Flink 1.11 新特性之 SQL Hive Streaming 简单示例
7月7日,Flink 1.11 版本发布,与 1.10 版本相比,1.11 版本最为显著的一个改进是 Hive Integration 显著增强,也就是真正意义上实现了基于 Hive 的流批一体。
本文用简单的本地示例来体验 Hive Streaming 的便利性并跟大家分享体验的过程以及我的心得,希望对大家上手使用有所帮助。
添加相关依赖
测试集群上的 Hive 版本为 1.1.0,Hadoop 版本为 2.6.0,Kafka 版本为 1.0.1。
2.11
1.11.0
2.6.5-10.0
1.1.0
org.apache.flink
flink-streaming-scala_${scala.bin.version}
${flink.version}
org.apache.flink
flink-clients_${scala.bin.version}
${flink.version}
org.apache.flink
flink-table-common
${flink.version}
org.apache.flink
flink-table-api-scala-bridge_${scala.bin.version}
${flink.version}
org.apache.flink
flink-table-planner-blink_${scala.bin.version}
${flink.version}
org.apache.flink
flink-connector-hive_${scala.bin.version}
${flink.version}
org.apache.flink
flink-sql-connector-kafka_${scala.bin.version}
${flink.version}
org.apache.flink
flink-json
${flink.version}
org.apache.flink
flink-shaded-hadoop-2-uber
${flink-shaded-hadoop.version}
org.apache.hive
hive-exec
${hive.version}
另外,别忘了找到 hdfs-site.xml 和 hive-site.xml,并将其加入项目。
创建执行环境
Flink 1.11 的 Table/SQL API 中,FileSystem Connector 是靠增强版 StreamingFileSink 组件实现,在源码中名为 StreamingFileWriter。我们知道,只有在 Checkpoint 成功时,StreamingFileSink 写入的文件才会由 Pending 状态变成 Finished 状态,从而能够安全地被下游读取。所以,我们一定要打开 Checkpointing,并设定合理的间隔。
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(3)
val tableEnvSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(streamEnv, tableEnvSettings)
tableEnv.getConfig.getConfiguration.set(ExecutionCheckpointingOptions.CHECKPOINTING_MODE, CheckpointingMode.EXACTLY_ONCE)
tableEnv.getConfig.getConfiguration.set(ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL, Duration.ofSeconds(20))注册 HiveCatalog
val catalogName = "my_catalog"
val catalog = new HiveCatalog(
catalogName, // catalog name
"default", // default database
"/Users/lmagic/develop", // Hive config (hive-site.xml) directory
"1.1.0" // Hive version
)
tableEnv.registerCatalog(catalogName, catalog)
tableEnv.useCatalog(catalogName)创建 Kafka 流表
Kafka Topic 中存储的是 JSON 格式的埋点日志,建表时用计算列生成事件时间与水印。1.11 版本 SQL Kafka Connector 的参数相比 1.10 版本有一定简化。
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS stream_tmp")
tableEnv.executeSql("DROP TABLE IF EXISTS stream_tmp.analytics_access_log_kafka")
tableEnv.executeSql(
"""
|CREATE TABLE stream_tmp.analytics_access_log_kafka (
| ts BIGINT,
| userId BIGINT,
| eventType STRING,
| fromType STRING,
| columnType STRING,
| siteId BIGINT,
| grouponId BIGINT,
| partnerId BIGINT,
| merchandiseId BIGINT,
| procTime AS PROCTIME(),
| eventTime AS TO_TIMESTAMP(FROM_UNIXTIME(ts / 1000,'yyyy-MM-dd HH:mm:ss')),
| WATERMARK FOR eventTime AS eventTime - INTERVAL '15' SECOND
|) WITH (
| 'connector' = 'kafka',
| 'topic' = 'ods_analytics_access_log',
| 'properties.bootstrap.servers' = 'kafka110:9092,kafka111:9092,kafka112:9092'
| 'properties.group.id' = 'flink_hive_integration_exp_1',
| 'scan.startup.mode' = 'latest-offset',
| 'format' = 'json',
| 'json.fail-on-missing-field' = 'false',
| 'json.ignore-parse-errors' = 'true'
|)
""".stripMargin
)前面已经注册了 HiveCatalog,故在 Hive 中可以观察到创建的 Kafka 流表的元数据(注意该表并没有事实上的列)。
hive> DESCRIBE FORMATTED stream_tmp.analytics_access_log_kafka;
OK
# col_name data_type comment
# Detailed Table Information
Database: stream_tmp
Owner: null
CreateTime: Wed Jul 15 18:25:09 CST 2020
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://sht-bdmq-cls/user/hive/warehouse/stream_tmp.db/analytics_access_log_kafka
Table Type: MANAGED_TABLE
Table Parameters:
flink.connector kafka
flink.format json
flink.json.fail-on-missing-field false
flink.json.ignore-parse-errors true
flink.properties.bootstrap.servers kafka110:9092,kafka111:9092,kafka112:9092
flink.properties.group.id flink_hive_integration_exp_1
flink.scan.startup.mode latest-offset
flink.schema.0.data-type BIGINT
flink.schema.0.name ts
flink.schema.1.data-type BIGINT
flink.schema.1.name userId
flink.schema.10.data-type TIMESTAMP(3)
flink.schema.10.expr TO_TIMESTAMP(FROM_UNIXTIME(`ts` / 1000, 'yyyy-MM-dd HH:mm:ss'))
flink.schema.10.name eventTime
flink.schema.2.data-type VARCHAR(2147483647)
