Secure Federated Transfer Learning(论文笔记)
论文链接:https://arxiv.org/pdf/1812.03337.pdf
一、概述
众所周知,机器学习依靠大量用于训练的数据。然而,在现实中存在的数据存在以下特点:
- 数据分散(各行各业都有自己的一些客户数据,但是这些数据量又太少,训练出来的模型表现很差)
- 数据质量差(拥有的这些数据中存在着少标签甚至无标签的情况,而对这些数据作标签处理需要很昂贵的代价,尤其是在某些专业领域对数据进行分类)
- 企业不愿暴漏数据(数据对一个企业来说是十分重要的,企业并不愿意将它的隐私暴漏给其他企业)
- 法律对数据隐私的约束(企业间不能够直接地进行数据共享)
而在这篇论文中引入了一种新的技术和框架,称为联邦迁移学习(FTL),它允许在不损害用户隐私的情况下进行知识共享,并且允许在网络中传送互补知识,并且可以利用源域大量有标注的数据实现目标域模型的训练。
框架特点:只需在现有模型上进行少量修改,十分灵活高效,能够很好地应用于各种安全地多方机器学习任务
二、简介
-
背景
Recent Artificial Intelligence (AI) achievements have been depending on the availability of massive amount of labeled data. AlphaGo (Silver et al. 2016) uses 30 millions of moves from 160,000 actual games.The ImageNet dataset (Deng et al. 2009) has over 14 million images.
人工智能在大量有标签地数据下发展地迅速,但是现实中
- 数据质量差(垃圾数据, 数据少标签,数据无标签)
- 数据分散
- 数据隐私保护的需要
使得对数据进行联合变得十分困难
而绝大多数企业只拥有很有限的数据量(few samples and features),甚至有些企业只是持有未标注的数据,数据的质量差,可利用性不强,对于数据依赖性极强的AI模型的训练极为不利。
Google first introduced a federated learning (FL) system (McMahan et al. 2016) in which a global machine learning model is updated by a federation of distributed participants while keeping their data locally
解决方案:谷歌首次引入了联邦学习系统,在数据保留在本地的情况下,多个参与者共同训练,对本地训练结果进行加密并上传模型更新参数到服务器,由这些更新的结果对全局模型进行训练,然后服务器返回训练结果。这样既为数据隐私提供了保证,又能够有多方数据共同参与训练模型,使得模型表现更好。
缺点:这种联邦学习框架局限于参与者提供的数据必须是具有相同特征或者相同样本的情况。
理想很丰满,现实很骨感
In reality. however, the set of common entities could be small, making a federation less attractive and leaving the majority non-overlapping data undermined.
于是论文提出了可行的解决方案: Federataion Transfer Learning(FTL)
Main contributions:
We introduce federated transfer learning in a privacy-preserving setting to provide solutions for federation problems beyond the scope of existing federated learning approaches;
- 在保护隐私的情况下引入了联邦迁移学习来解决当前联邦学习的局限
We provide an end-to-end solution to the proposed FTL problem and show that convergence and accuracy of the proposed approach is comparable to the non-privacy-preserving approach;
- 对提出的FTL问题提供了一个端到端的解决方案,并且使用该方法训练的模型精度和收敛性能够媲美无隐私保护下的训练方法
We provide a novel approach for adopting additively homomorphic encryption (HE) to multi-party computation (MPC) with neural networks such that only minimal modifications to the neural network is required and the accuracy is almost lossless, whereas most of the existing secure deep learning frameworks suffer from loss of accuracy when adopting privacy-preservingtechniques.
- 当前存在的安全深度学习框架由于引入了隐私保护技术,在精度损失方面表现很差,而在该框架中采用同态加密技术和神经网络技术,精度损失表现更好
三、相关工作
Federated Learning and Secure Deep Learning
当前现有的一些加密隐私方案
- A secure aggregation scheme(Goolge):各联邦用户向服务器上传本地训练更新后的进行加密的参数,服务器进行安全聚 合,更新全局模型,并返回更新结果到各联邦用户
- CryptoNet:数据在经过同态加密技术(Homomorphic Encryption)再进行神经网络(Neural Network)计算
- CryptoDL:采用低阶多项式逼近神经网络中的激活函数,以减少预测的精度损失
- DeepSecure: uses Yao's Garbled Circuit Protocol for data encryption instead of HE.
- SML(安全多方计算):uses secret-sharing and Yao's Grabled Circuit for encryption and supports collaborative training for linear regression, logistic regression and neural network
- Differential Privacy(差分隐私)
Transfer Learning ------- 应用于小型数据集和弱监督的强大技术
In recent years there have been tremendous amount of research work on adopting transfer learning techniques to various fields such as image classification tasks (Zhu et al. 2010), and sentiment analysis (Pan et al. 2010;Li et al. 2017). The performance of transfer learning relies on how related the domains are. Intuitively parties in the same data federation are usually organizations from the same or related industry, therefore are more prone to knowl-
edge propagation.
近年来大量针对迁移学习的工作不断展开,例如在图像分类以及情感分析方面
迁移学习依赖于源域与目标域的相关性,通过源域来训练出目标域,相关性越强,训练出的模型效果越好
直观地说,相同数据联合中的参与方通常是来自于相同或相关行业的组织,因此更容易传播知识
Problem Definition
源域数据集:![]() ,
, ![]()
![]()
目标域数据集:![]() (即源域既有样本数据特征,以及标签,目标域仅有样本数据特征)
(即源域既有样本数据特征,以及标签,目标域仅有样本数据特征)
交叉数据集:![]()
假设数据集A中有数据集B的少部分标签:![]() ,
,![]() 表示目标域的标签数
表示目标域的标签数
- 假设所有的labels 都在A中,但是所有的推断结果同样适用于全部标签存在于B的情况
- 相同的样本ID通过采用加密技术的掩码进行隐私保护(如RSA)
- 假设A和B已知所有共享的相同样本ID,然后任务目标就是双方共同建立一个迁移学习模型来预测目标域的标签,同时要在不暴露彼此数据的条件下尽可能地对精度进行要求
Security Definition

