论文阅读笔记:A retinal vessel detection approach using convolution neural network with 强化样本学习策略
A retinal vessel detection approach using convolution neural network with reinforcement sample learning strategy
采用卷积神经网络和强化样本学习策略对视网膜血管进行检测
摘要
本文将检测任务定义为一个分类问题,并使用卷积神经网络(CNN)作为两类分类器进行求解。该模型由2个卷积层、2个池化层、1个dropout层和1个loss层组成。该算法的贡献是双重的。首先,设计了一种新的CNN模型来自动提取视网膜血管区域的特征并对其进行分类。与传统的分类程序相比,它是全自动的,不需要预处理和手工提取和描述特征。其次,提出了一种新的强化样本学习方法,以减少迭代次数和训练时间。利用视网膜数字图像进行血管提取(DRIVE)和视网膜结构化分析(STARE)数据集的训练和测试。本文提出的CNN在DRIVE数据集(91.99%准确率,0.9652 AUC score, ROC下面积),STARE数据集(92.20%准确率,0.9440 AUC值)上实现了更好的性能,明显优于目前最先进的视网膜血管自动分割算法。我们进一步比较了我们的结果与几种最先进的方法基于AUC值。对比表明,我们的方案获得了第二好的AUC值。该方法无需预处理,具有较高的精度和训练速度。
1.介绍
2.提出的方法
2.1 CNN框架
在该模型中,CNN的输入为ROI图像,输出为ROI中心像素的分类结果。与传统的分类方法相比,CNN能够通过自适应其多层前馈结构自动提取不同的特征。该方法采用五种类型的层来构造CNN网络。这些层分别是卷积层、池化层、Dropout层、全连接层和损失函数层。其中使用dropout层提高网络的泛化能力。
在卷积层中,设x l−1(m)为l-1层的第m个输入特征,W l( m, n)为连接输出层第n个特征与输入层第m个特征的滤波器的权值,bl(n)为偏置。第l卷积层的xl(n)值计算为:

其中*是卷积运算,而f是一个非线性sigmoid函数。随机初始化滤波器的权值W l(m,n),然后通过反向传播算法进行更新。
池化层用于减小特征映射的空间大小。它能有效地减少网络参数个数,避免过拟合问题。池化层l中的xl(n)值计算如下:
![]()
其中pool(·)为采样函数。
网络最后一层的全连接层作为分类器工作。在本方法中,全连接层采用softmax函数:

其中,y是分类标签,w是权值。
在提出的模型中,损失层采用交叉熵损失函数来测量最终softmax层的误差为:

其中#(·)为指示函数。M是样本的总数,N是类的总数。W是每一层的权向量。
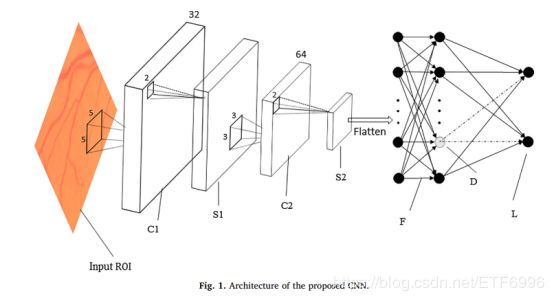
该模型包括两个卷积层、两个池化层、一个全连接层、一个dropout层和一个loss层。在第一和第二卷积层中,我们分别使用了32个和64个尺寸为5×5的滤波器。在池化层中,采用2×2 最大池化操作。loss层采用softmax。CNN层次的详细结构如表1所示,其结构如图1所示。

2.2 强化样本学习策略
强化样本学习的思想是对训练过程中表现较差的样本进行网络强化训练。具体步骤如下:
1. 将样品随机分成几批。
2. 在一个epoch内使用所有batches的样品训练模型。
3. 识别性能低于当前epoch标准的batches。
4. 仅使用具有更多epochs的这些batches进行网络调优。
5. 转到步骤2,对模型进行训练,直到满足终止条件为止
在步骤2中,识别性能较差的样本的选取准则:

其中Bi为第t个epoch的批次样本,Er (t)(Bi) 为第t个epoch时,Bi的分类错误率。N是批次总数。如果批处理的错误率大于C,则使用更多的epoch对其进行训练(见表2)。
在步骤4中,网络仅对这些批进行调优,精度较差。要调优的迭代周期由基于先前错误率的策略决定。其思想是,性能越差,就会使用越多的epoch来训练那批样本。重复的epoch数:

