50、流式音视频之一(应用层)
引言
- Web 应用和移动Web 并不是网络应用领域中唯一令人振奋的发展。对许多人来说,音频和视频才是网络的圣杯。虽然至少从20 世纪70 年代开始就有了通过Internet 发送音频和视频的想法,但大约自2000 开始实时音频( real-time audio )和实时视频( real-time video )流量才有了真正极度的增长。实时流量与Web 流量有很大的不同,它必须以预先设定的速率播放才有用。毕竟,观看一个忽停忽动的慢动作视频不是大多数人的乐趣。相反, Web 可以有短暂的中断,而且页面加载可以花费更多或更少的时间,在一定限度内这不是一个主要的问题。
- 由于有足够的带宽来承载音频和视频,那么设计音视频流和视频会议应用的关键问题就是网络的延迟。音频和视频需要实时演示,这意味着它们必须以预定速率播放出来才有用。长延迟意味着应该互动的呼叫不再能互动得起来。这个问题是很清楚的,如果你曾经用过卫星电话就应该有所体会,当延迟达到半秒钟时相当的令人分散注意力。在网络上播放音乐或电影,绝对的延迟并不要紧,因为它仅仅影响到媒体何时开始播放。但延迟的变化一一称为抖动,仍然非常重要。抖动必须被播放器掩盖,否则播放出来的音频令人难以理解,播放出来的视频则会看上去很生涩或呆滞。
- 在本节中,我们将讨论如何处理延迟问题的某些策略,以及用来设置音频和视频会话的协议。在介绍完数字音频和视频后,我们的介绍将分成三种情况,分别采用了不同的设计。第一,也是最简单的情况是如何处理存储的流媒体,就像观看YouTube 上的视频一样。接下来的一种情况难度适中,就是如何处理流媒体直播。流媒体直播有两个例子,分别是Internet 广播和IPTV,其中广播电台和电视台通过Internet 给许多用户进行直播。最后,也是最困难的情况是如何处理Skype,或者更普遍的交互式音频和视频会议呼叫。
- 顺便说一句,多媒体( multimedia )这个术语经常出现在Internet 的上下文中,它意味着视频和音频。从字面上看,多媒体是两个或两个以上的媒体。按照这个定义,这本书就是一个多媒体范例,因为它包含了文字和图形(数字)。然而,这可能不是你心目中的多媒体,因此我们使用“多媒体”一词意味着两个或两个以上的连续媒体( continuous media),也就是说,媒体必须以某种良好定义的时间间隔播放。两个媒体通常指有音频的视频,也就是说,有声音的移动图像。许多人把单纯的音频称为多媒体,比如Internet 电话或Internet广播,这显然不是很恰当。其实,所有这些情况下应该使用的一个更好术语是流媒体( streaming media)。尽管如此,我们跟随大流,把实时音频也当作多媒体来考虑。
1、数字音频
- 音频(声音)波是一种一维声(压力〉波。当声波进入耳朵时,鼓膜发生振动,从而引起内耳的微细感骨与之一起振动,并向大脑发送神经脉冲。听者感觉到的这些脉冲就是声音。类似的方式是当声波碰击麦克风时,麦克风产生一个电信号,该电信号将声音振幅表示为时间的函数。
- 令人惊讶的是人耳对于持续时间仅仅几毫秒的声音变化也异常的敏感。相反地,眼睛却察觉不到持续时间为几毫秒的光度变化。这种观察的结果是多媒体播放中仅仅几毫秒的抖动对于可感觉到的声音质量的影响,要远远大于对可感觉到的图像质量的影响。数字音频是声波的数字表示,这种表示能重现音频。通过模数转换器( ADC, Analog Digital Converter )可以将音频波转换成数字形式。ADC 以电压作为输入,生成一个二进制数作为输出。在图a中,我们看到一个正弦波的例子。为了用数字方式来表示该信号,我们可以每隔∆T 秒对它采样一次,如图(b)中的坚条状所示。如果一个声波不是纯正弦波,而是若干正弦波的线性叠加,并且其中最高的频率成分为f,根据尼奎斯特定理,以2f 的频率对该信号采样足够了。更高的采样频率没有意义,因为更高采样获得的更高频率这里无法检测出来。
