherwise\end{matrix}\right.--------(5) si^c=⎩⎨⎧01θh−θl1⋅(ioui−θl)ioui<θlioui>θhotherwise−−−−−−−−(5)
- θ l \theta _{l} θl和 θ h \theta _{h} θh分别设置为0.25和0.75,
- i o u i iou_i ioui是簇 C i C_i Ci和真实实例之间最大的联合交集(IoU):
i o u i = m a x ( { I o U ( C i , I j ) ∣ I j ∈ I } ) − − − − − − − ( 6 ) iou_i=max\left ( \left \{IoU(C_i,I_j)|I_j\in I\right \}\right )-------(6) ioui=max({IoU(Ci,Ij)∣Ij∈I})−−−−−−−(6)
使用二元交叉熵损失作为得分损失:
L c _ s c o r e = − 1 M ∑ i = 1 M ( s i ^ c l o g ( s i c ) + ( 1 − s i c ) l o g ( 1 − s i c ) ) − − − − − − ( 7 ) L_{c\_{score}}=-\frac{1}{M}\sum_{i=1}^{M}(\hat{s_i}^{c}log(s_{i}^{c})+(1-s_{i}^{c})log(1-s_{i}^{c}))------(7) Lc_score=−M1i=1∑M(si^clog(sic)+(1−sic)log(1−sic))−−−−−−(7)
3.5. Network Training and Inference
Training.
总损失为:
L = L s e m + L o _ d i r + L o _ r e g + L o _ s c o r e − − − − − − − − − ( 8 ) L=L_{sem}+L_{o\_dir}+L_{o\_reg}+L_{o\_score}---------(8) L=Lsem+Lo_dir+Lo_reg+Lo_score−−−−−−−−−(8)
Inference.
- 使用预测分数 S c S_c Sc对聚类 C C C进行NMS,以获得最终实例预测 G ⊆ C G⊆C G⊆C。
- 将IoU阈值设置为0.3。
- 由于基于语义信息进行聚类,因此聚类的语义标签是聚类所指的类别。
(四)Experiments
4.1. Experimental Setting
Datasets
- ScanNet v2
- S3DIS
Evaluation Metrics
- 平均精度(mAP)
- A P 25 AP_{25} AP25和 A P 50 AP_{50} AP50分别表示将IoU阈值设置为25%和50%时的AP分数
- AP将IoU阈值设置为50%至95%(步长为5%)对得分进行平均。
Implementation Details
- 体素大小设置为0.02m。
- 在聚类部分,将聚类半径设置为0.03m,最小聚类点数 N θ N_θ Nθ为50。
- 基本学习率为0.001的Adam。
- 由于GPU内存的限制,对于数据集中的每个场景,将最大点数设置为250k。
- 如果场景中的点数超过25万,将随机裁剪部分场景,并根据裁剪区域中的点数逐渐调整裁剪大小.
- 在测试过程中,无需裁剪,将整个场景馈入网络。
- S3DIS中的场景具有较高的点密度。有些场景甚至具有数百万个点。因此,对于每个S3DIS场景,在每次裁剪之前随机地采样1/4点。
4.2. Evaluation on ScanNet
4.2.1 Benchmark Results

表释:
- PointGroup达到了63.6%的最高 A P 50 AP_{50} AP50得分,超过了以前的所有方法。
- 与以前的最佳解决方案相比,后者获得54.9%的 A P 50 AP_{50} AP50分数,论文结果是高出8.7%(绝对),15.8%(相对)。
- 对于每个类别的详细结果,PointGroup在18个类别中的13个类别中排名第一。
4.2.2 Ablation Studies
任务: 对ScanNet验证集进行消融研究,以分析PointGroup中的设计和参数选择。
Clustering based on Different Coordinate Sets
