Titanic: Machine Learning from Disaster初练习详解
一、预览数据
#-*-coding=utf-8-*-
import pandas as pd
import numpy as np
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
#sns.set_style('whitegrid')
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
train=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\train.csv')#891*12
test=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\test.csv')#891*11
train.info()
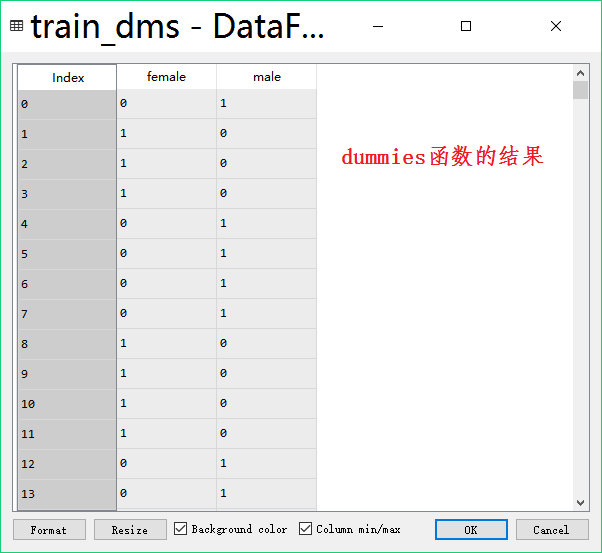
train_dms=pd.get_dummies(train['Sex'])#891*2
train1=pd.concat([train,train_dms],axis=1)#891*(12+2)
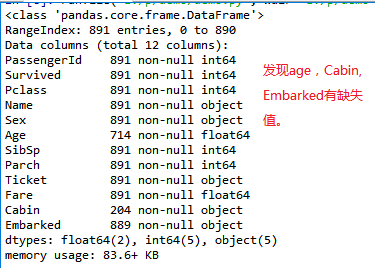
发现age,Cabin, Embarked有缺失值。
看看处理缺失后的年龄和存活的分布
#-*-coding=utf-8-*-
import pandas as pd
import numpy as np
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
#sns.set_style('whitegrid')
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
train=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\train.csv')#891*12
test=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\test.csv')#891*11
train_dms=pd.get_dummies(train['Sex'])#891*2
train1=pd.concat([train,train_dms],axis=1)#891*(12+2)
nan_num = train['Age'].isnull().sum()
# there are 177 missing value, fill with random int
age_mean = train['Age'].mean()
age_std = train['Age'].std()
filling = np.random.randint(age_mean-age_std, age_mean+age_std, size=nan_num)
train['Age'][train['Age'].isnull()==True] = filling
nan_num = train['Age'].isnull().sum()
# dealing the missing val in test
nan_num = test['Age'].isnull().sum()
# 86 null
age_mean = test['Age'].mean()
age_std = test['Age'].std()
filling = np.random.randint(age_mean-age_std,age_mean+age_std,size=nan_num)
test['Age'][test['Age'].isnull()==True]=filling
nan_num = test['Age'].isnull().sum()
#look into the age col
s = sns.FacetGrid(train,hue='Survived',aspect=3)#aspect表示纵横比
s.map(sns.kdeplot,'Age',shade=True)#核密度统计方式
s.set(xlim=(0,train['Age'].max()))
s.add_legend()
核密度统计方式
s.set(xlim=(0,train['Age'].max()))
s.add_legend()
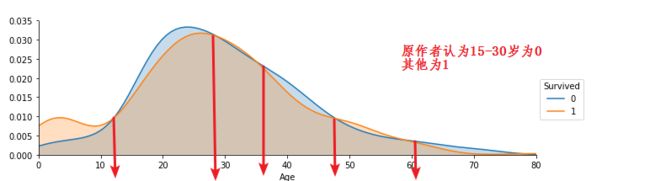
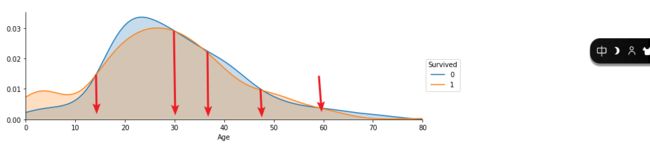
由于随机数的影响:
def under15(row):
result = 0.0
if row<15:
result = 1.0
return result
def young(row):
result = 0.0
if row>=15 and row<30:
result = 1.0
return result
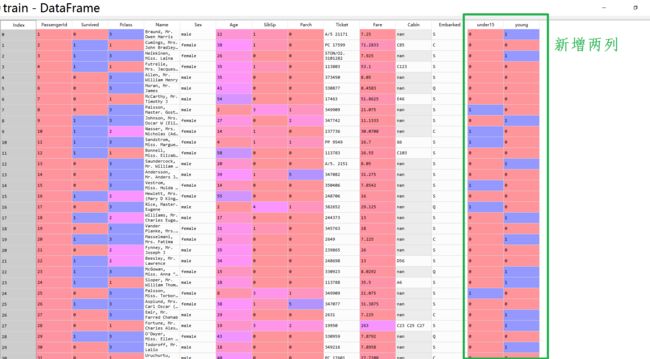
train['under15'] = train['Age'].apply(under15)
test['under15'] = test['Age'].apply(under15)
train['young'] = train['Age'].apply(young)
test['young'] = test['Age'].apply(young)
#family
# chek
print(train['SibSp'].value_counts(dropna=False))
print(train['Parch'].value_counts(dropna=False))
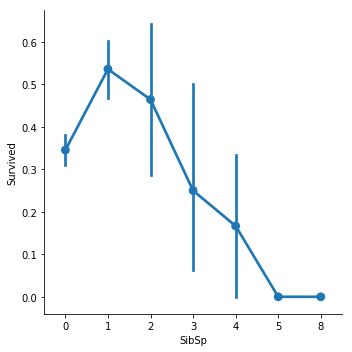
sns.factorplot('SibSp','Survived',data=train,size=5)
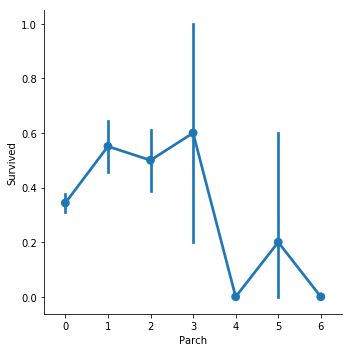
sns.factorplot('Parch','Survived',data=train,size=5)
'''through the plot, we suggest that with more family member,
the survival rate will drop, we can create the new col
add up the parch and sibsp to check our theory'''
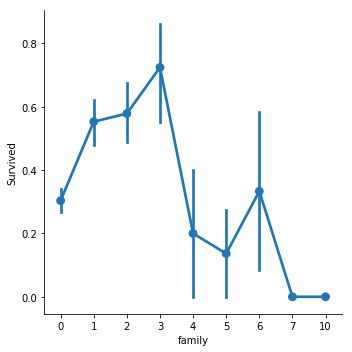
train['family'] = train['SibSp'] + train['Parch']
test['family'] = test['SibSp'] + test['Parch']
sns.factorplot('family','Survived',data=train,size=5)
train.drop(['SibSp','Parch'],axis=1,inplace=True)
test.drop(['SibSp','Parch'],axis=1,inplace=True)
# fare
# checking null, found one in test group. leave it alone til we find out
print(train.Fare.isnull().sum())
print(test.Fare.isnull().sum())result:
0
1
sns.factorplot('Survived','Fare',data=train,size=5)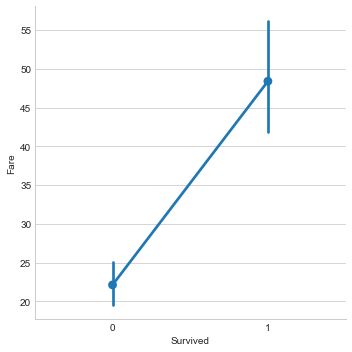
i=train.Embarked.value_counts()
print(i)
S 644
C 168
Q 77
Name: Embarked, dtype: int64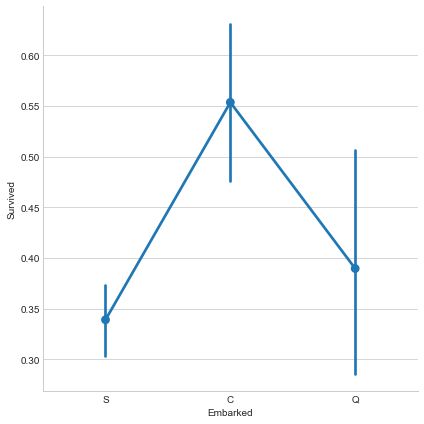
二、模型预测
# testing1, using all the feature
train_ft=train.drop('Survived',axis=1)
train_y=train['Survived']
#set kf
kf = KFold(n_splits=3,random_state=1)
acc_lst = []
ml(train_ft,train_y,'test_1')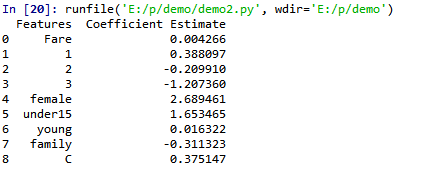
# testing 2, lose young
train_ft_2=train.drop(['Survived','young'],axis=1)
test_2 = test.drop('young',axis=1)
train_ft.head()
# ml
kf = KFold(n_splits=3,random_state=1)
acc_lst=[]
ml(train_ft_2,train_y,'test_2')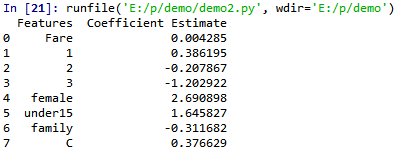
#test3, lose young, c
train_ft_3=train.drop(['Survived','young','C'],axis=1)
test_3 = test.drop(['young','C'],axis=1)
train_ft.head()
# ml
kf = KFold(n_splits=3,random_state=1)
acc_lst = []
ml(train_ft_3,train_y,'test_3')
# test4, no FARE
train_ft_4=train.drop(['Survived','Fare'],axis=1)
test_4 = test.drop(['Fare'],axis=1)
train_ft.head()
# ml
kf = KFold(n_splits=3,random_state=1)
acc_lst = []
ml(train_ft_4,train_y,'test_4')
# test5, get rid of c
train_ft_5=train.drop(['Survived','C'],axis=1)
test_5 = test.drop('C',axis=1)
# ml
kf = KFold(n_splits=3,random_state=1)
acc_lst = []
ml(train_ft_5,train_y,'test_5')
# test6, lose Fare and young
train_ft_6=train.drop(['Survived','Fare','young'],axis=1)
test_6 = test.drop(['Fare','young'],axis=1)
train_ft.head()
# ml
kf = KFold(n_splits=3,random_state=1)
acc_lst = []
ml(train_ft_6,train_y,'test_6')
accuracy_df=pd.DataFrame(data=accuracy,
index=['test1','test2','test3','test4','test5','test6'],
columns=['logistic','rf','svc','knn'])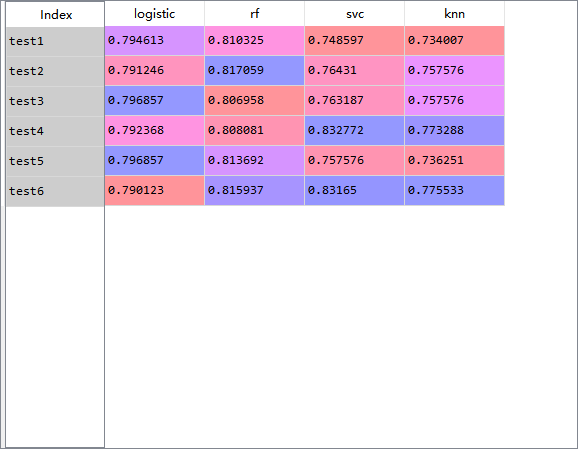
原作者最好是test4
svc 0.832727但是提交后结果:

总结一下源码:
#-*-coding=utf-8-*-
import pandas as pd
pd.options.mode.chained_assignment = None
import numpy as np
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score, KFold
#第一部分. Exploring the Data
train=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\train.csv')
test=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\test.csv')
#print(train.describe())
#train.info()
#sns.factorplot("Pclass","Survived",data=train)
#plt.show()
#2. Data Cleaning and Features Choosing
def dummies(col,train,test):
#定义指示函数处理某个离散型特征,等价把各个变量用数字表示1,2,3
train_dms=pd.get_dummies(train[col])#891*sex(2),Pclass(3)
test_dms =pd.get_dummies(test[col])
train=pd.concat([train,train_dms],axis=1)#axis=1表示第一行#891*(12+2)
test =pd.concat([test,test_dms],axis=1)
train.drop(col,axis=1,inplace=True)#等价于train=train.drop(col,axis=1,inplace=False)
test.drop(col,axis=1,inplace=True)
return train, test
#get rid of useless
dropping = ['PassengerId', 'Name', 'Ticket']
train.drop(dropping,axis=1, inplace=True)
test.drop(dropping,axis=1, inplace=True)
#print(train.Pclass.value_counts())#Returns object containing counts of unique values.