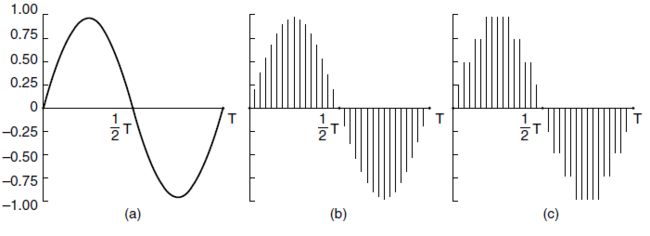
- 相反的过程是获取数字值并且产生一个模拟电压。这个过程由数模转换器(DAC,Digital-to-Analog Converter )来完成。然后,扬声器将模拟电压转换成声波发送出去,因此人们就能听到声音了。数字采样永远不可能做到精确。图2(c)中的样值只允许9 个值,从-1.00~+ 1.00,步长为0.250 一个8 位的采样允许有256 个不同的值。二个16 位的采样可以有65 536 个不同的值。由于每个采样值的位数有限而引入的误差称为量化噪声(quantization noise )。如果量化噪声太大,人耳就能觉察得出来。
- 使用声音采样技术的两个众所周知例子是电话和音频压缩光盘( CD, compact disc )。电话系统使用的脉冲编码调制,以每秒8000 次的频率采样,并用8 位表示采样值。为了最小化感觉到的失真,量化尺度是非线性的:而且限定在每秒只有8000 采样,任何高于4 kHz的频率都将被丢弃。在北美和日本,采用了μ-1 规则编码技术;在欧洲和国际上则广泛采用A-1 规则编码技术。每种编码技术的数据率都是64 000 bps 。
- 音频CD 是数字化的,其采样率为每秒44100 次,这足以捕获高达22 050 Hz 的频率。每个样值都用16 位表示,并且在振幅范围内量化尺度是线性的。但是请注意, 16 位样值只有65 536 个不同的值,甚至人耳可识别的动态声音范围大约为100 万。因此,纵使CD 质量的音频远远好于电话质量的音频,但如果每个样值仅使用16 位,因而引入了一定的量化噪声(尽管CD 并没有覆盖整个动态范围一一CD 不应该会刺伤或刺痛人耳)。一些狂热的音乐发烧友还是喜欢33-RPM的LP 唱片比CD 更多一些,因为唱片没有截取22kHz 的尼奎斯特频率,而且没有量化噪声(但必须非常小心放置,否则会有划痕)。在每秒44100 个来样并且每个样值16 位的情况下,无压缩的CD 质量音频单声道需要705.6 kbps 的带宽,立体声则需要1.411 Mbps 的带宽。
音频压缩
- 为了减少带宽需求和传输时间,音频往往被进行了压缩处理,即使音频数据率比视频数据传输速率要低得多。所有的压缩系统需要两种算法:一种用在源端上压缩数据,另一种用在接收方上解压数据。在文献中,这些算法分别称为编码( encoding )算法和解码(decoding )算法。
- 压缩算法表现出一定的不对称性,理解这点非常重要。我们首先考虑音频,这种不对称性对于视频也是适用的。对于许多应用程序来说,多媒体文件只被编码一次(当它存储在多媒体服务器上时),但将被解码几千次(每当被客户播放时)。这种不对称性意味着,编码算法较慢而且需要昂贵的硬件是可以接受的,只要解码算法速度快而且不需要昂贵的硬件。一个流行音频(或视频)服务器的运营商可能会很乐意买一个计算机集群,来为它的整个数字图书馆编码,但如果要求客户做同样的事情才能听到音乐或看到电影,那么该运营商恐怕不会成功。许多实用的压缩系统竭尽全力使得解码算法既快速又简单,甚至以编码算法缓慢而且复杂性高作为代价。
- 另一方面,对于直播的音频和视频,比如IP语音呼叫,缓慢的编码是不可接受的。编码必须实时地动态执行。因此,相比存储在磁盘上的音频或视频,实时多媒体使用不同的算法或参数,往往适当减少压缩。第二个不对称性在于编码/解码过程不必是可逆的。也就是说,压缩数据文件、传输、然后解压缩它,用户期望得到原始的准确的数据,直到最后一位数据。对于多媒体而言,这一要求并不一定存在。音频(或视频)信号经过编码,然后再被解码,得到的信号与原始的略有不同,这通常是可以接受的,只要它听起来(或看起来)和原始的一样即可。当解码输出的信号不完全等同于原始输入的信号,就说该系统是有损耗的。如果输入和输出完全相同,则该系统就是无损的。有损系统很重要,因为接受少量信息的丢失,通常意味着在可能的压缩率方面能获得巨大的回报。