其中f(·)是将Er和C的绝对差映射到epoch数的函数。在我们的实验中,我们使用分段函数来实现它。
利用提出的CNN网络和增强样本学习方法实现视网膜血管检测算法,总结为:

3.实验结果
3.1 实验硬件配置
所有的实验都在一台服务器上运行,该服务器拥有2 x 6核Intel Xeon处理器和128gb内存。该服务器配备了多个NVIDIA Tesla K40 gpu,每个gpu有12gb内存。在我们的实验中,我们使用多个gpu来快速完成所需的时间。当考虑到强化样本学习策略减少了达到与传统方法相同的错误所需的时间周期时,这一点尤其正确。我们的实验设置为增加每个epoch中使用的层的复杂性提供了很大的余地。
3.2 实验训练速度
在本节中,为了评估新训练策略的性能,我们使用MNIST数据集对LeNet进行训练,并将改进后的训练速度与传统训练速度进行比较。传统方法和改进方法的运行时间分别为216.58秒和206.42秒。测试装置的最终精度分别为98.78%和99.52%。详细的训练信息如图2所示。

3.3 视网膜眼底图像数据集
DRIVE数据集包含40个总眼底图像,并分为训练集和测试集[4]。 训练和测试集包含相同数量的图像(20)。 每幅图像都是用768×584像素的每个彩色平面8位来捕捉的。每个图像上的视场(FOV)是圆形的,直径约为540像素,所有图像都使用FOV裁剪。
STARE(视网膜的结构分析)数据集有大约400个原始图像。 血管分割注释有20个手标记图像[19,20]。 我们使用了带有手动标记结果的10张图像作为训练网络,并留下10张图像进行验证。
3.4 视网膜血管检测实验
在本节中,我们分别使用DRIVE和STARE数据集来训练和测试所提出的网络。下降率设置为0.9。学习效率由0.01逐渐下降到0.001。将学习率设为分段函数,下降周期为5个epoch,下降因子为0.005。该网络有100个epoch,batch size为256.
为了理解提出的CNN的结果,我们使用全连接层的结果输出特征。图3显示了一个示例图像上的两个特征映射。

利用精度指标对检测性能进行了评价。此外,还有一个接收算子曲线(ROC)和ROC下的面积(AUC)用来测量检测性能。在训练过程中,我们将强化学习方法与传统的学习策略进行了比较。比较了不同时期训练集和验证集的精度,并在图4为DRIVE图,图5为STARE图。由此可见,在最后一个阶段,强化学习策略比传统学习策略具有更好的准确性。


在DRIVE数据集中,经过100个epoch后,该方法对训练集和验证集的准确率分别为91.99%和90.64%,对传统方法的准确率分别为91.06%和90.15% 他们的验证集上的AUC值分别为0.9652和0.9624。图6为我们提出的方法在测试集上的图像检测结果。

Fig. 6. Visualization of the detection results by our proposed methods on three samples randomly taken from the DRIVE data set: (a) Original images (b)Corresponding ground truth and © Detection results.
在STARE数据集中,经过100个epoch后,该方法对训练集和验证集的准确率分别为92.20%和87.12%,对传统方法的准确率分别为90.206%和85.77%。验证集上的AUC值分别为0.9440和0.9382。
我们进一步将结果与使用AUC值的几种最先进的方法进行比较,如表3所示。如表3所示,我们的方案获得了第二好的AUC值,高于其他大多数方法。Dasgupta等人[21]的AUC值最好,但差异很小。此外,使用所提出的策略训练的CNN具有比传统训练方法更好的性能。
在相同的训练阶段,我们还将所提出的CNN与不加强样本学习策略的CNN进行了比较。精度、精密度、灵敏度、特异性、Fscore等性能指标定义为:
![]()

其中TP、TN、FP、FN分别为真阳性、真阴性、假阳性、假阴性。表4中的比较结果表明,该方法具有较好的性能。

4.总结
深度神经网络能够在不需要任何领域知识的情况下,从原始像素数据中学习层次特征表示。它在基于知识的特征难以解释的医学图像中具有巨大的潜力。本文提出了一种用于视网膜血管检测的卷积神经网络。我们在DRIVE数据集上演示了我们提出的方法的性能。所得结果与相关比较表明了本文所提方法的有效性。我们的方法有第二好的ACU值。值得一提的是,我们的提案没有预处理阶段,这意味着输入的彩色眼底图像被送入CNN。因此,几个适当的预处理步骤也可能在未来的工作中改善我们的结果。