2019移动广告反欺诈算法挑战赛之初始数据分析
前言:
最近参加的科大讯飞的2019移动广告反欺诈算法挑战赛,但是白天一直在忙着写论文,所以一直是跑跑别人的公开的baseline,调调参数一类的,现在是94.43左右,有需要的可以和我说一下,免费奉献。但是感觉成长不是很大,所以就学学kaggle上的一个大佬分析数据的方式很有意思,就拿过来学学。比猫画虎而已,肯定有些不对的。程序是用jupyter写的,但是CSDN不是很支持jupyter,所以每一段重要的程序前面,我会做个简单的分析的。

![]()
重要通知:
catboost版本会对结果有影响,所以建议使用0.15.2的版本。
安装方法:pip install catboost==0.15.2
查看版本的命令: pip2 list
第一: 数据的基本信息
设置最大显示的列数,以及定义一些画图的包
# 移动广告反欺诈算法挑战赛 简单的数据分析
# pandas中describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)
import pandas as pd # 读取数据集
import numpy as np # 展示全部列的数据
pd.set_option('display.max_columns', 1000)
from datetime import timedelta, datetime # 处理时间戳数据
import time
import matplotlib.pyplot as plt # 用于画图程序
import seaborn as sns
%matplotlib inline
sns.set(rc={'figure.figsize':(20,5)});
plt.figure(figsize=(20,5));# 读取数据集
# 读取数据集
train = pd.read_table("data/traindata.txt")
test = pd.read_table("data/testdata.txt")# 显示一下数据的基本信息 我们可以看到数据集中含有缺失值的属性有 city lan make model osv ver 分别表示 城市 语言 厂商 机型 操作系统版本 app版本, 我看所给的baseline中并没有对缺失值进行处理,所以我在baseline中对缺失值进行填充。
填充代码为: all_data['city'] = all_data['city'].fillna(method='pad')
# 显示一下数据的信息
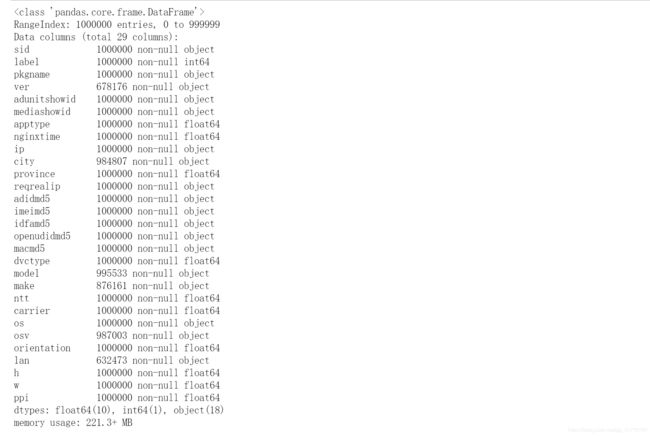
train.head(5)
train.info()
train.describe()
定义数据集中属性列的相关变量
variables = ['pkgname', 'ver', 'adunitshowid', 'mediashowid', 'apptype', 'ip',
'reqrealip', 'city', 'province', 'adidmd5', 'imeimd5', 'idfamd5',
'openudidmd5', 'macmd5', 'dvctype', 'model', 'make', 'ntt',
'carrier', 'os', 'osv', 'orientation', 'lan', 'h', 'w', 'ppi']
# 接下来我们统计一下数据集中,每个属性的的唯一值是多少?其实我看的baseline统计了的特征大多是每个属性中唯一值的个数,以及对结果进行排序。其实我想如果是这样的话,在训练数据中也可以增加一个特征,每一个属性值占总体的比例也可以试一下的。从结果中我们可以看到几个比较显著的特点:
第一: 有几个属性的唯一值比较的少,例如: 省 dvctype(设备类型) 厂商一类的
第二: 出现唯一值比较多的几个属性有, IP地址 {(Adroid ID的MD5值) mac的MD5值} 这两个属性可以表示是苹果设备还是安安卓设备。 imei的MD5值 (这个属性就不知道是啥意思了)
第三:如果统计os的唯一值出现的次数的话,那么这一列的属性值就会很大,应该10万级别的,所以可不可以使用log以下结果。使得数据集中属性列之间的值差距不是很大。
plt.figure(figsize=(10, 6))
plt.xticks(rotation=90,fontsize=12)
uniques = [len(train[col].unique()) for col in variables]
sns.set(font_scale=1.2)
ax = sns.barplot(variables, uniques, log=True)
ax.set(xlabel='feature', ylabel='unique count of each feature', title='Number of unique values for each feature')
for p, uniq in zip(ax.patches, uniques):
height = p.get_height()
ax.text(p.get_x()+p.get_width()/2.,
height + 10,
