[PRML]图模型-条件独立
在上一节中,我们介绍了《有向图模型》,这一节给大家介绍条件独立性。
1 简介
多变量概率分布的一个重要概念是条件独立(conditional independence)。考虑三个变量 a a a、 b b b和 c c c,假设 a a a在给定 b b b和 c c c下的条件分布不依赖于 b b b的值,则:
p ( a ∣ b , c ) = p ( a ∣ c ) 式 ( 20 ) p(a|b,c)=p(a|c) \ 式(20) p(a∣b,c)=p(a∣c) 式(20)
读作在给定 c c c下 a a a独立于 b b b。
如果我们考虑以 c c c为条件的 a a a和 b b b的联合分布,这可以用一种稍微不同的方式来表示,我们可以写成这种形式:
p ( a , b ∣ c ) = p ( a ∣ b , c ) p ( b ∣ c ) = p ( a ∣ c ) p ( b ∣ c ) 式 ( 21 ) \begin{aligned} p(a,b|c)&=p(a|b,c)p(b|c)\\ &=p(a|c)p(b|c) \ 式(21) \end{aligned} p(a,b∣c)=p(a∣b,c)p(b∣c)=p(a∣c)p(b∣c) 式(21)
可以看到,在给定 c c c下, a a a和 b b b的联合分布可以分解为 a a a的边际分布和 b b b的边际分布(给定 c c c下)。这说明在给定 c c c的情况下,变量 a a a和 b b b在统计上是独立的。
条件独立性的定义需要式20和式21必须对 c c c的每个可能值都成立,而不仅仅是某些值。我们有时会用一个简略的符号来表示条件独立:
a ⊥ ⊥ b ∣ c 式 ( 22 ) a{\perp\!\!\!\perp}b|c \ 式(22) a⊥⊥b∣c 式(22)
表示 a a a有条件地独立于给定 c c c的 b b b,等于式20。
条件独立性在使用概率模型进行模式识别方面发挥着重要作用,它简化了模型的结构以及在该模型下执行推理和学习所需的计算。
如果给定一组变量的联合分布的表达式是条件分布的乘积,则原则上可以反复应用概率的和与积规则检验任何潜在的条件独立性是否成立。
实践中,该方法非常耗时。图模型的一个重要特性是联合分布的条件独立性可以直接从图中读取,而不需要任何分析操作。实现这一目标的一般框架称为d-separation,d表示directed。关于d-separation见这里和这里。
2 案例
我们通过三个简单的例子来讨论有向图的条件独立性,每个例子都涉及到只有三个节点的图。
2.1 例1
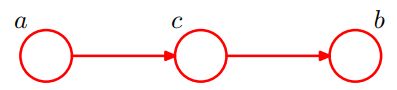
第一个例子如下图所示,这个图对应的联合分布很容易用一般结果表示出来:
p ( a , b , c ) = p ( a ∣ c ) p ( b ∣ c ) p ( c ) 式 ( 23 ) p(a,b,c)=p(a|c)p(b|c)p(c) \ 式(23) p(a,b,c)=p(a∣c)p(b∣c)p(c) 式(23)
![[PRML]图模型-条件独立_第1张图片](http://img.e-com-net.com/image/info8/7aed86d7affc4ad7aef84a109cb49548.jpg)
如果这些变量均不可观测,则可通过对式23两边相对于 c c c边缘化来研究 a a a和 b b b是否独立:
p ( a , b ) = ∑ c p ( a ∣ c ) p ( b ∣ c ) p ( c ) 式 ( 24 ) p(a,b)=\sum_c p(a|c)p(b|c)p(c) \ 式(24) p(a,b)=c∑p(a∣c)p(b∣c)p(c) 式(24)
一般来说,这不能因式分解成 p ( a ) p ( b ) p(a)p(b) p(a)p(b)的乘积,所以:
a ̸ ⊥ ⊥ b ∣ ∅ 式 ( 25 ) a \not\!\perp\!\!\!\perp b | \varnothing \ 式(25) a⊥⊥b∣∅ 式(25)
其中 ∅ \varnothing ∅表示空集,符号 ̸ ⊥ ⊥ \not\!\perp\!\!\!\perp ⊥⊥ 表示条件独立性一般不成立。当然,它可能适用于特定的分布,通过与各种条件概率相关的特定的数值,但它不遵循一般从图的结构。
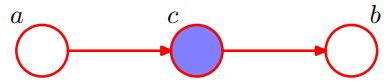