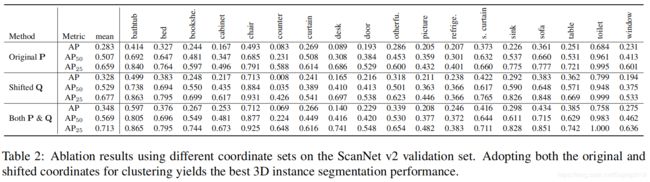
表释:
- 显示了仅使用原始坐标 P P P,仅使用移动坐标 Q Q Q以及 P P P和 Q Q Q进行的比较。
- 仅靠 P P P聚集点可能会将具有相同语义标签的两个近距离对象误分组为同一实例。因此,对于两个对象可能非常接近的类别(例如椅子和图片),仅在P上的聚类效果不佳。
- Q上的聚类部分地通过在实例质心周围收集实例点并扩大聚类之间的空间来解决该问题。但是,由于偏移量预测的不精确性,特别是对于大对象(例如,窗帘和柜台)的边界点,仅靠Q进行聚类并不能完美地执行。
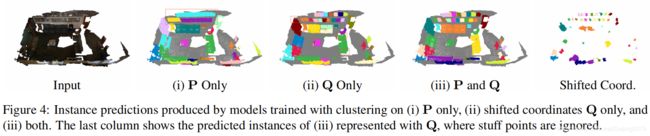
图释:
- 图4显示了使用不同坐标集的簇训练的模型的定性结果-(i)仅P,(ii)仅Q,以及(iii)P和Q。
- (i)中的问题是错误地将图片分组在墙上。
- (ii)的情况成功地将图片分成了单独的实例。然而,它在物体边界区域周围遭受误差。
- (iii)的情况同时具有(i)和(ii)的优势。获得最佳性能。
Ablation on the Clustering Radius r r r
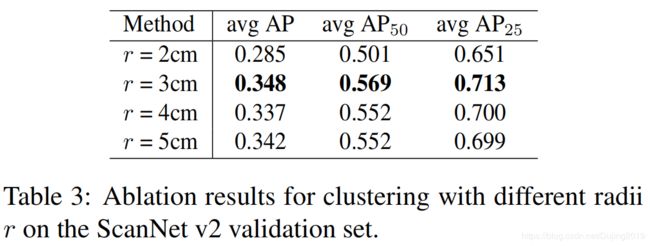
表释:
- 在聚类算法中使用不同的 r r r值。
- 较小的 r r r对点密度敏感。扫描对象在不同部分可能具有不一致的点密度。具有这样的 r r r的聚类可能无法在低密度部分中增长。
- 相反,较大的 r r r增加了将两个附近相同类别的对象归为一个的风险。
- 最终将 r r r设置为0.03(米)。
Ablation for the ScoreNet
表释:
- 消融ScoreNet,用于评估每个候选聚类的质量。
- 直接使用ScoreNet的输出评分对实例进行排名,以计算AP。
- 另一种方法是直接将实例内相关实例类别的平均语义概率用作置信度。这样,AP / AP50 / AP25的结果为30.2 / 51.9 / 68.9(%),比ScoreNet的结果为34.8 / 56.9 / 71.3(%)差。这表明ScoreNet通过为NMS提供准确的分数对于改善实例分割结果至关重要且必不可少。
4.2.3 Runtime Analysis
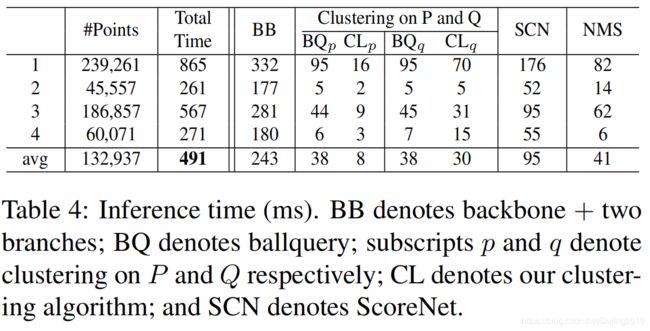
表释:
- 运行时间取决于点数和场景复杂性。
- 从ScanNet v2验证集中随机采样了四个场景,并在Titan Xp GPU上对其进行了100次测试,以获得每个场景的平均运行时间。
- Q上(移位)的时间通常比P上(原始)聚类的时间更长,因为移位的点可能具有更多的邻居。
4.3. Evaluation on S3DIS

表释:
- 使用0.2的得分阈值来删除一些低置信度聚类。
- 对于第5区的结果,PointGroup在 A P 50 AP_{50} AP50上获得57.8%,在 m P r e c 50 mPrec_{50} mPrec50(平均精度)上获得61.9%,在 m R e c 50 mRec_{50} mRec50(平均召回率)上获得62.1%。 m P r e c 50 mPrec_{50} mPrec50和 m R e c 50 mRec_{50} mRec50分别比ASIS 高6.6和19.7点。
- 对于6倍交叉验证的结果,关于 A P 50 AP_{50} AP50,PointGroup比SGPN 高9.6点,这是一个很大的差距。 m P r e c 50 mPrec_{50} mPrec50和 m R e c 50 mRec_{50} mRec50得分比第二好的解决方案高4和21.6点。
可视化图:
(五) Conclusion
- 提出用于3D实例分割的PointGroup,侧重通过探索对象实例之间的空间和点语义标签来更好地对点进行分组。
- 考虑到两个类别内对象可能彼此非常接近的情况,设计了一个两分支网络以分别学习点语义标签和点偏移向量,以将每个点移向其各自的实例质心。
- 基于原始点坐标和偏移位移的点坐标对点进行聚类。结合了两个坐标集的互补优势,以优化点分组精度。
- 引入了ScoreNet来学习评估生成的候选聚类,然后引入NMS以避免重复,再输出最终的预测实例。
- PointGroup取得了最好的精度。