Sharding-jdbc相关
最近在新金融项目中看了一下日志服务中使用的分库分表技术Sharding-jdbc,这里简要记录一下:
在新金融项目中,我们有单独建立一个日志服务,记录用户的每一步操作(如登录/查看贷款产品/查看预期还款计划等),方便日做数据分析,比如后根据用户的习惯推送一些指引消息等;当时考虑到我们的日志可能会有很多,为缓解单一数据库的性能问题,我们采用分库分表的技术,之所以选择sharding-jdbc主要从以下几个方面考虑:1.采用在 JDBC 协议层扩展分库分表,是一个以 jar 形式提供服务的轻量级组件;2.操作简单易上手,不用维护
Sharding-jdbc的模块划分:
- sharding-jdbc-core:核心模块,主要包含的是一个分库分表、读写分离的中间件的核心内容,包括规则配置、sql解析、sql改写、sql路由、sql执行、结果集合并等。
- rule:规则配置
- parsing:sql解析
- rewrite:sql改写
- routing:sql路由
- executor:sql执行
- merger:结果集合并
- jdbc:jdbc改写,项目的核心
- keygen:分布式id生成
- sharding-jdbc-orchestration:动态配置,配置中心的一些操作内容
- sharding-jdbc-orchestration-spring:配置中心的spring配置,包括一些spring和spring-boot配置文件的解析
- sharding-jdbc-spring:sharding-jdbc的spring和spring-boot配置内容解析器
- sharding-jdbc-transaction-parent:柔性事务相关内容
Sharding-jdbc的核心概念:
LogicTable
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称.
ActualTable
在分片的数据库中真实存在的物理表.
DataNode
数据分片的最小单元,由数据源名称和数据表组成.配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。如果各数据库的表结果不同,可使用ds.actual_table配置
BindingTable
指在任何场景下分片规则均一致的主表和子表,BindingTable关系的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
ShardingColumn
分片字段,用于将数据库(表)水平拆分的关键字段;SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段
ShardingAlgorithm
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等
主要步骤:
SQL解析
SQL解析作为分库分表类产品的核心,性能和兼容性是最重要的衡量指标。目前常见的SQL解析器主要有fdb/jsqlparser和Druid。Sharding-JDBC使用Druid作为SQL解析器,经实际测试,Druid解析速度是另外两个解析器的几十倍。
目前Sharding-JDBC支持join、aggregation(包括avg)、order by、 group by、limit、甚至or查询等复杂SQL的解析。目前不支持union、部分子查询、函数内分片等不太应在分片场景中出现的SQL解析。
SQL改写
SQL改写分为两部分,一部分是将分表的逻辑表名称替换为真实表名称。另一部分是根据SQL解析结果替换一些在分片环境中不正确的功能。这里具两个例子:
第1个例子是avg计算。在分片的环境中,以avg1 +avg2+avg3/3计算平均值并不正确,需要改写为(sum1+sum2+sum3)/(count1+count2+ count3)。这就需要将包含avg的SQL改写为sum和count,然后再结果归并时重新计算平均值。
第2个例子是分页。假设每10条数据为一页,取第2页数据。在分片环境下获取limit 10, 10,归并之后再根据排序条件取出前10条数据是不正确的结果。正确的做法是将分条件改写为limit 0, 20,取出所有前2页数据,再结合排序条件算出正确的数据。可以看到越是靠后的Limit分页效率就会越低,也越浪费内存。有很多方法可避免使用limit进行分页,比如构建记录行记录数和行偏移量的二级索引,或使用上次分页数据结尾ID作为下次查询条件的分页方式。
SQL路由
SQL路由是根据分片规则配置,将SQL定位至真正的数据源。主要分为单表路由、Binding表路由和笛卡尔积路由。
单表路由最为简单,但路由结果不一定落入唯一库(表),因为支持根据between和in这样的操作符进行分片,所以最终结果仍然可能落入多个库(表)。
Binding表可理解为分库分表规则完全一致的主从表。举例说明:订单表和订单详情表都根据订单ID作为分片键,任意时刻分片逻辑均相同。这样的关联查询和单表查询难度和性能相当。
笛卡尔积查询最为复杂,因为无法根据Binding关系定位分片规则的一致性,所以非Binding表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。
SQL执行
路由至真实数据源后,Sharding-JDBC将采用多线程并发执行SQL,并完成对addBatch等批量方法的处理。
结果归并
结果归并包括4类:普通遍历类、排序类、聚合类和分组类。每种类型都会先根据分页结果跳过不需要的数据。
普通遍历类最为简单,只需按顺序遍历ResultSet的集合即可。
排序类结果将结果先排序再输出,因为各分片结果均按照各自条件完成排序,所以采用归并排序算法整合最终结果。
聚合类分为3种类型,比较型、累加型和平均值型。比较型包括max和min,只返回最大(小)结果。累加型包括sum和count,需要将结果累加后返回。平均值则是通过SQL改写的sum和count计算,相关内容已在SQL改写涵盖,不再赘述。
分组类最为复杂,需要将所有的ResultSet结果放入内存,使用map-reduce算法分组,最后根据排序和聚合条件做相关处理。最消耗内存,最损失性能的部分即是此,可以考虑使用limit合理的限制分组数据大小。
springBoot集成sharding-jdbc简易实现:
1.pom.xml配置