所有参与方都是诚实但好奇的
假设一个半诚实的D,能够中断某方的数据客户端
在协议P下:
,
是在协议P下的输出
Proposed Approach
场景
隐藏A和B的表现,生成两个神经网络
,
,
,d表示隐藏层的维数
为了给目标域建立标签,引入预测函数:
在没有损失太多一般性的情况下,假设
.
例如,使用一个translator function:
,
,
由此可以写出利用当前可以获取的已标签数据集训练而来的目标函数:
其中
,
是
和
的训练参数,使
,
是
此外,为了最小化A和B之间的对齐损失(alignment loss):


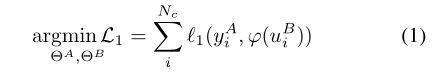


在上述假设下,为了A和B的源数据不被暴露,需要一个隐私保护方法来参与计算公式(3)和(4)
此处使用Additively Homomorphic Encryption 和 Second order Taylor approximation (二阶泰勒逼近)用于损失和梯度的计算
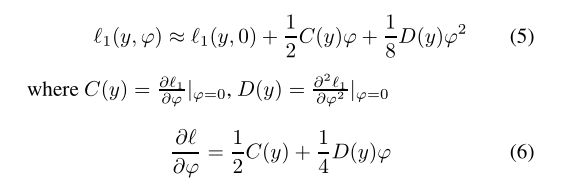