现在假设我们对变量 c c c设置条件,如下图所示。从式23我们可以很容易地写出给定 c c c, a a a和 b b b的条件分布:
p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ∣ c ) p ( b ∣ c ) \begin{aligned} p(a,b|c)&=\frac{p(a,b,c)}{p(c)}\\ &=p(a|c)p(b|c) \end{aligned} p(a,b∣c)=p(c)p(a,b,c)=p(a∣c)p(b∣c)
因此得到了条件独立属性:
a ⊥ ⊥ b ∣ c a \perp\!\!\!\perp b|c a⊥⊥b∣c
这个结果的一个简单的图形解释:节点 a a a到节点 b b b的路径(path)经过节点 c c c。节点 c c c相对于这条路径被认为是**尾尾相接的(tail-to-tail)**因为这个节点连接了两个箭头的尾部。
这种连接节点 a a a和 b b b的路径的存在使得这些节点相互依赖(dependent)。但是,当我们对节点 c c c进行条件设置时,如下图所示,条件节点阻塞(block)了从 a a a到 b b b的路径,并导致(cause) a a a和 b b b(有条件地)独立。
![[PRML]图模型-条件独立_第2张图片](http://img.e-com-net.com/image/info8/70dcb94661ac49b9a73766db626dd2a1.jpg)
2.2 例2
同样可以考虑下图。与此图对应的联合分布再次由通式式5得到:
p ( a , b , c ) = p ( a ) p ( c ∣ a ) p ( b ∣ c ) 式 ( 26 ) p(a,b,c)=p(a)p(c|a)p(b|c) \ 式(26) p(a,b,c)=p(a)p(c∣a)p(b∣c) 式(26)
式5:
p ( x ) = ∏ k = 1 K p ( x k ∣ p a k ) , x = ( x 1 , . . . , x K ) p(\mathbf{x})=\prod_{k=1}^Kp(x_k|pa_k),\mathbf{x}=(x_1,...,x_K) p(x)=k=1∏Kp(xk∣pak),x=(x1,...,xK)
首先,假设没有一个变量被观察到。同样,我们可以通过边缘化 c c c来检验 a a a和 b b b是否相互独立:
p ( a , b ) = p ( a ) ∑ c p ( c ∣ a ) p ( b ∣ c ) = p ( a ) p ( b ∣ a ) p(a,b)=p(a) \sum_c p(c|a)p(b|c)=p(a)p(b|a) p(a,b)=p(a)c∑p(c∣a)p(b∣c)=p(a)p(b∣a)
上式一般不能因式分解为 p ( a ) p ( b ) p(a)p(b) p(a)p(b),所以:
a ̸ ⊥ ⊥ b ∣ ∅ 式 ( 27 ) a\not\!\perp\!\!\!\perp b|\varnothing \ 式(27) a⊥⊥b∣∅ 式(27)
现在假设在节点 c c c上设置条件,如下图所示。利用贝叶斯定理,结合式26得到:
p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = f r a c p ( a ) p ( c ∣ a ) p ( b ∣ c ) p ( c ) = p ( a ∣ c ) p ( b ∣ c ) \begin{aligned} p(a,b|c)&=\frac{p(a,b,c)}{p(c)}\\ &=frac{p(a)p(c|a)p(b|c)}{p(c)}\\ &=p(a|c)p(b|c) \end{aligned} p(a,b∣c)=p(c)p(a,b,c)=fracp(a)p(c∣a)p(b∣c)p(c)=p(a∣c)p(b∣c)
我们又得到了条件独立属性:
a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c
图形化地解释这些结果:节点 c c c从节点 a a a到节点 b b b的路径被称为首尾相接(head-to-tail),这样的路径连接节点 a a a和节点 b b b并使它们相互依赖(dependent)。如果我们现在观察 c c c,如下图所示,那么这个观察就会阻塞(block)从 a a a到 b b b的路径(path),因此我们获得了条件独立属性 a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c。