2.数据库表/实体类/mapper:
这里共计创建8个库,每个库有8张表,通过tk.mybatis生成对应的实体类,mapper及xml文件

3.yml配置:
数据源配置,分片规则设置

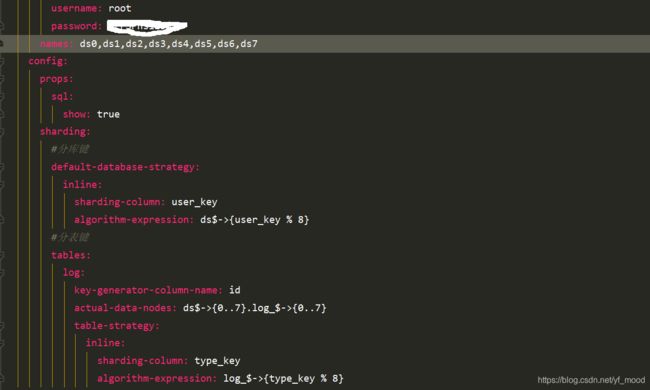
.....总计8个数据库,以user_key分库,type_key分表.
注意:行表达式标识符可以使用...或...或->{…},但前者与Spring本身的属性文件占位符冲突,因此在Spring环境中使用行表达式标识符建议使用$→{…}
4.主键问题:
分库分表的数据表不能用自增主键,Sharding-JDBC会自动分配一个id,默认使用雪花算法(snowflake)生成64bit的长整型数据

5.测试及日志查看:
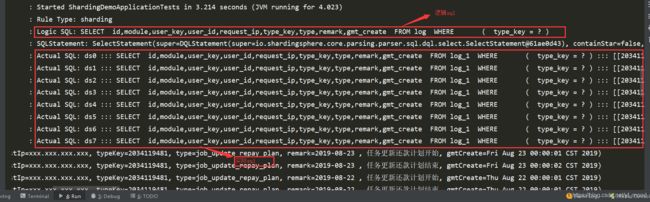
至此,简单的实现已完成!
附:
Sharding-JDBC不支持的项
DataSource接口
- 不支持timeout相关操作
Connection接口
- 不支持存储过程,函数,游标的操作
- 不支持执行native的SQL
- 不支持savepoint相关操作
- 不支持Schema/Catalog的操作
- 不支持自定义类型映射
Statement和PreparedStatement接口
- 不支持返回多结果集的语句(即存储过程,非SELECT多条数据)
- 不支持国际化字符的操作
对于ResultSet接口
- 不支持对于结果集指针位置判断
- 不支持通过非next方法改变结果指针位置
- 不支持修改结果集内容
- 不支持获取国际化字符
- 不支持获取Array
官网:https://shardingsphere.apache.org/document/current/cn/features/