uniq,
ha="center")

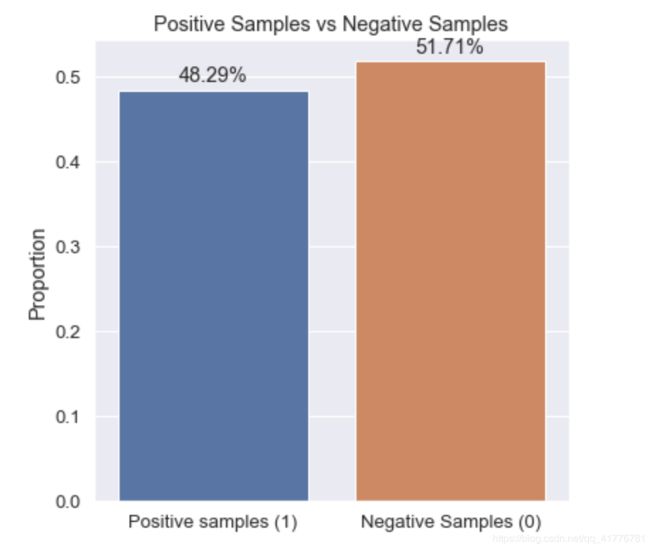
# 接下来我们统计一下数据集中目标标签出现的次数,看看是否出现正负样本差距较大的情况,如果出现需要对数据进行重采样。我们看到数据集中作弊的数量占48%, 而负样本占52%。 所以不需要我们执行重采样。
plt.figure(figsize=(6,6))
#sns.set(font_scale=1.2)
mean = (train.label.values == 1).mean()
ax = sns.barplot(['Positive samples (1)', 'Negative Samples (0)'], [mean, 1-mean])
ax.set(ylabel='Proportion', title='Positive Samples vs Negative Samples')
for p, uniq in zip(ax.patches, [mean, 1-mean]):
height = p.get_height()
ax.text(p.get_x()+p.get_width()/2.,
height+0.01,
'{}%'.format(round(uniq * 100, 2)),
ha="center")
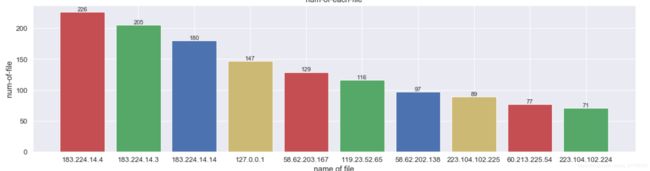
# 根据我们收集的资料我们可以知道对于是否作弊而言,IP地址应该是一个强特征,okay咱们开始分析一下IP地址和目标标签之间的关系。首先咱们先统计一下数据集中ip地址出现的次数。然后画图展示一下IP地址出现次数的大致分布。最后咱们分析一下IP地址和目标标签之间的关系。
IP地址出现的次数
temp = train['ip'].value_counts().reset_index(name='counts')
temp.columns = ['ip', 'counts']
import matplotlib.pyplot as plt
import sys
print('数据集中前temp的值', type(temp))
name = list(temp['ip'].iloc[0:10])
num = list(temp['counts'].iloc[0:10])
plt.bar(name, num, color='rgby')
plt.xlabel('name of file')
plt.ylabel("num-of-file")
plt.title("num-of-each-file")
for a, b in zip(name, num):
plt.text(a, b, '%.0f' % b, ha='center', va='bottom', fontsize=11)
plt.show()
IP地址出现的次数大多都是一次,最高的才出现了200多次,这个可以作为最后的新的特征。上面我们可以看到向os这样的属性值中,每一个属性可能出现上万次,然后在我们ip地址才出现200, 所以统计特征的时候是否有必要所有的特征都统计出现次数,我感觉是个问题。
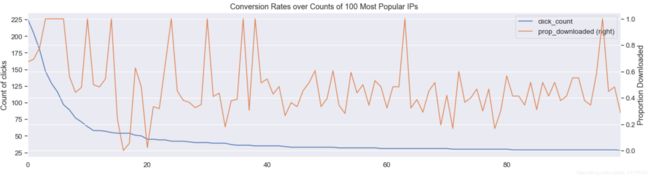
IP地址出现的次数和是否下载之间的关系。蓝色先表示的某个IP地址的出现的次数,黄色的线表示数据中出现的次数作弊率还是挺高的,所以我感觉IP地址应该是个相对不错的特征对于这个模型。但是还是有疑问的。
# 将原始数据中的标签转化成int型数据
train['label']=train['label'].astype(int)proportion = train[['ip', 'label']].groupby('ip', as_index=False).mean().sort_values('label', ascending=False)
counts = train[['ip', 'label']].groupby('ip', as_index=False).count().sort_values('label', ascending=False)
merge = counts.merge(proportion, on='ip', how='left')
merge.columns = ['ip', 'click_count', 'prop_downloaded']
ax = merge[:100].plot(secondary_y='prop_downloaded')
plt.title('Conversion Rates over Counts of 100 Most Popular IPs')
ax.set(ylabel='Count of clicks')
plt.ylabel('Proportion Downloaded')
plt.show()
print('Counversion Rates over Counts of Most Popular IPs')
print(merge[:20])
同样的方式还可以用到其他的属性列的分析上。暂时不讲了,下一节有时间的话,我谈一下时间数据的应用。这个我看公开的源码上都没有做。早点睡觉了。ZZZZZZZZZZZZZZZZZZZ