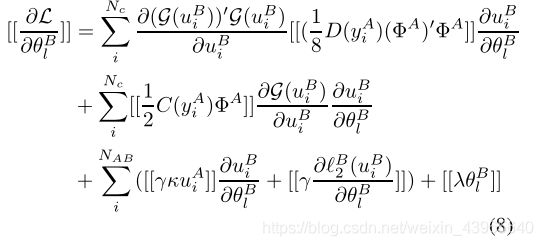
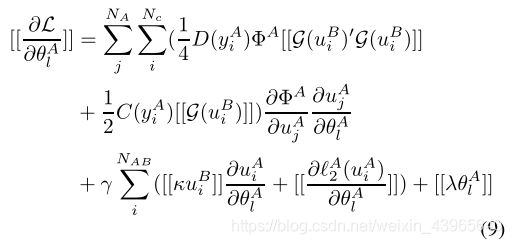
Federation Transfer Learning
Training
对于方程(7)(8)(9),设计了一个算法1
表示公钥A和公钥B的同态加密。
首先,A 方和 B 方各自初始化参数并且独立运行各自的神经网络
和
,然后A计算并且加密组件
并发送给B,从而帮助B来计算
同样的,B也执行此操作,并发送给A协助A的计算
而在最近,有大量的工作用于讨论这种方法潜在的风险,有可能会存在间接的泄漏(例如梯度)
为了防止知道A和B的梯度,A和B需要进一步地在每个梯度上用一个加密地随机值作为掩码。
接着A和B发送加密后的梯度和损失给彼此,并且得到解密值。一旦B的损失极限到达,A就可以发送终止信号,否则A和B就会解码梯度,用得到的梯度更新权值参数进行下一步的迭代。


Prediction
B利用训练好的网络参数
,发送加密的
给A,然后A评估并且用随机数进行掩码操作,并且发送加密且掩码的
给B,B进行解密并反馈给A,A获取
并获得标签,将标签发送给B

Cross Validation
将源域中的标记数据拆分为k个折叠,每次保留一个折叠数据作为测试集
将除保留的折叠数据外的数据(带标签)和
数据集用算法1进行训练得到
通过算法2预测
的标签
对B:合并预测标签:
=
对A、B: 对
用算法1训练出
,用算法2预测A方的标签(之前保留的测试集)
对A:
,评估误差
最终:
计算误差率


Security Analysis
算法1和算法2在每一次迭代执行中都会生成随机的掩码进行梯度加密,整个过程并没有暴露任何信息。
并且A在每一步中只学习了自己本身的梯度,获取的信息不足以来学习到B中的信息(因为n个方程,多于n个的参数,并不能求解),因此,只要加密是安全的,协议就是安全的。同样,A和B彼此都不能学习到对方的信息
在训练过程的最后,每一方都不注意另一方的数据结构,只获得与自身特性相关的模型参数
在推理时,双方需要协同计算预测结果
注意,该协议不处理恶意方。如果甲方伪造输入,只提交一个非零输入,它可能会告知
或者
,并且双方都不会得到正确的结果
In summary, we provide both data security and performance gain in the proposed FTL framework. Data security is provided because raw data D A andD B ,as well as the local models Net A and Net B are never exposed and only the encrypted common hidden representations are exchanged. In each iteration, the only non-encrypted values party A and party B receive are the gradients of their model parameters, which is aggregated from all sample variants. Performance gainis provided by the combinationof transfer learning, transfer cross validation and a safeguard with the self-learning supervised model.
Experiments
用了两个数据集进行了实验(data set 1: NUS-WIDE, data set 2: Default-Credit)
NUS-WIDE:一个带有网络标签标注的图像数据。
(1)来自Flickr269,648个图像和关联标签,共计5,018个唯一标签; (2)从这些图像中提取的六种类型的低级特征,包括64-D颜色直方图,144-D颜色相关图,73-D边缘方向直方图,128-D小波纹理,225-D块方式颜色矩和基于SIFT描述的500-D字包;(3)可用于评估的81个概念的校验。基于这个数据集,可以确定几个关于网络图像注释和检索的研究问题。
Deafault-Credit:由信用卡记录组成,包括用户的人口,统计特征,支付历史,账单对账单等,并以用户的默认支付为标签