flink.schema.2.name eventType
# 略......
flink.schema.9.data-type TIMESTAMP(3) NOT NULL
flink.schema.9.expr PROCTIME()
flink.schema.9.name procTime
flink.schema.watermark.0.rowtime eventTime
flink.schema.watermark.0.strategy.data-type TIMESTAMP(3)
flink.schema.watermark.0.strategy.expr `eventTime` - INTERVAL '15' SECOND
flink.topic ods_analytics_access_log
is_generic true
transient_lastDdlTime 1594808709
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 1.797 seconds, Fetched: 61 row(s)创建 Hive 表Flink SQL 提供了兼容 HiveQL 风格的 DDL,指定 SqlDialect.HIVE 即可( DML 兼容还在开发中)。
为了方便观察结果,以下的表采用了天/小时/分钟的三级分区,实际应用中可以不用这样细的粒度(10分钟甚至1小时的分区可能更合适)。
tableEnv.getConfig.setSqlDialect(SqlDialect.HIVE)
tableEnv.executeSql("CREATE DATABASE IF NOT EXISTS hive_tmp")
tableEnv.executeSql("DROP TABLE IF EXISTS hive_tmp.analytics_access_log_hive")
tableEnv.executeSql(
"""
|CREATE TABLE hive_tmp.analytics_access_log_hive (
| ts BIGINT,
| user_id BIGINT,
| event_type STRING,
| from_type STRING,
| column_type STRING,
| site_id BIGINT,
| groupon_id BIGINT,
| partner_id BIGINT,
| merchandise_id BIGINT
|) PARTITIONED BY (
| ts_date STRING,
| ts_hour STRING,
| ts_minute STRING
|) STORED AS PARQUET
|TBLPROPERTIES (
| 'sink.partition-commit.trigger' = 'partition-time',
| 'sink.partition-commit.delay' = '1 min',
| 'sink.partition-commit.policy.kind' = 'metastore,success-file',
| 'partition.time-extractor.timestamp-pattern' = '$ts_date $ts_hour:$ts_minute:00'
|)
""".stripMargin
)Hive 表的参数复用了 SQL FileSystem Connector 的相关参数,与分区提交(Partition Commit)密切相关。仅就上面出现的4个参数简单解释一下。
-
sink.partition-commit.trigger:触发分区提交的时间特征。默认为 processing-time,即处理时间,很显然在有延迟的情况下,可能会造成数据分区错乱。所以这里使用 partition-time,即按照分区时间戳(即分区内数据对应的事件时间)来提交。
-
partition.time-extractor.timestamp-pattern:分区时间戳的抽取格式。需要写成 yyyy-MM-dd HH:mm:ss 的形式,并用 Hive 表中相应的分区字段做占位符替换。显然,Hive 表的分区字段值来自流表中定义好的事件时间,后面会看到。
-
sink.partition-commit.delay:触发分区提交的延迟。在时间特征设为 partition-time 的情况下,当水印时间戳大于分区创建时间加上此延迟时,分区才会真正提交。此值最好与分区粒度相同,例如若 Hive 表按1小时分区,此参数可设为 1 h,若按 10 分钟分区,可设为 10 min。
-
sink.partition-commit.policy.kind:分区提交策略,可以理解为使分区对下游可见的附加操作。 metastore 表示更新 Hive Metastore 中的表元数据, success-file 则表示在分区内创建 _SUCCESS 标记文件。
当然,SQL FileSystem Connector 的功能并不限于此,还有很大自定义的空间(如可以自定义分区提交策略以合并小文件等)。具体可参见官方文档。
https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/connectors/filesystem.html#streaming-sink
流式写入 Hive
注意将流表中的事件时间转化为 Hive 的分区。