- 从历史上看,电话网络中的长途带宽非常昂贵,所以工作中需要一个坚实的声码器(是“语音编码器”的简称),声码器( vocoder)负责为特殊语音进行压缩音频。人的讲话往往在600~6000Hz 范围内,由一个机械过程产生:这个过程取决于讲话人的声道、舌头和下顿。一些声码器利用发声系统的模型来减少语音,只需要使用几个参数(例如,各种腔的大小和形状)和低至2.4 kbps 的数据传输速率。然而,这些声码器是如何工作的超出了本书的范围,这里不再赘述。
- 我们主要关注通过Internet 发送音频,一种通常接近CD 音质的音频。通过Internet 发送时必须减少这种音频的数据传输速率。1.411 Mbps 的立体声音频会占用许多宽带链路,给视频和其他Web 流量留下的余地很少。音频压缩后的数据率可降低一个数量级,而用户几乎感觉不到音质的损失。压缩和解压需要对信号进行处理。幸运的是,数字化的声音和电影可以很容易由计算机的软件处理。这种技术的应用己经导致了大量的音乐和电影可以通过Internet 唾手可得一一当然,并不是所有这些都是合法的一一因此,这又导致了许多来自艺术家和版权拥有人的诉讼。
- 许多音频压缩算法中,可能最流行的格式是MPEG 音频层3 (MP3, MPEG audio layer 3 )和高级音频编码(AAC, Advanced Audio Coding ),后者是由MP4 (MPEG-4)文件给出的。为了避免混淆,需要注意的是MPEG 提供了音频和视频压缩。MP3 是指MPEG-1 标准中的音频压缩部分(第三部分〉,而不是第三个版本的MPEG 。事实上,没有发布过MPEG 的第三个版本,只有MPEG-1 、MPEG-2 和MPEG-4 。AAC 是MP3 的继任者,也是MPEG-4 中使用的默认音频编码。MPEG-2 允许MP3 和AAC 音频。
- 音频压缩可以通过两种方式完成。在波形编码( waveform coding )中,它通过傅里叶变换,将信号数学地转换成频率分量。然后以最小的方式对每个分量的强度进行编码。这样做的目标是尽可能在另一端以尽可能少的位数重现该波形。另一种方式称为感知编码(perceptual codhtg ),它利用了人类听觉系统中的某些特定缺陷来对信号进行编码,即使通过示波器观察到的信号与原信号有相当大的差异,但在人耳听起来还是一样的。感知编码方法建立在心理声学( psychoacoustics )的基础上,即人类是如何感觉到声音的。MP3 和AAC 都是基于感知编码的。
- 感知编码的关键特性是某些声音可以屏蔽( mask )其他声音。请想象在一个温暖的夏日里,你正在现场直播一场长笛音乐会。然后,突然间,附近的一群工人打开他们的手提电钻开始在街道上施工。于是,没有人能够听得到长笛的声音。长笛的声音被手提电钻完全屏敲了。如果仅仅考虑传输的话,则只需对手提电钻所使用的频段进行编码就足够了,因为听众反正也听不到长笛的声音。这种情形称为频率屏蔽(frequency masking )一一某一频段中较大的声音隐藏了另一个频段中较柔和的声音,这种能力即为频率屏蔽。事实上,即使手提电钻停下来,也有很短的一段时间听不到长笛的声音,因为当手提电钻工作的时候耳朵降低了它的增益,它需要一段有限的时间再次提高增益。这种效果称为暂时屏蔽(temporal masking )。
