TensorFlow学习指南6:词向量
word2vec
# -*- coding: utf-8 -*-
"""
Created on Thu Dec 29 00:39:23 2016
@author: tomhope
"""
import os
import math
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 64
embedding_dimension = 5
negative_samples = 8
LOG_DIR = "logs/word2vec_intro"
digit_to_word_map = {1: "One", 2: "Two", 3: "Three", 4: "Four", 5: "Five",
6: "Six", 7: "Seven", 8: "Eight", 9: "Nine"}
sentences = []
# Create two kinds of sentences - sequences of odd and even digits.
for i in range(10000):
rand_odd_ints = np.random.choice(range(1, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints]))
rand_even_ints = np.random.choice(range(2, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints]))
# Map words to indices
word2index_map = {}
index = 0
for sent in sentences:
for word in sent.lower().split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
# Generate skip-gram pairs
skip_gram_pairs = []
for sent in sentences:
tokenized_sent = sent.lower().split()
for i in range(1, len(tokenized_sent)-1):
word_context_pair = [[word2index_map[tokenized_sent[i-1]],
word2index_map[tokenized_sent[i+1]]],
word2index_map[tokenized_sent[i]]]
skip_gram_pairs.append([word_context_pair[1],
word_context_pair[0][0]])
skip_gram_pairs.append([word_context_pair[1],
word_context_pair[0][1]])
def get_skipgram_batch(batch_size):
instance_indices = list(range(len(skip_gram_pairs)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [skip_gram_pairs[i][0] for i in batch]
y = [[skip_gram_pairs[i][1]] for i in batch]
return x, y
# batch example
x_batch, y_batch = get_skipgram_batch(8)
print(x_batch)
print(y_batch)
[index2word_map[word] for word in x_batch]
[index2word_map[word[0]] for word in y_batch]
# Input data, labels
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
# Embedding lookup table currently only implemented in CPU
with tf.name_scope("embeddings"):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_dimension],
-1.0, 1.0), name='embedding')
# This is essentialy a lookup table
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Create variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_dimension],
stddev=1.0 / math.sqrt(embedding_dimension)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights, biases=nce_biases, inputs=embed, labels=train_labels,
num_sampled=negative_samples, num_classes=vocabulary_size))
tf.summary.scalar("NCE_loss", loss)
# Learning rate decay
global_step = tf.Variable(0, trainable=False)
learningRate = tf.train.exponential_decay(learning_rate=0.1,
global_step=global_step,
decay_steps=1000,
decay_rate=0.95,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(LOG_DIR,
graph=tf.get_default_graph())
saver = tf.train.Saver()
with open(os.path.join(LOG_DIR, 'metadata.tsv'), "w") as metadata:
metadata.write('Name\tClass\n')
for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embeddings.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
projector.visualize_embeddings(train_writer, config)
tf.global_variables_initializer().run()
for step in range(1000):
x_batch, y_batch = get_skipgram_batch(batch_size)
summary, _ = sess.run([merged, train_step],
feed_dict={train_inputs: x_batch,
train_labels: y_batch})
train_writer.add_summary(summary, step)
if step % 100 == 0:
saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)
loss_value = sess.run(loss,
feed_dict={train_inputs: x_batch,
train_labels: y_batch})
print("Loss at %d: %.5f" % (step, loss_value))
# Normalize embeddings before using
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
normalized_embeddings_matrix = sess.run(normalized_embeddings)
ref_word = normalized_embeddings_matrix[word2index_map["one"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10]
for f in ff:
print(index2word_map[f])
print(cosine_dists[f])tensorboard --logdir=./logs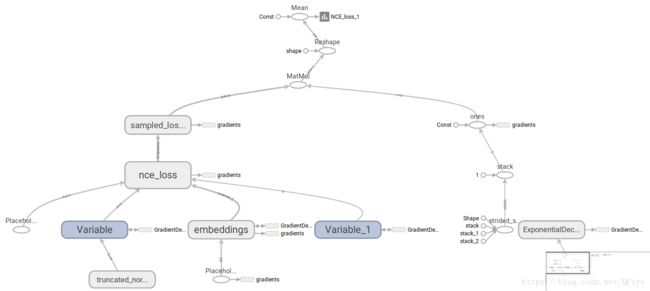
嵌入投影演示http://projector.tensorflow.org
预训练词嵌入,高级RNN
https://nlp.stanford.edu/projects/glove/
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 1 12:18:27 2017
@author: tomhope
"""
import zipfile
import numpy as np
import tensorflow as tf
path_to_glove = "glove.840B.300d.zip"
PRE_TRAINED = True
GLOVE_SIZE = 300
batch_size = 128
embedding_dimension = 64
num_classes = 2
hidden_layer_size = 32
times_steps = 6
digit_to_word_map = {1: "One", 2: "Two", 3: "Three", 4: "Four", 5: "Five",
6: "Six", 7: "Seven", 8: "Eight", 9: "Nine"}
digit_to_word_map[0] = "PAD_TOKEN"
even_sentences = []
odd_sentences = []
seqlens = []
for i in range(10000):
rand_seq_len = np.random.choice(range(3, 7))
seqlens.append(rand_seq_len)
rand_odd_ints = np.random.choice(range(1, 10, 2),
rand_seq_len)
rand_even_ints = np.random.choice(range(2, 10, 2),
rand_seq_len)
if rand_seq_len < 6:
rand_odd_ints = np.append(rand_odd_ints,
[0]*(6-rand_seq_len))
rand_even_ints = np.append(rand_even_ints,
[0]*(6-rand_seq_len))
even_sentences.append(" ".join([digit_to_word_map[r]
for r in rand_odd_ints]))
odd_sentences.append(" ".join([digit_to_word_map[r]