#pclass
train, test = dummies('Pclass',train,test)
'''
观察Sex和Survived的关系,女性生还率显著高于男性
'''
#print(train.Sex.value_counts(dropna=False))
#sns.factorplot('Sex','Survived',data=train)
#plt.show()
train,test = dummies('Sex',train,test)
train.drop('male',axis=1,inplace=True)
test.drop('male',axis=1,inplace=True)
# ensure no na contained
#age
#dealing the missing data
nan_num = train['Age'].isnull().sum()
# there are 177 missing value, fill with random int
age_mean = train['Age'].mean()#平均值
age_std = train['Age'].std()#方差
filling = np.random.randint(age_mean-age_std, age_mean+age_std, size=nan_num)
train['Age'][train['Age'].isnull()==True] = filling
nan_num = train['Age'].isnull().sum()
# dealing the missing val in test
nan_num = test['Age'].isnull().sum()
age_mean=test['Age'].mean()
age_std=test['Age'].std()
filling=np.random.randint(age_mean-age_std, age_mean+age_std, size=nan_num)
test['Age'][test['Age'].isnull()==True]=filling
nan_num = test['Age'].isnull().sum()
# from the graph, we see that the survival rate of children
# is higher than other and the 15-30 survival rate is lower
def under15(row):
result = 0.0
if row<15:
result = 1.0
return result
def young(row):
result = 0.0
if row>=15 and row<30:
result = 1.0
return result
train['under15'] = train['Age'].apply(under15)
test['under15'] = test['Age'].apply(under15)
train['young'] = train['Age'].apply(young)
test['young'] = test['Age'].apply(young)
train.drop('Age',axis=1,inplace=True)
test.drop('Age',axis=1,inplace=True)
#family cheak can adjust(i think)
train['family'] = train['SibSp'] + train['Parch']
test['family'] = test['SibSp'] + test['Parch']
train.drop(['SibSp','Parch'],axis=1,inplace=True)
test.drop(['SibSp','Parch'],axis=1,inplace=True)
# fare
# checking null, found one in test group. leave it alone til we find out
test['Fare'].fillna(test['Fare'].median(),inplace=True)
#Cabin
# checking missing val
# 687 out of 891 are missing, drop this col
train.drop('Cabin',axis=1,inplace=True)
test.drop('Cabin',axis=1,inplace=True)
#Embark
#train.Embarked.isnull().sum()
# 2 missing value
# fill the majority val,'s', into missing val col
train['Embarked'].fillna('S',inplace=True)
# c has higher survival rate, drop the other two
train,test = dummies('Embarked',train,test)
train.drop(['S','Q'],axis=1,inplace=True)
test.drop(['S','Q'],axis=1,inplace=True)
#第二部分
kf = KFold(n_splits=3,random_state=1)
def modeling(clf,ft,target):
acc = cross_val_score(clf,ft,target,cv=kf)#cross_val_score(clf,X,y)
acc_lst.append(acc.mean())
return
accuracy = []
def ml(ft,target,time):
accuracy.append(acc_lst)