- 要使这些效果更明显,请想象做实验1 。一个人在一个安静的房间里,戴着一个连接到计算机声卡的耳机。计算机生成一个较弱的100Hz 的纯正弦波信号,然后逐渐增加功率。下达的科目要求他听到声音的时候就敲击一个键。计算机记录下此时的功率值,然后用200Hz、300Hz 和其他所有人类力听范围以内的频率重复这个实验。把多个人的数据进行平均,从而得到了如图(a)所示的一个对数( log-log )图,它表示一个音调被人耳听见需要多少功率。根据图中的曲线,可以直接得出的一个结论是永远不需要对一个功率低于可听度阈值的频率进行编码。例如,在图中。如果100 Hz 的功率是20 dB , 那么可以在输出中省略掉它而不会产生可感觉的品质损失,因为在100Hz 频率上20dB 低于可听度水平。

- 现在考虑实验2。计算机再次运行实验1 ,但这次在测试频率上叠加了一个固定振幅的正弦波,它的频率是150Hz 。我们发现,在150Hz 附近频率的可听度阈值增加了,如图(b)所示。这次新观测的结果是记录下哪些信号被附近频段中更强的信号所屏蔽,然后在编码信号时省略掉这些越来越多的频率,从而节省数据位。在图中, 125 Hz 的信号可以在输出中被完全省略,而且没有人能够听得出差异来。在某个频段中,即使当一个功率较强的信号停止以后,考虑到它的暂时屏蔽特性,我们可以继续省略被屏蔽掉的频率一段时间〈即耳朵恢复听力的时间〉。MP3 和AAC 的本质就是对声音进行傅里叶变换以便得到每个频率处的功率,然后只传输未被屏蔽的频率,并且用尽可能少的位数对它们进行编码。
- 有了这个信息作为背景,我们现在可以来看编码是如何完成的。音频压缩是以8~96的来样率对波形进行采样,以此模仿CD音质的声音, 一般的来样率为44.1 kHz采样可以对一个信道(单声道〉或两个〈立体声)信道进行。下一步要选择输出比特率。MP3 可以将一个立体声摇滚乐光盘压缩到96 kbps,带来感官上的音质损失很小,甚至摇滚乐迷也听不大出来。对于一场钢琴音乐会,至少需要128 kbps 的AAC 。这两种情况下需要的比特率之所以不同的原因在于摇滚乐的信号信噪比要比钢琴演奏会的信噪比高得多〈无论如何这是工程上的意义〉。它也可以选择较低的输出率,并且接受某些质量上的损失。
- 采样值以小批量的形式处理。每个批次的信号通过一排数字滤波器以便获得频段。接着频率信息再被送入一个心理声学模型, 目的是确定屏蔽掉的频率;然后,对可用比特在频段之间进行划分:给具有最大频谱功率的无屏蔽频段分配更多的比特,给具有小频谱功率的无屏蔽频段分配较少的比特,不给任何被屏蔽的频段分配任何比特。最后,使用Huffnan 编码算法对比特进行编码,给经常出现的数字分配短码,给那些不经常发生的数字分配长码。
2、数字视频
- 人类的眼睛有个特点,当一幅图像出现在视网膜上时,图像在退化之前会在视网膜上停留数毫秒。如果一个图像序列以每秒50 幅的速率出现,眼睛是不会注意到这些图像是离散的。所有视频系统正是利用了这个原理来产生动画效果的。视频最简单的数字表示法是一个帧序列,每个帧包含一个由图像元素或者像素( pixel)组成的矩形网格。每个像素可以是一个单独的位,表示黑或者白。然而,这样一个系统的质量极差。
- 接下来,每个像素用8 位来表示256 个灰度级。这种方案可以表示高质量的黑白(black-and-white )视频。对于彩色视频,许多系统使用8 位来表示红、绿和蓝(RGB )三原色中的每一个分量。这种表示法是可能的,因为任何一种颜色可以通过线性叠加适当强度的红、绿、蓝构造出来。每个像素用24 位来表示,就有大概1600 万种颜色,远远超出了人类眼睛可以识别的范围。