for r in rand_even_ints]))
data = even_sentences+odd_sentences
# same seq lengths for even, odd sentences
seqlens *= 2
labels = [1]*10000 + [0]*10000
for i in range(len(labels)):
label = labels[i]
one_hot_encoding = [0]*2
one_hot_encoding[label] = 1
labels[i] = one_hot_encoding
word2index_map = {}
index = 0
for sent in data:
for word in sent.split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
def get_glove(path_to_glove, word2index_map):
embedding_weights = {}
count_all_words = 0
with zipfile.ZipFile(path_to_glove) as z:
with z.open("glove.840B.300d.txt") as f:
for line in f:
vals = line.split()
word = str(vals[0].decode("utf-8"))
if word in word2index_map:
print(word)
count_all_words += 1
coefs = np.asarray(vals[1:], dtype='float32')
coefs /= np.linalg.norm(coefs)
embedding_weights[word] = coefs
if count_all_words == len(word2index_map) - 1:
break
return embedding_weights
word2embedding_dict = get_glove(path_to_glove, word2index_map)
embedding_matrix = np.zeros((vocabulary_size, GLOVE_SIZE))
for word, index in word2index_map.items():
if not word == "PAD_TOKEN":
word_embedding = word2embedding_dict[word]
embedding_matrix[index, :] = word_embedding
data_indices = list(range(len(data)))
np.random.shuffle(data_indices)
data = np.array(data)[data_indices]
labels = np.array(labels)[data_indices]
seqlens = np.array(seqlens)[data_indices]
train_x = data[:10000]
train_y = labels[:10000]
train_seqlens = seqlens[:10000]
test_x = data[10000:]
test_y = labels[10000:]
test_seqlens = seqlens[10000:]
def get_sentence_batch(batch_size, data_x,
data_y, data_seqlens):
instance_indices = list(range(len(data_x)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [[word2index_map[word] for word in data_x[i].split()]
for i in batch]
y = [data_y[i] for i in batch]
seqlens = [data_seqlens[i] for i in batch]
return x, y, seqlens
_inputs = tf.placeholder(tf.int32, shape=[batch_size, times_steps])
embedding_placeholder = tf.placeholder(tf.float32, [vocabulary_size,
GLOVE_SIZE])
_labels = tf.placeholder(tf.float32, shape=[batch_size, num_classes])
_seqlens = tf.placeholder(tf.int32, shape=[batch_size])
if PRE_TRAINED:
embeddings = tf.Variable(tf.constant(0.0, shape=[vocabulary_size, GLOVE_SIZE]),
trainable=True)
# if using pre-trained embeddings, assign them to the embeddings variable
embedding_init = embeddings.assign(embedding_placeholder)
embed = tf.nn.embedding_lookup(embeddings, _inputs)
else:
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size,
embedding_dimension],
-1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, _inputs)
with tf.name_scope("biGRU"):
with tf.variable_scope('forward'):
gru_fw_cell = tf.contrib.rnn.GRUCell(hidden_layer_size)
gru_fw_cell = tf.contrib.rnn.DropoutWrapper(gru_fw_cell)
with tf.variable_scope('backward'):
gru_bw_cell = tf.contrib.rnn.GRUCell(hidden_layer_size)
gru_bw_cell = tf.contrib.rnn.DropoutWrapper(gru_bw_cell)
outputs, states = tf.nn.bidirectional_dynamic_rnn(cell_fw=gru_fw_cell,
cell_bw=gru_bw_cell,
inputs=embed,
sequence_length=_seqlens,
dtype=tf.float32,
scope="biGRU")
states = tf.concat(values=states, axis=1)
weights = {
'linear_layer': tf.Variable(tf.truncated_normal([2*hidden_layer_size,
num_classes],
mean=0, stddev=.01))
}
biases = {
'linear_layer': tf.Variable(tf.truncated_normal([num_classes],
mean=0, stddev=.01))
}
# extract the final state and use in a linear layer
final_output = tf.matmul(states,
weights["linear_layer"]) + biases["linear_layer"]
softmax = tf.nn.softmax_cross_entropy_with_logits(logits=final_output,
labels=_labels)
cross_entropy = tf.reduce_mean(softmax)
train_step = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(_labels, 1),
tf.argmax(final_output, 1))
accuracy = (tf.reduce_mean(tf.cast(correct_prediction,
tf.float32)))*100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(embedding_init,
feed_dict={embedding_placeholder: embedding_matrix})
for step in range(1000):
x_batch, y_batch, seqlen_batch = get_sentence_batch(batch_size,
train_x, train_y,
train_seqlens)
sess.run(train_step, feed_dict={_inputs: x_batch, _labels: y_batch,
_seqlens: seqlen_batch})
if step % 100 == 0:
acc = sess.run(accuracy, feed_dict={_inputs: x_batch,
_labels: y_batch,
_seqlens: seqlen_batch})
print("Accuracy at %d: %.5f" % (step, acc))
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings),
1, keep_dims=True))
normalized_embeddings = embeddings / norm
normalized_embeddings_matrix = sess.run(normalized_embeddings)
for test_batch in range(5):
x_test, y_test, seqlen_test = get_sentence_batch(batch_size,
test_x, test_y,
test_seqlens)
batch_pred, batch_acc = sess.run([tf.argmax(final_output, 1), accuracy],
feed_dict={_inputs: x_test,
_labels: y_test,
_seqlens: seqlen_test})
print("Test batch accuracy %d: %.5f" % (test_batch, batch_acc))
ref_word = normalized_embeddings_matrix[word2index_map["Three"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10]
for f in ff:
print(index2word_map[f])
print(cosine_dists[f])