行为识别之双流卷积网络
1、简介
从视频中进行行为识别,其挑战在于从静止帧捕获关于外观和帧间运动的补充信息。
贡献有三:a. 结合了时空信息 b. 多帧密集光流有助于性能提高 c. 多任务学习可用于增加训练数据量
该网络在 UCF-101 and HMDB-51两数据集上具有较好性能表现。
相比静态图像分类,视频的时序成分为行为识别提供了额外的线索(运动信息),并且视频本身对每帧图像具有天然的数据增强功能(帧间抖动)。
时空双流网络分别独立地使用静态图像帧与帧间密集光流进行识别,最后进行一个结果融合。双流的解耦使空间流可以利用ImageNet预训练。
2、双流网络架构
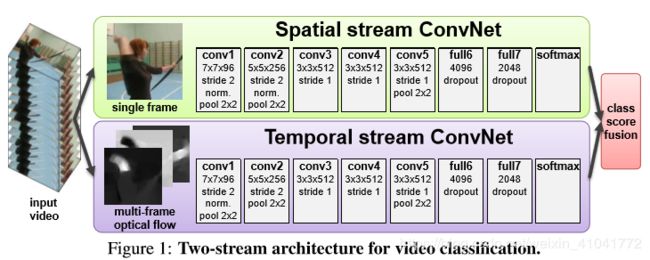
双流分别为深度卷积网络,最后将两个分支softmax分数进行融合。融合方法为平均或者训练以堆叠的L2标准化的softmax分数作为特征的多类别线性SVM。
3、光流神经网络
时序识别网络流的输入是通过堆叠几个连续视频帧的光流位移场形成,其光流信息有几种变体选择:

3.1 输入网络的配置
(1)光流堆叠:
密集光流可以描述为连续的多个的相邻两帧的位移矢量场的集合,并将矢量场分解为水平垂直两个方向成分,并将其作为两个通道的特征,为了表示一系列的帧间运动,本文堆叠了L帧的相邻帧的位移场组成2L通道的输入特征。
![]() 表示网络的输入特征。
表示网络的输入特征。
(2)运动轨迹堆叠:
光流堆叠形式的输入只是描述了相对于下一帧相对于上一帧的某一个固定点(u,v)的位移矢量,而轨迹堆叠描述的是上一帧的点位移之后的下一帧的点的位移矢量,多帧之间以此类推。
如下为轨迹堆叠的位移矢量描述公式:

![]()
以下是光流堆叠与轨迹堆叠的特征图对比:

(3)双向光流
即在正向的基础上,添加一反向的帧间位移场集合。本文采用的方法是在连续的L帧视频帧间构建光流表示,前L/2帧使用前向光流,后L/2使用反向光流。如此堆叠仍是一2L通道特征表示。光流表示可以使用上面的两种方法。
(4)减平均光流(0中心化)
普遍认为,对网络的输入采用0中心化可以使得模型更好地使用矫正非线性,当然就跨越大量运动而言,本模型的光流可以表现为正值与负值,自然地0中心的,即运动方向在正反方向的概率是等同的。由于两帧之间的光流是包含着相机运动位移的,在论文[10,26]中,强调了相机全局运动的重要性,故需要估计相机的运动并将其从光流中减除,而在本文,采用将光流减去均值的方法,进而缓解相机运动的影响。
(5)网络架构
两个流分支采用相同拓扑,光流分支输入特征为224*224*2L(某一帧)。
3.2 时序网络分支与相关前人工作关于视频表示的联系
特征的局部描述子多基于HOG或者HOF。双HMAX 流视频分类架构 是手工设计的特征,具有较少的层。卷积模型[12,14]没有将时空流进行解耦,而是依赖运动敏感卷积核从数据进行提取。本文是采用光流位移场明显地表示运动,是基于光流强度与光滑度的连续设想计算的。此设想应用于端到端的网络能够增强网络性能。
4、多任务学习解决多个小数据集训练
目的是学习一个可应用于多个数据集(HMDB-51 classification, UCF-101 classification)的抽象视频特征表示,网络修改为在最后的全连接层上接两个softmax分类层,作为两个数据集的独自分类。最后的损失即为两个损失之和。
5、实验实现细节
训练:训练过程可以看做是[15]的改编。权重学习使用随机梯度下降, momentum =0.9, mini-batch =256(256个视频片段,每个视频随机选择一帧)。初始学习率设置为0.01,根据固定的训练日程进行减少,50K次迭代时降为0.001,70K时降为0.0001,80K时停止。微调时,14K时改为0.001,20K时结束。
空间网络训练:选择的视频帧(256*256)随机裁剪224*224,然后进行随机抖动与水平翻转。当然视频是提前缩放好的,最小边为256。
时间网络训练:对选定的视频帧计算其光流表示I, 224×224×2L 的表示也是随机裁剪与翻转。
测试:对于一个视频,均匀地采集固定的25帧,对每一帧采用四角的裁剪与水平翻转以及中间裁剪,生成10帧输入,最后的分类结果是将25帧的结果取平均。
预训练及光流计算:
