selenium入门实战 - 实现微博动态监控(Python)【一】
编写简单的Python脚本实现微博新动态的实时监控
- 运行环境搭建
- 流程设计
- 详细设计
- login
- parser_weibo_info& refresh
- 执行一下
- 总结
运行环境搭建
- Python3.6 运行环境
- Chrome浏览器 和 对应的selenium驱动 博主找到国内的驱动镜像源地址: https://npm.taobao.org/mirrors/chromedriver/
这里一定要注意驱动和浏览器的版本要对应,否则会报错 - 需要安装Python 的 selenium库来调取驱动的API 这里推荐pip install selenium 来安装,包的版本没有要求最新的即可
流程设计
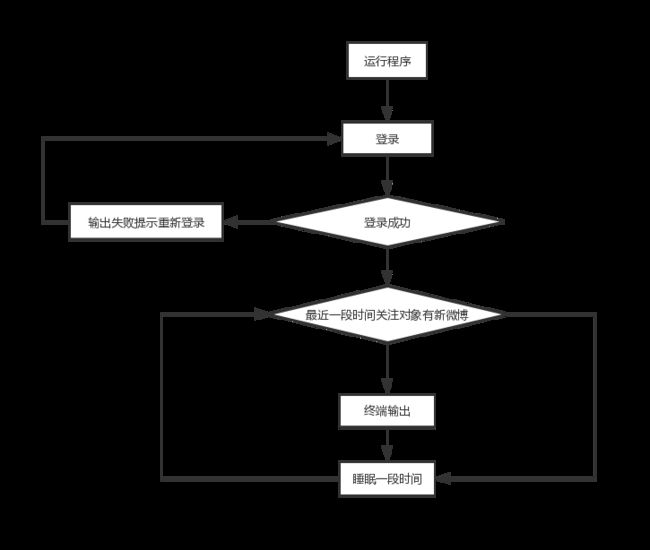
详细设计
这里采用面向对象的设计思路进行设计
class WeiBo(object):
def __init__(self):
def login(self, username, passwd):
"""
接收账号密码,返回登录状态
:param username: 账号
:param passwd: 密码
:return: None
"""
pass
def get_real_html(self):
"""
这里没有使用selenium原生的xpath 而是采用了lxml 包
实在是因为博主用习惯了
:return: html obj
"""
pass
def parser_weibo_info(self):
"""
解析获得页面中的微博瀑布流,判断哪些是新发的微博 输出结果
:return:
"""
pass
def refresh(self):
"""
刷新页面
:return:
"""
这样一个weibo类的详细设计就设计完成了,在实际运行的时候我们应该通过login 方法获得一个已经登录成功的浏览器窗口,接下来不断的执行parser_weibo_info()方法就能实现微博的监控功能了,接下来就是每个方法的具体实现
login
网上获取微博登录状态的方法千奇百怪,不过既然我们都用了selenium,那就不获取cookie 直接从登录页面开始登录,这样比较简单
微博的登录地址:‘https://weibo.com/’
登录成功的标识:登录成功后浏览器窗口的tittle 会变成 我的首页 xxxx
根据以上结论,我们将login方法实现如下:
class WeiBo(object):
def __init__(self, start_url, sleep_time = 5):
"""
:param start_url: 微博登录页面url
:param sleep_time: 间隔多久扫描一次 单位 秒
"""
# 获取一个浏览器对象
self.driver = self._get_driver()
self.start_url = start_url
self.sleep_time = sleep_time
def _get_driver(self):
driver = webdriver.Chrome() # 调用chrome浏览器
driver.maximize_window()
return driver
def login(self, username, passwd):
"""
接收账号密码,返回登录状态
:param username: 账号
:param passwd: 密码
:return: None
"""
# 打开登录url
self.driver.get(self.start_url)
"""
这里需要特别注意:
微博登录界面比较卡慢,所以登录框不会第一时间加载出来会导致xpath选取不到登录框,这里采用死循环每隔0.5秒填写一次,直到填写成功
有时候点击登录按钮会出现验证码,这里需要进行额外判断
根据登录成功的标识判断是否登录成功
整套流程走完之后就能得到一个登录成功之后的微博页面,也就是说此时 driver对象已经可以看到账号对应的微博内容
"""
sign = True
while sign:
try:
self.driver.find_element_by_xpath('//input[@id="loginname"]').send_keys(username)
self.driver.find_element_by_xpath('//input[@name="password"]').send_keys(passwd)
sign = False
except Exception as e:
time.sleep(0.5)
self.driver.find_element_by_xpath('//span[@node-type="submitStates"]').click()
# 检测是否有验证码
try:
self.driver.find_element_by_xpath('//input[@value="验证码"]')
sign = True
while sign:
v_str = input("请输入网页验证码:")
self.driver.find_element_by_xpath('//input[@value="验证码"]').send_keys(v_str)
self.driver.find_element_by_xpath('//span[@node-type="submitStates"]').click()
try:
self.driver.find_element_by_xpath('//span[@node-type="text"]/a[text() = "查看帮助"')
except Exception as e:
print('登录成功,等待页面跳转...')
sign = False
sign = True
while sign:
if '我的首页' in self.driver.title:
print('页面跳转完毕,您已经处于微博首页!')
sign = False
time.sleep(0.5)
except Exception as e:
if '我的首页' in self.driver.title:
print('登录成功,您已经处于微博首页!')
else:
print(f'验证码逻辑执行失败!{e}')
pass
parser_weibo_info& refresh
解析就是把当前浏览器窗口的html转换成为lxml对象,使用xpath 提取信息进行判断
带_的方法表示类的私有方法,不对外使用,这样写常常能让代码逻辑更清晰
class WeiBo(object):
......
def _get_real_html(self):
html = self.driver.page_source
tmp = re.compile('{"ns":"pl.content.homefeed.index"(.*?)\)').findall(html)
if len(tmp):
real_html = json.loads('{"ns":"pl.content.homefeed.index"%s' % tmp[0])['html'].replace('<', '<').replace('>', '>')
return etree.HTML(real_html)
def parser_weibo_info(self):
selector = self._get_real_html()
if selector is not None:
infos = selector.xpath('//div[@class="WB_detail"]')
t = []
for info in infos:
# 博主名称
weibo_author = info.xpath('./div[@class="WB_info"]/a/@nick-name')[0]
# 微博内容
tmp = info.xpath('./div[@class="WB_text W_f14"]')
# if len(tmp):
# print(tmp[0].xpath('string(.)').strip())
# 微博更新时间
weibo_time = info.xpath('./div[@class="WB_from S_txt2"]/a/text()')
if weibo_time:
weibo_time = weibo_time[0]
min = re.compile('([0-9]+)').findall(weibo_time)
if len(min) and int(min[0]) < 20 and ':' not in weibo_time:
t.append('{} {} 发布了新消息'.format(weibo_time, weibo_author))
print('--'.join(t))
else:
print('未获取到新微博!')
def refresh(self):
self.driver.refresh()
执行一下
if __name__ == '__main__':
weibo = WeiBo('https://weibo.com/', 10)
login = weibo.login('', '')
while True:
weibo.parser_weibo_info()
print('over! start sleep!')
# 刷新页面
weibo.refresh()
print('start work')
总结
- selenium只是个自动化测试工具,长时间运行会出现异常,页面崩溃啥的
- 第一期比较简单,下期期会吧打印的通知改成邮件通知,并使用flask将这个服务简单包装成为一个浏览器web服务,完善整个实战教程