一文读懂胶囊神经网络
来自 | 博客园 作者 | CZiFan
转自 | 深度学习这件小事
背景
Geoffrey Hinton是深度学习的开创者之一,反向传播等神经网络经典算法发明人,他和他的团队提出了一种全新的神经网络,这种网络基于一种称为胶囊(capsule)的结构,并且还发表了用来训练胶囊网络的囊间动态路由算法。
研究问题
传统CNN存在着缺陷(下面会详细说明),如何解决CNN的不足,Hinton提出了一种对于图像处理更加有效的网络——胶囊网络,其综合了CNN的优点的同时,考虑了CNN缺失的相对位置、角度等其他信息,从而使得识别效果有所提升。
研究动机
CNN的缺陷
CNN着力于检测图像像素中的重要特征。考虑简单的人脸检测任务,一张脸是由代表脸型的椭圆、两只眼睛、一个鼻子和一个嘴巴组成。而基于CNN的原理,只要存在这些对象就有一个很强的刺激,因此这些对象空间关系反而没有那么重要。
如下图,右图不是人脸但都具备了人脸需要的对象,所以CNN有很大可能通过具有的对象激活了是人脸的判断,从而使得结果判断出错。
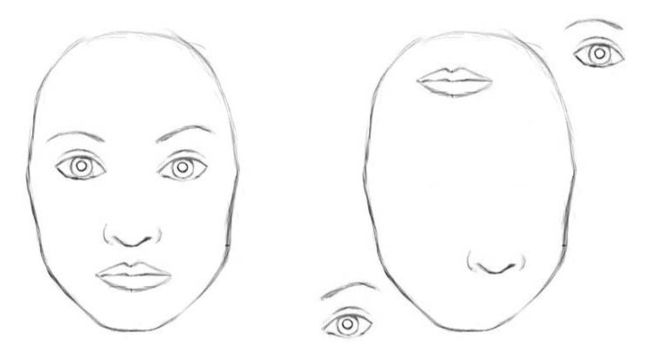
重新审视CNN的工作方式,高层特征是低层特征组合的加权和,前一层的激活与下一层神经元的权重相乘并且相加,接着通过非线性激活函数进行激活。在这么一个架构中,高层特征和低层特征之间的位置关系变得模糊(我认为还是有一些的只是没有很好的利用)。而CNN解决这个问题的方法是通过最大池化层或者或许的卷积层来扩大下续卷积核的视野(我认为最大池化层不管怎么说或多或少会丢掉信息甚至是重要信息)。
逆图形法
计算机图形学是基于几何数据内部的分层表示来构造可视图像,其结构考虑到了对象的相对位置,几何化的对象间的相对位置关系和朝向以矩阵表示,特定的软件接受这些表示作为输入并将它们转化为屏幕上的图像(渲染)。
Hinton受此启发,认为大脑所做的和渲染正好相反,称为逆图形,从眼睛接受的视觉信息中,大脑解析出其所在世界的分层表示,并尝试匹配学习到的模式和存储在大脑中的关系,从而有了辨识,注意到,大脑中的物体表示并不依赖视角。
因此,现在要考虑的是如何在神经网络中建模这些分层关系。在计算机图形学中,三维图形中的三维对象之间的关系可以用位姿表示,位姿的本质是平移和旋转。Hinton提出,保留对象部件之间的分层位姿关系对于正确分类和辨识对象来说很重要。胶囊网络结合了对象之间的相对关系,在数值上表示为4维位姿矩阵。当模型有了位姿信息之后,可以很容易地理解它看到的是以前看到的东西而只是改变了视角而已。如下图,人眼可以很容易分辨出是自由女神像,只是角度的不同,但CNN却很难做到,而把位姿信息集合进去的胶囊网络,也可以判别出是自由女神像的不同角度。