- 在彩色LCD 计算机显示器和电视机上,每个离散的像素是由紧密排列的红色、绿色和蓝色子像素组成的。帧由子像素的强度来显示,而眼睛混合了颜色分量。常见的帧速率是24 帧/秒(继承自35 毫米的电影胶片)、30 帧/秒(取自NTSC 美国电视)和25 帧/秒(取自几乎全世界都在用的PAL 电视系统)。(对于真正的挑剔者来说, NTSC彩色电视的确切运行速率是29.97 帧/秒。最原始的黑白系统以30 帧/秒速率运行,但在引入颜色时,工程师需要一点额外的带宽作为信令,所以他们将帧速率减少到29.97 。NTSC制式的视频在计算机上真正使用的帧速率还是30 )。PAL 制式在NTSC 之后被发明出来,实际使用25.000 帧/秒。为了使得这个故事看起来更完整,还有第三个系统,即法国、法属非洲和东欧使用的SECAM。它是由当时的共产主义东德引进到东欧的,因此东德人无法观看西德( PAL )电视,以免他们得到不好的想法。但是现在许多东欧国家正在往PAL 制式切换。
- 事实上,对于广播电视而言,用25 帧/秒的速率来播放流畅的动作效果还不够好,因此图像被分割分为两个域(field ),一个由奇数扫描线构成,另一个由偶数扫描线构成。两个域(一半的分辨率)按顺序播放,给出接近60 (NTSC) /秒或确切地50 (PAL )域/秒的速率,这样的一个系统就称为隔行扫描( interlacing )。在计算机上观看的视频是渐进的(progressive ),也就是说不使用隔行扫描,因为计算机显示器在图形卡上有个缓冲区,可使得CPU 以30 次/秒的速率将新图像放入缓冲区中,但图形卡以50 或者甚至100 次/秒的速率重绘屏幕来消除闪烁。模拟电视机没有像计算机那样的帧缓冲区。当快速运动的隔行扫描视频显示在计算机上时,在阴影边缘能隐约看到短的水平线,这就是称为榄理(combing )的效果。
- 通过Internet 发送视频的帧的大小差异很大,个中的原因很简单,因为较大的帧需要更多的带宽,而这个要求可能并不总能满足。低分辨率的视频可能只有320 × 240 像素,“全屏”视频是640 × 480 像素。这些尺寸分别近似于早期的计算机显示器和NTSC 电视。宽高比为4:3 ,与标准电视一样。高清晰电视( HDTV,High-Definition Tele Vision )视频可下载为1280 × 720 像素。这些“宽屏”图像的宽高比为16: 9 ,更加接近电影的3: 2 宽高比。相比之下,标准的DVD 视频通常是720 × 480 ,蓝光光盘的视频通常是高清1080 × 720 。在Internet 上,像素的数目仅是故事的一部分,因为媒体播放器可以不同的大小来表示相同的图像。视频只是在计算机屏幕上的另一个窗口,它可以被拉大或缩小。像素越多,其作用是提高了图像质量,所以当它被扩大时看起来并不模糊。然而,许多显示器可以显示甚至比HDTV 更多的像素图像(和视频)。
视频压缩
- 即使是标准质量的视频,即帧具有640 × 480 像素、每个像素有24 位的颜色信息、播放速率为30 帧/秒,这样的视频也需要超过200 Mbps 。这个数字远远超过了大多数公司办公室连接到Internet 的带宽,而且这还只是单一视频流。唯一的希望是进行大规模的压缩。幸运的是,过去几十年大量的研究己经产生了许多压缩技术和算法,它们使得通过Internet传输视频成为可能。
- 通过Internet 发送的视频使用了多种格式,一些是专有的,还有一些是标准化的。最流行的编码是各种形式的MPEG。它是一个开放标准,适用以mpg 和mp4 为扩展名的文件,以及其他容器格式的文件。在本节,我们将通过MPEG 来学习如何完成视频压缩。首先,我们将着眼于用JPEG 对静止图像进行压缩。一个视频仅仅是一个图像序列(加上声音)。压缩视频的方式之一就是连续编码每一幅图像。第一个近似方法就是MPEG,它只是对每一帧进行JPEG 编码,再加上一些额外的功能,比如消除跨帧的冗余度。
