数仓之基础架构
转自:http://blog.csdn.net/zyj8170/article/details/52920021
数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。其实数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。因此数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据应用:

从图中可以看出数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自上而下流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer, 装载Load)的过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
下面主要简单介绍下数据仓库架构中的各个模块,当然这里所介绍的数据仓库主要是指网站数据仓库。
1、数据仓库的数据来源
其实之前的一篇文章已经介绍过数据仓库各种源数据的类型——数据仓库的源数据类型,所以这里不再详细介绍。
对于网站数据仓库而言,点击流日志是一块主要的数据来源,它是网站分析的基础数据;当然网站的数据库数据也并不可少,其记录这网站运营的数据及各种用户操作的结果,对于分析网站Outcome这类数据更加精准;其他是网站内外部可能产生的文档及其它各类对于公司决策有用的数据。
2、数据仓库的数据存储
源数据通过ETL的日常任务调度导出,并经过转换后以特性的形式存入数据仓库。其实这个过程一直有很大的争议,就是到底数据仓库需不需要储存细节数据,一方的观点是数据仓库面向分析,所以只要存储特定需求的多维分析模型;另一方的观点是数据仓库先要建立和维护细节数据,再根据需求聚合和处理细节数据生成特定的分析模型。我比较偏向后面一个观点:数据仓库并不需要储存所有的原始数据,但数据仓库需要储存细节数据,并且导入的数据必须经过整理和转换使其面向主题。简单地解释下:
(1).为什么不需要所有原始数据?数据仓库面向分析处理,但是某些源数据对于分析而言没有价值或者其可能产生的价值远低于储存这些数据所需要的数据仓库的实现和性能上的成本。比如我们知道用户的省份、城市足够,至于用户究竟住哪里可能只是物流商关心的事,或者用户在博客的评论内容可能只是文本挖掘会有需要,但将这些冗长的评论文本存在数据仓库就得不偿失;
(2).为什么要存细节数据?细节数据是必需的,数据仓库的分析需求会时刻变化,而有了细节数据就可以做到以不变应万变,但如果我们只存储根据某些需求搭建起来的数据模型,那么显然对于频繁变动的需求会手足无措;
(3).为什么要面向主题?面向主题是数据仓库的第一特性,主要是指合理地组织数据以方面实现分析。对于源数据而言,其数据组织形式是多样的,像点击流的数据格式是未经优化的,前台数据库的数据是基于OLTP操作组织优化的,这些可能都不适合分析,而整理成面向主题的组织形式才是真正地利于分析的,比如将点击流日志整理成页面(Page)、访问(Visit或Session)、用户(Visitor)三个主题,这样可以明显提升分析的效率。
数据仓库基于维护细节数据的基础上在对数据进行处理,使其真正地能够应用于分析。主要包括三个方面:
3、数据的聚合
这里的聚合数据指的是基于特定需求的简单聚合(基于多维数据的聚合体现在多维数据模型中),简单聚合可以是网站的总Pageviews、Visits、Unique Visitors等汇总数据,也可以是Avg. time on page、Avg. time on site等平均数据,这些数据可以直接地展示于报表上。
4、多维数据模型
多维数据模型提供了多角度多层次的分析应用,比如基于时间维、地域维等构建的销售星形模型、雪花模型,可以实现在各时间维度和地域维度的交叉查询,以及基于时间维和地域维的细分。所以多维数据模型的应用一般都是基于联机分析处理(Online Analytical Process, OLAP)的,而面向特定需求群体的数据集市也会基于多维数据模型进行构建。
5、业务模型
这里的业务模型指的是基于某些数据分析和决策支持而建立起来的数据模型,比如我之前介绍过的用户评价模型、关联推荐模型、RFM分析模型等,或者是决策支持的线性规划模型、库存模型等;同时,数据挖掘中前期数据的处理也可以在这里完成。
6、数据仓库的数据应用
之前的一篇文章——数据仓库的价值中介绍过数据仓库的四大特性上的价值体现,但数据仓库的价值远不止这样,而且其价值真正的体现是在数据仓库的数据应用上。图中罗列的几种应用并未包含所有,其实一切基于数据相关的扩展性应用都可以基于数据仓库来实现。
7、报表展示
报表几乎是每个数据仓库的必不可少的一类数据应用,将聚合数据和多维分析数据展示到报表,提供了最为简单和直观的数据。
8、即席查询
理论上数据仓库的所有数据(包括细节数据、聚合数据、多维数据和分析数据)都应该开放即席查询,即席查询提供了足够灵活的数据获取方式,用户可以根据自己的需要查询获取数据,并提供导出到Excel等外部文件的功能。
9、数据分析
数据分析大部分可以基于构建的业务模型展开,当然也可以使用聚合的数据进行趋势分析、比较分析、相关分析等,而多维数据模型提供了多维分析的数据基础;同时从细节数据中获取一些样本数据进行特定的分析也是较为常见的一种途径。
10、数据挖掘
数据挖掘用一些高级的算法可以让数据展现出各种令人惊讶的结果。数据挖掘可以基于数据仓库中已经构建起来的业务模型展开,但大多数时候数据挖掘会直接从细节数据上入手,而数据仓库为挖掘工具诸如SAS、SPSS等提供数据接口。
11、元数据管理
元数据(Meta Date),其实应该叫做解释性数据,或者数据字典,即数据的数据。主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。一般会通过元数据资料库(Metadata Repository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。
最后做个Ending,数据仓库本身既不生产数据也不消费数据,只是作为一个中间平台集成化地存储数据;数据仓库实现的难度在于整体架构的构建及ETL的设计,这也是日常管理维护中的重头;而数据仓库的真正价值体现在于基于其的数据应用上,如果没有有效的数据应用也就失去了构建数据仓库的意义。