tableEnv.getConfig.setSqlDialect(SqlDialect.DEFAULT)
tableEnv.executeSql(
"""
|INSERT INTO hive_tmp.analytics_access_log_hive
|SELECT
| ts,userId,eventType,fromType,columnType,siteId,grouponId,partnerId,merchandiseId,
| DATE_FORMAT(eventTime,'yyyy-MM-dd'),
| DATE_FORMAT(eventTime,'HH'),
| DATE_FORMAT(eventTime,'mm')
|FROM stream_tmp.analytics_access_log_kafka
|WHERE merchandiseId > 0
""".stripMargin
)
来观察一下流式 Sink 的结果吧。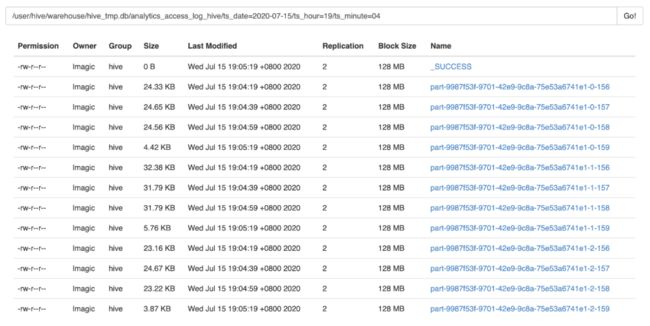
上文设定的 Checkpoint Interval 是 20 秒,可以看到,上图中的数据文件恰好是以 20 秒的间隔写入的。由于并行度为 3,所以每次写入会生成 3 个文件。分区内所有数据写入完毕后,会同时生成 _SUCCESS 文件。如果是正在写入的分区,则会看到 .inprogress 文件。
通过 Hive 查询一下,确定数据的时间无误。
hive> SELECT from_unixtime(min(cast(ts / 1000 AS BIGINT))),from_unixtime(max(cast(ts / 1000 AS BIGINT)))
> FROM hive_tmp.analytics_access_log_hive
> WHERE ts_date = '2020-07-15' AND ts_hour = '23' AND ts_minute = '23';
OK
2020-07-15 23:23:00 2020-07-15 23:23:59
Time taken: 1.115 seconds, Fetched: 1 row(s)流式读取 Hive
要将 Hive 表作为流式 Source,需要启用 Dynamic Table Options,并通过 Table Hints 来指定 Hive 数据流的参数。以下是简单地通过 Hive 计算商品 PV 的例子。
tableEnv.getConfig.getConfiguration.setBoolean(TableConfigOptions.TABLE_DYNAMIC_TABLE_OPTIONS_ENABLED, true)
val result = tableEnv.sqlQuery(
"""
|SELECT merchandise_id,count(1) AS pv
|FROM hive_tmp.analytics_access_log_hive
|/*+ OPTIONS(
| 'streaming-source.enable' = 'true',
| 'streaming-source.monitor-interval' = '1 min',
| 'streaming-source.consume-start-offset' = '2020-07-15 23:30:00'
|) */
|WHERE event_type = 'shtOpenGoodsDetail'
|AND ts_date >= '2020-07-15'
|GROUP BY merchandise_id
|ORDER BY pv DESC LIMIT 10
""".stripMargin
)
result.toRetractStream[Row].print().setParallelism(1)
streamEnv.execute()三个 Table Hint 参数的含义解释如下。
-
streaming-source.enable:设为 true,表示该 Hive 表可以作为 Source。
-
streaming-source.monitor-interval:感知 Hive 表新增数据的周期,以上设为 1 分钟。对于分区表而言,则是监控新分区的生成,以增量读取数据。
-
streaming-source.consume-start-offset:开始消费的时间戳,同样需要写成 yyyy-MM-dd HH:mm:ss 的形式。
更加具体的说明仍然可参见官方文档。
https://links.jianshu.com/go?to=https%3A%2F%2Fci.apache.org%2Fprojects%2Fflink%2Fflink-docs-release-1.11%2Fdev%2Ftable%2Fhive%2Fhive_streaming.html%23streaming-reading
最后,由于 SQL 语句中有 ORDER BY 和 LIMIT 逻辑,所以需要调用 toRetractStream() 方法转化为回撤流,即可输出结果。
The End
Flink 1.11 的 Hive Streaming 功能大大提高了 Hive 数仓的实时性,对 ETL 作业非常有利,同时还能够满足流式持续查询的需求,具有一定的灵活性。
感兴趣的同学也可以自己上手测试。
原文链接:
https://www.jianshu.com/p/fb7d29abfa14