胶囊网络优点
由于胶囊网络集合了位姿信息,因此其可以通过一小部分数据即学习出很好的表示效果,所以这一点也是相对于CNN的一大提升。举个例子,为了识别手写体数字,人脑需要几十个最多几百个例子,但是CNN却需要几万规模的数据集才能训练出好结果,这显然还是太暴力了!
更加贴近人脑的思维方式,更好地建模神经网络中内部知识表示的分层关系,胶囊背后的直觉非常简单优雅。
胶囊网络缺点
胶囊网络的当前实现比其他现代深度学习模型慢很多(我觉得是更新耦合系数以及卷积层叠加影响的),提高训练效率是一大挑战。
研究内容
胶囊是什么
摘抄Hinton等人的《Transforming Autoencoders》关于胶囊概念理解如下。
人工神经网络不应当追求“神经元”活动中的视角不变性(使用单一的标量输出来总结一个局部池中的重复特征检测器的活动),而应当使用局部的“胶囊”,这些胶囊对其输入执行一些相当复杂的内部计算,然后将这些计算的结果封装成一个包含信息丰富的输出的小向量。每个胶囊学习辨识一个有限的观察条件和变形范围内隐式定义的视觉实体,并输出实体在有限范围内存在的概率及一组“实例参数”,实例参数可能包括相对这个视觉实体的隐式定义的典型版本的精确的位姿、照明条件和变形信息。当胶囊工作正常时,视觉实体存在的概率具有局部不变性——当实体在胶囊覆盖的有限范围内的外观流形上移动时,概率不会改变。实例参数却是“等变的”——随着观察条件的变化,实体在外观流形上移动时,实例参数也会相应地变化,因为实例参数表示实体在外观流形上的内在坐标。
简单来说,可以理解成:
人造神经元输出单个标量。卷积网络运用了卷积核从而使得将同个卷积核对于二维矩阵的各个区域计算出来的结果堆叠在一起形成了卷积层的输出。
通过最大池化方法来实现视角不变性,因为最大池持续搜寻二维矩阵的区域,选取区域中最大的数字,所以满足了我们想要的活动不变性(即我们略微调整输入,输出仍然一样),换句话说,在输入图像上我们稍微变换一下我们想要检测的对象,模型仍然能够检测到对象
池化层损失了有价值的信息,同时也没有考虑到编码特征间的相对空间关系,因此我们应该使用胶囊,所有胶囊检测中的特征的状态的重要信息,都将以向量形式被胶囊封装(神经元是标量)
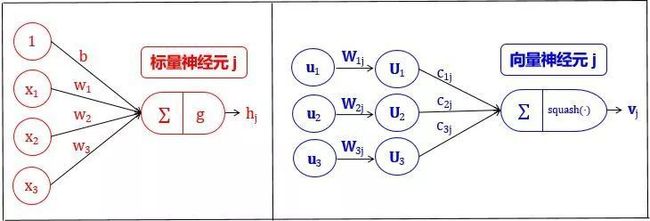
胶囊和人工神经元对比如下:

囊间动态路由算法
低层胶囊i 需要决定如何将其输出向量发送给高层胶囊j 。低层胶囊改变标量权重cij ,输出向量乘以该权重后,发送给高层胶囊,作为高层胶囊的输入。关于权重cij ,需要知道有:
权重均为非负标量
对每个低层胶囊i 而言,所有权重cij 的总和等于1
对每个低层胶囊i 而言,权重的数量等于高层胶囊的数量
这些权重由迭代动态路由算法确定
低层胶囊将其输出发送给对此表示“同意”的高层胶囊,算法伪码如下:

权重更新可以用如下图来直观理解。
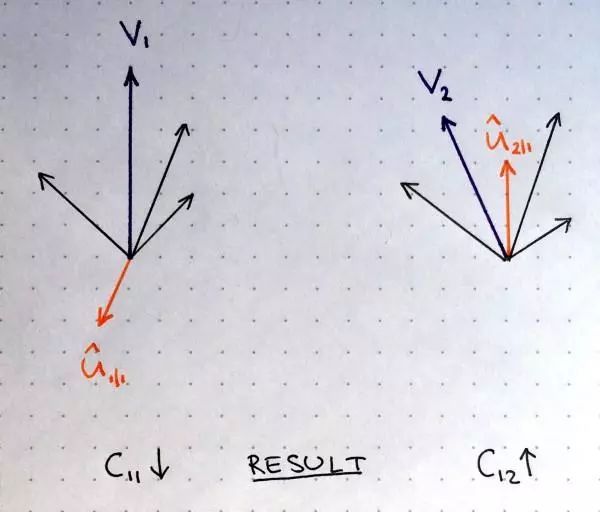
其中两个高层胶囊的输出用紫色向量 v1 和 v2 表示,橙色向量表示接受自某个低层胶囊的输入,其他黑色向量表示接受其他低层胶囊的输入。左边的紫色输出 v1 和橙色输入 u1|1 指向相反的方向,所以它们并不相似,这意味着它们点积是负数,更新路由系数的时候将会减少 c11 。右边的紫色输出 v2 和橙色输入 u2|1 指向相同方向,它们是相似的,因此更新参数的时候路由系数 c12 会增加。在所有高层胶囊及其所有输入上重复应用该过程,得到一个路由参数集合,达到来自低层胶囊的输出和高层胶囊输出的最佳匹配。
采用多少次路由迭代?论文在MNIST和CIFAR数据集上检测了一定范围内的数值,得到以下结论:
更多的迭代往往会导致过拟合
实践中建议使用3次迭代
整体框架
CapsNet由两部分组成:编码器和解码器。前3层是编码器,后3层是解码器:
第一层:卷积层
第二层:PrimaryCaps(主胶囊)层
第三层:DigitCaps(数字胶囊)层
第四层:第一个全连接层
第五层:第二个全连接层
第六层:第三个全连接层
编码器
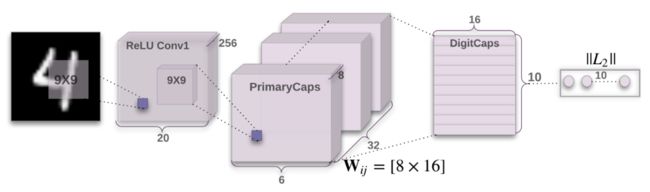
编码器接受一张28×28的MNIST数字图像作为输入,将它编码为实例参数构成的16维向量。
卷积层
输入:28×28图像(单色)
输出:20×20×256张量
卷积核:256个步长为1的9×9×1的核
激活函数:ReLU
PrimaryCaps层(32个胶囊)
输入:20×20×256张量
输出:6×6×8×32张量(共有32个胶囊)
卷积核:8个步长为1的9×9×256的核/胶囊
DigitCaps层(10个胶囊)
输入:
6×6×8×32张量
输出:
16×10矩阵
损失函数

解码器
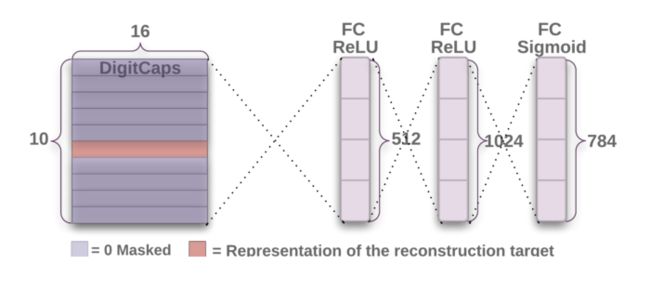
解码器从正确的DigitCap中接受一个16维向量,并学习将其编码为数字图像(注意,训练时候只采用正确的DigitCap向量,而忽略不正确的DigitCap)。解码器用来作为正则子,它接受正确的DigitCap的输出作为输入,重建一张28×28像素的图像,损失函数为重建图像和输入图像之间的欧式距离。解码器强制胶囊学习对重建原始图像有用的特征,重建图像越接近输入图像越好,下面展示重建图像的例子。

第一个全连接层
输入:16×10矩阵
输出:512向量
第二个全连接层
输入:512向量
输出:1024向量
第三个全连接层
输入:1024向量
输出:784向量
参考资料
https://mp.weixin.qq.com/s?__biz=MzI3ODkxODU3Mg==&mid=2247484099&idx=1&sn=97e209f1a9860c8d8c51e81d98fc8a0a&chksm=eb4ee600dc396f16624a33cdfc0ead905e62ae9447b49b20146020e6cbd7d71f089101512a40&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzI3ODkxODU3Mg==&mid=2247484165&idx=1&sn=0ca679e3a5f499f8d8addb405fe3df83&chksm=eb4ee7c6dc396ed0a330fcac12690110bcaf9a8a10794dbc5e1a326c69ecbb140140f55fd6ba&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzI3ODkxODU3Mg==&mid=2247484433&idx=1&sn=3afe4605bc2501eebbc41c6dd1af9572&chksm=eb4ee0d2dc3969c4619d6c1097d5c949c76c6c854e60d36eba4388da2c3855747818d062c90a&scene=21#wechat_redirect
https://mp.weixin.qq.com/s/6CRSen8P6zKaMGtX8IRfqw
原文链接:
https://www.cnblogs.com/CZiFan/p/9803067.html
“哪吒头”—玩转小潮流