![]()
Impact of Taylor approximation
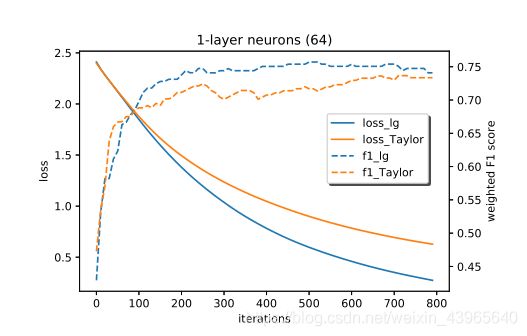
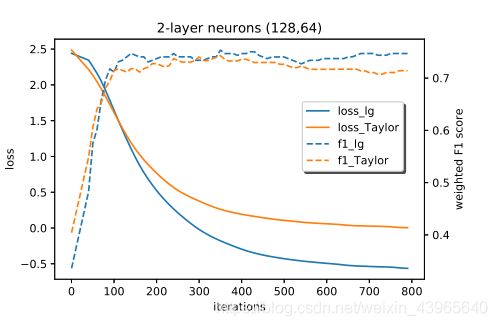
通过对训练损耗衰减和预测性能的监测和比较,研究了泰勒方法的效果,并且在本文中,使用不同深度的神经网络和全神经网络来测试算法的收敛性和精度
the first case:Net A和Net B都有一个带有64个神经元的自动编码器层
the second case:Net A和Net B都有两个带有128和64个神经元的自动编码器层
使用500个训练样本,1396个重叠对,并且
,
.训练结果如图
可以发现,将泰勒近似于全逻辑损失进行比较,加权F1分数的泰勒近似方法也与全逻辑方法进行比较,二者是十分相似的,二者的损失精度都收敛到了两个不同的最小值。当我们增加神经网络的深度时,模型的收敛性和性能不会下降
当前许多的深度学习框架在加入隐私保护技术后精度损失方面受到了很大影响。
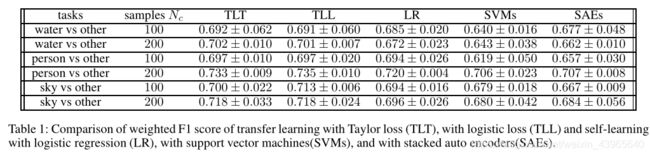
Transfer learning vs self-learning
下面是针对三个不同任务,同个任务不同样本数中一些模型权重F1分数的对比
Effect of overlapping samples and Transfer Cross Validation
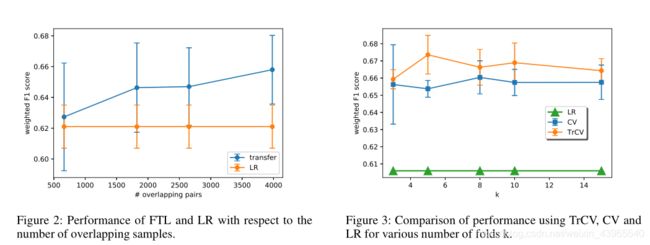
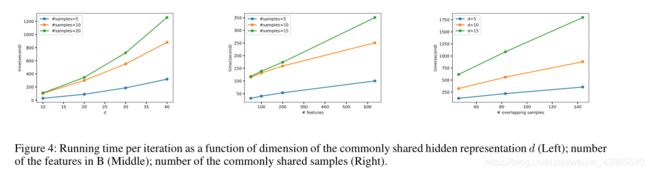
scalability
Conclusion
本文提出了联合转移学习
(FTL)框架,并将现有安全联邦学习的范围扩展到更广泛的实际应用程序。
研究结果表明,与现有的安全深度学习方法相比,安全深度学习方法具有与非隐私保护方法相同的准确性,并且具有优于非联邦自学习方法的性能。我们还提出了一种可伸缩和灵活的方法,使自同态加密适应于神经网络,同时对现有的神经网络结构进行最小的修改。该框架是一个完整的隐私保护解决方案,包括培训、评估和交叉验证。当前的框架并不局限于任何特定的学习模型,而是一个保护隐私的转移学习的通用框架。尽管如此,目前的解决方案确实存在局限性。例如,它要求仅从公共表示层交换加密的中间结果,因此并不适用于所有传输机制。FTL将来的工作包括探索并将该方法应用于其他更深层次的需要在合作中实施数据隐私保护的系统,并且通过分布式计算技术来不断提高算法的效率,找到更经济的加密方案。