JPEG 标准
- 联合图像专家组( JPEG, Joint Photographic Experts Group )标准用来压缩连续色调的静止图像(比如照片),该标准是由图像专家组在ITU 、ISO 和IEC(另一个标准化组织)的共同主持下完成的。它已得到广泛应用(扩展的jpg 文件),并且经常提供的压缩比为10: 1 ,对自然图像的压缩效果更好。JPEG 由国际标准10918 定义。实际上,相比一个单一的算法,它更像一个购物清单。它所定义的四个模式中,只有一种有损顺序模式与我们的讨论有关。我们将重点关注JPEG被通常用于24 位RGB 视频图像编码的方式。
- 该算法如下。第1 步是块准备。为了说明特征,让我们假设JPEG 的输入是一幅640 × 480 的RGB 图像,具有24 位/像素,如图a所示。RGB 并不是压缩使用的最好颜色模型。视频信号中的眼睛对亮度( luminance )或亮光,比对色度( chrominance)或颜色要敏感得多。因此,我们首先从R、G 和B 分量计算亮度Y,然后再计算两个色度Cb 和Cr。下面公式用于8 位值,变化范围从0 到255:(这里是RGB转换为YCbCr,注)
Y = 16 + 0.26R + 0.50G + 0.09B
Cb= 128 + 0.15R - 0.29G - 0.44B(这里应该有误,应该是-R,+B,寒注,Cb就+B,Cr就+R)
Cr = 128 + 0.44R - 0.37G + 0.07B(这里应该有误,应该是-B,注)
- 为Y、Cb 和Cr 分别构造一个独立的矩阵。接下来,在Cb 和Cr 矩阵中,针对每四个像素组成的方块计算其平均值,以便将矩阵减小至320 × 240 。这种缩减是有损的,但是眼睛几乎不会注意到,因为眼睛对亮度比对色度更加敏感。然而,这样做却能够把整个数据量压缩一半。现在从这三个矩阵的每个元素中减去128 ,以便使元素范围的中间值变成0 。最后,每个矩阵被分割成8 × 8 的块。Y 矩阵有4800 个块:其他两个矩阵有1200 个块,如图b所示。

- JPEG 的第2 步是对7200 个块中的每一个块单独应用离散余弦变换(DCT, Discrete Cosine Transfonnation )。每个DCT 的输出是一个8 × 8 的DCT 系数矩阵。DCT 元素(0, 0)是每个块的平均值。其他的元素表明了在每个空间频率处的频谱功率。通常,随着元素离原点(0, 0)的距离越来越远,它们的值也迅速地减小,如图所示。

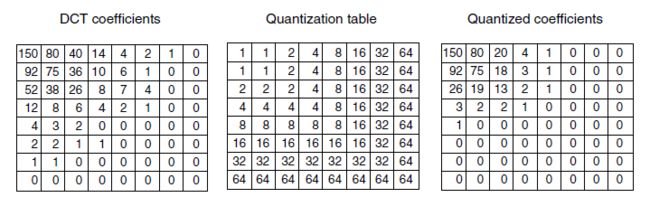
- 一旦完成DCT, JPEG 编码进入第3 步,这一步称为量化( quantization )。在这一步中,一些不那么重要的DCT 系数被除掉。这种(有损)变换是这样来完成的:将8 × 8 DCT 矩阵中的每个系数除以一个权值,而该权值是通过查询一张表获得的。如果所有的权值都是1 ,则变换实际上没有做任何事情。然而,如果权值表从原点开始迅速递增,则较高的空间频率将被快速丢弃。
- 下图给出了这一步的一个例子。在这里,我们可以看到初始的DCT 矩阵、量化表,以及每个DCT 元素除以量化表中对应元素之后得到的结果。量化表中的值不是JPEG 标准的一部分。每个应用必须提供它自己的量化表,从而允许它自己来控制损失-压缩之间的权衡。
- 第4 步将每一块的(0, 0 )元素的值用它与前一块中对应元素的差值来替代。因为这些元素是它们各自块的平均值,它们应该变化得很缓慢,因此,采用差值之后可以把它们中的大部分减成很小的数值。其他的元素不计算差值。
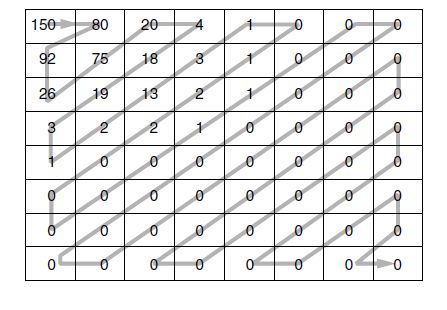