#logisticregression
logreg = LogisticRegression()
modeling(logreg,ft,target)
#RandomForest
rf = RandomForestClassifier(n_estimators=50,min_samples_split=4,min_samples_leaf=2)
modeling(rf,ft,target)
#svc
svc = SVC()
modeling(svc,ft,target)
#knn
knn = KNeighborsClassifier(n_neighbors = 3)
modeling(knn,ft,target)
# see the coefficient
logreg.fit(ft,target)
feature = pd.DataFrame(ft.columns)
feature.columns = ['Features']
feature["Coefficient Estimate"] = pd.Series(logreg.coef_[0])
#print(feature)
return
# testing no.1, using all the feature
train_ft=train.drop('Survived',axis=1)
train_y=train['Survived']
#set kf
acc_lst = []
ml(train_ft,train_y,'test_1')
# testing 2, lose young
train_ft_2=train.drop(['Survived','young'],axis=1)
test_2 = test.drop('young',axis=1)
train_ft.head()
# ml
acc_lst=[]
ml(train_ft_2,train_y,'test_2')
#test3, lose young, c
train_ft_3=train.drop(['Survived','young','C'],axis=1)
test_3 = test.drop(['young','C'],axis=1)
train_ft.head()
# ml
acc_lst = []
ml(train_ft_3,train_y,'test_3')
# test4, no FARE
train_ft_4=train.drop(['Survived','Fare'],axis=1)
test_4 = test.drop(['Fare'],axis=1)
train_ft.head()
# ml
acc_lst = []
ml(train_ft_4,train_y,'test_4')
# test5, get rid of c
train_ft_5=train.drop(['Survived','C'],axis=1)
test_5 = test.drop('C',axis=1)
# ml
acc_lst = []
ml(train_ft_5,train_y,'test_5')
# test6, lose Fare and young
train_ft_6=train.drop(['Survived','Fare','young'],axis=1)
test_6 = test.drop(['Fare','young'],axis=1)
train_ft.head()
# ml
acc_lst = []
ml(train_ft_6,train_y,'test_6')
accuracy_df=pd.DataFrame(data=accuracy,
index=['test1','test2','test3','test4','test5','test6'],
columns=['logistic','rf','svc','knn'])
#test4 svc as submission
svc = SVC()
svc.fit(train_ft_4,train_y)
svc_pred = svc.predict(test_4)
print(svc.score(train_ft_4,train_y))
test=pd.read_csv(r'C:\Users\0011\Desktop\kaggle\test.csv')
submission = pd.DataFrame({
'PassengerId': test['PassengerId'],
'Survived': svc_pred
})
#submission.to_csv("kaggle.csv", index=False)
三、更新一些知识
特征分析:
目的:初步了解数据之间的相关性,为构造特征工程以及模型建立做准备
来个总览,快速了解个数据的相关性。
data_dir= 'D:\data Competition\Titanic/'
# 加载 train 和 test 数据集
train=pd.read_csv(os.path.join(data_dir,'input/train.csv'))
test=pd.read_csv(os.path.join(data_dir,'input/test.csv'))
# 存储 Passenger ID 方便后续操作
PassengerId = test['PassengerId']
#print(train.head(3))打印前三行
train_corr = train.drop('PassengerId',axis=1).corr()
a = plt.subplots(figsize=(15,9))#调整画布大小
a = sns.heatmap(train_corr, vmin=-1, vmax=1 , annot=True , square=True)#画热力图
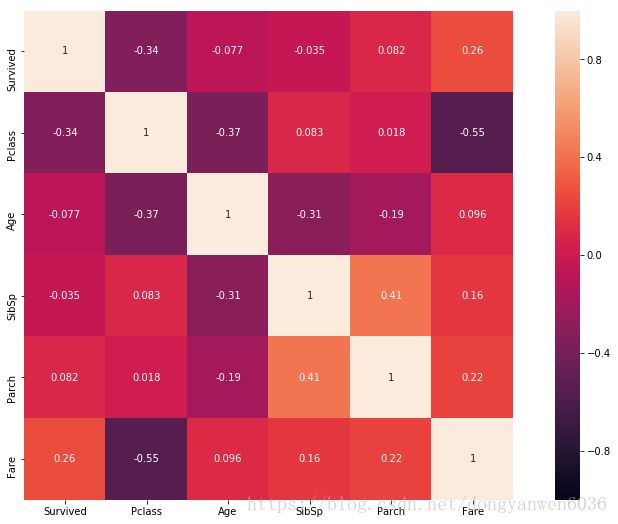
更多数据分析图参看
参考
参考2