12、一种Hadoop多维分析平台的架构

整个架构由四大部分组成:数据采集模块、数据冗余模块、维度定义模块、并行分析模块。如图上图所示。
数据采集模块采用了Cloudera的Flume,将海量的小日志文件进行高速传输和合并,并能够确保数据的传输安全性。单个collector宕机之后,数据也不会丢失,并能将agent数据自动转移到其他的colllecter处理,不会影响整个采集系统的运行。如图5所示。
数据冗余模块不是必须的,但如果日志数据中没有足够的维度信息,或者需要比较频繁地增加维度,则需要定义数据冗余模块。通过冗余维度定义器定义需要冗余的维度信息和来源(数据库、文件、内存等),并指定扩展方式,将信息写入数据日志中。在海量数据下,数据冗余模块往往成为整个系统的瓶颈,建议使用一些比较快的内存NoSQL来冗余原始数据,并采用尽可能多的节点进行并行冗余;或者也完全可以在Hadoop中执行批量Map,进行数据格式的转化。
维度定义模块是面向业务用户的前端模块,用户通过可视化的定义器从数据日志中定义维度和度量,并能自动生成一种多维分析语言,同时可以使用可视化的分析器通过GUI执行刚刚定义好的多维分析命令。
并行分析模块接受用户提交的多维分析命令,并将通过核心模块将该命令解析为Map-Reduce,提交给Hadoop集群之后,生成报表供报表中心展示。
核心模块是将多维分析语言转化为MapReduce的解析器,读取用户定义的维度和度量,将用户的多维分析命令翻译成MapReduce程序。核心模块的具体逻辑如图下图所示。
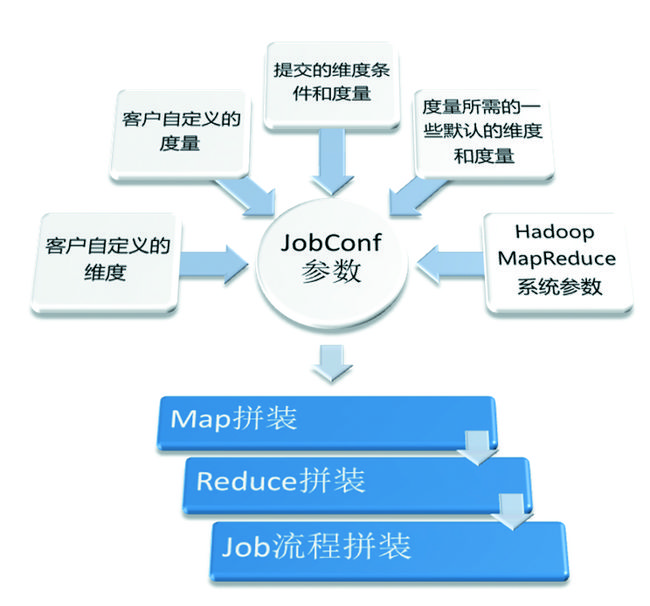
上图中根据JobConf参数进行Map和Reduce类的拼装并不复杂,难点是很多实际问题很难通过一个MapReduce Job解决,必须通过多个MapReduce Job组成工作流(WorkFlow),这里是最需要根据业务进行定制的部分。图7是一个简单的MapReduce工作流的例子。
MapReduce的输出一般是统计分析的结果,数据量相较于输入的海量数据会小很多,这样就可以导入传统的数据报表产品中进行展现。
13、Refer
1、数据仓库的源数据类型
http://webdataanalysis.net/web-data-warehouse/data-warehouse-source-data/
http://webdataanalysis.net/web-data-warehouse/multidimensional-data-model/
2、大数据下的数据分析平台架构
http://www.programmer.com.cn/7617/
3、数据的游戏:冰与火
http://coolshell.cn/articles/10192.html
4、Teradata 数据仓库技术架构及方案
http://wenku.baidu.com/view/1f8a30791711cc7931b71699.html
5、淘宝数据仓库架构实践
http://wenku.baidu.com/view/72d5a86658fafab069dc02d6.html
6、BI数据仓库数据分层
http://ierda.blog.163.com/blog/static/77469587201326105956470/
7、数据仓库逻辑架构设计(一)
http://www.alidata.org/archives/257
8、数据仓库模型的概述
http://wiki.mbalib.com/wiki/%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93%E6%A8%A1%E5%9E%8B
9、数据仓库
http://zh.wikipedia.org/wiki/%E8%B3%87%E6%96%99%E5%80%89%E5%84%B2
10、百亿级实时大数据分析项目,为什么不用Hadoop?
http://www.yonghongtech.com/webShare/webshare_w4.html
11、Java BI新生代——百度商业运营实践
http://www.infoq.com/cn/presentations/java-bi-the-new-generation-baidu-business-practice
12、阿里巴巴数据产品经理工作总结篇
http://mp.weixin.qq.com/s?__biz=MjM5MDI1ODUyMA==&mid=205181896&idx=3&sn=bb2d98b6d90c86552c260791bdd30faf#rd
13、大数据环境下互联网行业数据仓库/数据平台的架构之漫谈
http://lxw1234.com/archives/2015/08/471.htm
14、【干货经验分享】三种数据部门架构优与劣
http://dwz.cn/23QRbn
15、数据库schema设计与优化
http://www.dwz.cn/2nxXXH