- 第5 步将64 个元素排列起来,并且对此列表使用行程编码方法。按照从左到右再从上往下的方法对块进行扫描,这种方式不会将0 集中到一起,所以JPEG 采用了“Z ”字形的扫描模式,如图 所示。在这个例子中,“Z”字形扫描模式在矩阵末端产生38 个连续的0。这个0 串能够被减少为一个计数值,即由计数值来表明这38 个0,这项技术即为行程编码。
- 现在我们有了一列数值来代表图像(在变换空间中)。第6 步对这些数值进行霍夫曼编码,以便于存储或传输:给常见的数值分配较短的编码,即不常见的数值被分配较长的编码。JPEG 或许看起来很复杂,它的确如此,因为它确实复杂。然而,能够达到20: 1 的压缩效率也是物有所值。解码JPEG 图像需要运行后向算法。JPEG 算法基本上是对称的:解码需要和编码花一样长的时间。正如我们将看到的那样,并不是所有的压缩算法都具有这种特性。
MPEG 标准
- 运动图像专家组(MPEG, Motion Picture Experts Group)标准。因为电影同时包含了图像和声音,所以, MPEG 既可以压缩音频同时也可以压缩视频。标准MPEG-1(它包括了MP3音频)首次发布于1993 年,从此获得了广泛的应用,直到今天依然如此。它的目标是产生录像机品质的输出,而这个输出必须被压缩40: 1 才能达到1 Mbps 左右的速率。这样的视频适应用户通过Internet 广泛使用Web 站点。
- 标准MPEG-2 发布于1996 年,它的设计目标是压缩广播品质的视频。现在它已非常流行,因为它是DVD 视频编码(这是通向Internet 无法回避的方式)和数字广播电视(作为DVB )的基础。DVD 品质的视频一般的编码速率是4~8 Mbps。
- MPEG-4 标准有两种视频格式。第一种格式发布于1999 年,以基于对象的表示来编码视频。它允许自然图像和合成图像,以及其他各类媒体的混合。有了这种结构,很容易地让程序与电影数据交互。第二种格式于2003年发布,称为H.264 或高级视频编码( AVC, Advanced Video Coding )。它的目标是编码率为早期相同品质水平的视频编码率的一半,以便更好地支持通过网络进行视频传输。这个编码器用于大多数蓝光光盘的HDTV。
- MPEG 能同时压缩音频和视频。由于音频和视频编码器独立工作,这就存在一个如何在接收端同步两个流的问题。解决的办法是用一个时钟,将当前时间的时间戳输出到两个编码器。这些时间戳被包含在编码后的输出流中,并且一路传播到接收端,接收端的播放器可以用这些时间戳来同步音频流和视频流。
- MPEGEG 视频压缩利用了电影中存在的两种冗余优势:空间和时间。通过用JPEG 对每一帧单独进行简单编码可以获得空间冗余。这种方法偶尔会被使用,就像编辑视频制作那样,特别是当需要随机访问每一帧时。在这种模式下,可以达到JPEG 的压缩水平。还有一种现象也可以考虑用来压缩图像。连续的帧往往几乎是相同的,充分利用这样的事实还可以获得更大的压缩率。其效果比第一次出现的要差一些。然而,运行75 个甚至更多个高度相似的帧比简单地利用JPEG 对每一帧进行独立编码提供了更多的冗余,因而具有更大的压缩潜力。
- 假设摄像机和背景都固定不变并且只有一两个演员慢慢地走来走去,帧和帧之间几乎所有的像素都是相同的。在这里,只要从前一帧中减去当前帧,并且对两帧之差运行JPEG 算法,效果就会非常好。然而,对于那些场景:摄像机在移动或者不断地推拉,这项技术的效果会很差。这就需要某种办法来补偿这种运动。这恰好是MPEG 擅长的工作,也是MPEG 和JPEG 的主要区别。
- MPEG 的输出包括3 类帧:
(1) I-帧( Intracoded 企runes ):帧内编码帧包含了压缩的静止图片。
(2) P-帧( Predictive fraines ):预测帧是与前一帧的逐块差值。
(3) B-帧( Bidirectional 企runes ):双向帧是与前一帧和后一帧的逐块差值。 - I-帧只是一些静止图片。它们采用JPEG 或者其他类似的算法编码。在输出流中周期性地出现I-帧(比如,每秒1 或者2 次〉是有价值的,其中的原因有三。第一, MPEG可能被用于组播传输,观众可以随意收看视频节目。如果所有的帧都依赖于前面的帧,那么一直要回溯到第一帧,否则错过第一帧的人就永远也解不出任何一个后续帧。第二,如果任意一帧发生了接收错误,则后续帧的解码将再也不可能进行:从那时开始的一切都将不知所云。第三,若没有I 帧,那么,在快进或者回退时,解码器将不得不计算经过的每一帧,以便知道暂停在某个帧的完整值。因此I-帧必须周期性地出现在媒体流中。
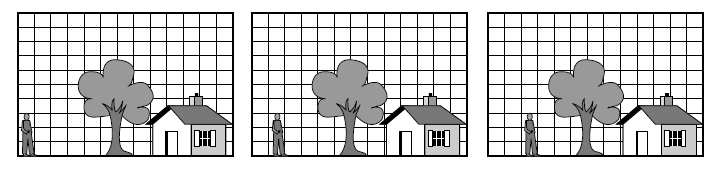
- 相反, P-帧是对帧间的差值进行编码。P 帧建立在宏块想法的基础上,宏块覆盖了亮度空间中的16 × 16 像素,以及色度空间中的8 × 8 像素。通过搜索前一帧中与自己相同的部分或稍有不同的部分来进行宏块的编码。图显示了P 帧用法的一个例子。在这里,我们看到3 个连续的帧,它们具有相同的背景, 但是人的位置有所不同。包含这3 个帧背景场景的宏块能够精确地匹配,但是包含人的宏块在位置上有一定的未知量偏移,而且必须被跟踪。
- MPEG 标准并没有规定如何进行搜索、搜索的范围多大,也没有规定如何评价一个匹配的好坏。这些算法自行决定。 一个实现可能是这样的:在前一帧的当前位置上搜索一个宏块,并且也在x 方向上偏移±∆X 范围内和y 方向偏移±∆y 范围内的所有位置上搜索该宏块。对于每个位置,计算亮度矩阵的匹配数量。得分值最高的那个位置只要超过某个预定的阀值,则它被认为胜出者。否则,该宏块称为丢失。当然,还有可能存在其他更加复杂的算法。
- 如果找到了一个宏块,则利用它与前一帧中对应宏块之间的差值进行编码(包括亮度和两个色度〉。然后,对这些差值矩阵进行离散余弦变换、量化、行程编码和霍夫曼编码,跟通常的做法一样。再者,在输出流中该宏块的值就是运动向量(相对于前一个位置在每个方向上运动了多远),紧随其后的是它差值的编码。如果在前一帧中没有定位到该宏块,则对当前值进行编码,就如同1-帧的做法一样。
- 很明显,这个算法是高度非对称的。这种做法以编码速度为代价,换来最小化MEPG 输出流。对于电影资料库的一次性编码应用来说,这种方法非常好,但是对于实时视频会议来说则非常可怕。类似地,每个实现可以自由决定什么组成了“找到的”宏块。这种自由度允许各个算法实现在质量和速度上进行竞争,但总是会产生兼容的MPEG 输出。
- 到目前为止,对MPEG 的解码非常直截了当。解码I-帧类似于解码JPEG 图像。解码P-帧则要求解码器缓冲前面的帧,然后利用完全编码的宏块以及包含与前一帧差值的宏块,在另一个缓冲区中构造出新的一帧。这个新帧由一个宏块接着一个宏块组合起来。
- B-帧类似于P-帧,不同之处在于,它允许参照的宏块可以是前一帧,也可以是后一帧。这种更大的自由度带来了更强的运动补偿。为了进行B-帧解码,解码器需要同时在内存中保留一系列帧:过去的帧、当前正在被解码的帧以及未来的帧。同样,尽管B-帧的解码更复杂,而且增加了某些额外的延迟。这是因为给定一个B-帧不能马上被解码出来,必须要等到它依赖的后续帧到达。因此,尽管B-帧提供了最好的压缩算法,由于其更强的复杂性以及对缓冲区的需求,并不是总能适用于一切场合。
- MPEG 标准包含许多增强型功能,这些技术实现了优良的压缩级。AVC 可以超过50: 1 的压缩率来压缩视频,从而把网络带宽的需求减少到相当的程度。