2.3 例3
最后我们考虑下图中所示的3个节点示例。正如我们将看到的,这比前面两个图有更微妙的行为。
联合分布可以用式5给出:
p ( a , b , c ) = p ( a ) p ( b ) p ( c ∣ a , b ) 式 ( 28 ) p(a,b,c)=p(a)p(b)p(c|a,b) \ 式(28) p(a,b,c)=p(a)p(b)p(c∣a,b) 式(28)
![[PRML]图模型-条件独立_第3张图片](http://img.e-com-net.com/image/info8/b04e1d0309934376a936dcb2d20a541a.jpg)
首先考虑没有观察到任何变量的情况。将式28的两边对 c c c边缘化,我们得到:
p ( a , b ) = p ( a ) p ( b ) p(a,b)=p(a)p(b) p(a,b)=p(a)p(b)
所以 a a a和 b b b是独立的即使没有观察到变量,与之前的两个例子不同。我们可以把这个结果写成:
a ⊥ ⊥ b ∣ ∅ 式 ( 29 ) a \perp\!\!\!\perp b|\varnothing \ 式(29) a⊥⊥b∣∅ 式(29)
现在假设我们以 c c c为条件,如下图所示。然后给出 a a a和 b b b的条件分布:
p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ) p ( b ) p ( c ∣ a , b ) p ( c ) \begin{aligned} p(a,b|c)&=\frac{p(a,b,c)}{p(c)}\\ &=\frac{p(a)p(b)p(c|a,b)}{p(c)} \end{aligned} p(a,b∣c)=p(c)p(a,b,c)=p(c)p(a)p(b)p(c∣a,b)
上式一般不会因式分解成 p ( a ) p ( b ) p(a)p(b) p(a)p(b),所以:
a ⊥̸ ⊥ b ∣ c a\not\perp\!\!\!\perp b|c a⊥⊥b∣c
因此第3个例子与前2个例子的行为相反。从图形上看,节点 c c c在从 a a a到 b b b的路径上是头对头的(head-to-head),因为它连接到两个箭头的头。当节点 c c c未被观察时,它会阻塞路径( block the path),且变量 a a a和 b b b是独立的。但是,以 c c c为条件解除了路径阻塞,使 a a a和 b b b依赖(dependent)。
![[PRML]图模型-条件独立_第4张图片](http://img.e-com-net.com/image/info8/fed4d32107094a7a9fcc7de64f67e4c0.jpg)
与第三个例子相关的还有一个微妙之处。首先,介绍一些术语。如果有一条从 x x x到 y y y的路径,其中路径的每一步都遵循箭头的方向,我们就说节点 y y y是节点 x x x的后代(descendants)。 如果观察到节点或节点的任何后代节点,则头对头路径(head-to-head path)将被解除阻塞(unblocked)。
2.4 the phenomenon of ‘explaining away’
进一步了解上图的不寻常行为。
考虑这样一个图的特殊实例,它对应于一个包含三个与汽车燃油系统相关的二进制随机变量的问题,如下图所示。 B B B变量代表电池状态,要么有电 ( B = 1 ) (B=1) (B=1)或无电 ( B = 0 ) (B=0) (B=0), F F F代表油箱的状态,燃料满 ( F = 1 ) (F=1) (F=1)或空 ( F = 0 ) (F=0) (F=0), G G G代表电动燃油表的状态,表示满 ( G = 1 ) (G=1) (G=1)或空 ( G = 0 ) (G=0) (G=0)。
![[PRML]图模型-条件独立_第5张图片](http://img.e-com-net.com/image/info8/efce04b720eb47ba8f35d7fd339d65d0.jpg)
电池要么有电,要么没电;油箱要么是满的,要么是空的,这是由先验概率(prior probabilities)决定的:
p ( B = 1 ) = 0.9 p ( F = 1 ) = 0.9 \begin{aligned} p(B=1)&=0.9\\ p(F=1)&=0.9 \end{aligned} p(B=1)p(F=1)=0.9=0.9
根据油箱和电池的状态,燃油表显示充满的可能性(probabilities):
p ( G = 1 ∣ B = 1 , F = 1 ) = 0.8 p ( G = 1 ∣ B = 1 , F = 0 ) = 0.2 p ( G = 1 ∣ B = 0 , F = 1 ) = 0.2 p ( G = 1 ∣ B = 0 , F = 0 ) = 0.1 \begin{aligned} p(G=1|B=1,F=1)&=0.8\\ p(G=1|B=1,F=0)&=0.2\\ p(G=1|B=0,F=1)&=0.2\\ p(G=1|B=0,F=0)&=0.1 \end{aligned} p(G=1∣B=1,F=1)p(G=1∣B=1,F=0)p(G=1∣B=0,F=1)p(G=1∣B=0,F=0)=0.8=0.2=0.2=0.1
所以这是一个相当不可靠的燃料表。所有剩余的概率由概率和为1的要求决定,因此我们有了概率模型的完整规范。
在观察任何数据之前,油箱空的先验概率是 p ( F = 0 ) = 0.1 p(F=0)=0.1 p(F=0)=0.1。现在假设我们观察燃料表,发现它是空的即 G = 0 G=0 G=0,对应于上图的中间图形。我们可以用贝叶斯定理来计算油箱为空的后验概率。首先对贝叶斯定理的分母求值:
p ( G ) = ∑ B ∈ { 0 , 1 } ∑ F ∈ { 0 , 1 } p ( G , B , F ) = ∑ B ∈ { 0 , 1 } ∑ F ∈ { 0 , 1 } p ( G ∣ B , F ) p ( B ) p ( F ) p ( G = 0 ) = ∑ B ∈ { 0 , 1 } ∑ F ∈ { 0 , 1 } p ( G = 0 ∣ B , F ) p ( B ) p ( F ) = p ( G = 0 ∣ B = 1 , F = 1 ) p ( B = 1 ) p ( F = 1 ) + p ( G = 0 ∣ B = 1 , F = 0 ) p ( B = 1 ) p ( F = 0 ) + p ( G = 0 ∣ B = 1 , F = 0 ) p ( B = 0 ) p ( F = 1 ) + p ( G = 0 ∣ B = 0 , F = 0 ) p ( B = 0 ) p ( F = 0 ) = 0.2 × 0.9 × 0.9 + 0.8 × 0.9 × 0.1 + 0.8 × 0.1 × 0.9 + 0.9 × 0.1 × 0.1 = 0.162 + 0.072 + 0.072 + 0.09 = 0.315 式 ( 30 ) \begin{aligned} p(G)&=\sum_{B\in \{0,1\}}\sum_{F\in \{0,1\}} p(G,B,F)\\ &=\sum_{B\in \{0,1\}}\sum_{F\in \{0,1\}}p(G|B,F)p(B)p(F)\\ p(G=0)&=\sum_{B\in \{0,1\}}\sum_{F\in \{0,1\}}p(G=0|B,F)p(B)p(F)\\ &=p(G=0|B=1,F=1)p(B=1)p(F=1)+p(G=0|B=1,F=0)p(B=1)p(F=0)\\ &\ \ \ +p(G=0|B=1,F=0)p(B=0)p(F=1)+p(G=0|B=0,F=0)p(B=0)p(F=0)\\ &=0.2 \times 0.9 \times 0.9+0.8 \times 0.9 \times 0.1+0.8\times 0.1 \times 0.9+0.9 \times 0.1 \times 0.1\\ &=0.162+0.072+0.072+0.09=0.315 \ 式(30) \end{aligned} p(G)p(G=0)=B∈{0,1}∑F∈{0,1}∑p(G,B,F)=B∈{0,1}∑F∈{0,1}∑p(G∣B,F)p(B)p(F)=B∈{0,1}∑F∈{0,1}∑p(G=0∣B,F)p(B)p(F)=p(G=0∣B=1,F=1)p(B=1)p(F=1)+p(G=0∣B=1,F=0)p(B=1)p(F=0) +p(G=0∣B=1,F=0)p(B=0)p(F=1)+p(G=0∣B=0,F=0)p(B=0)p(F=0)=0.2×0.9×0.9+0.8×0.9×0.1+0.8×0.1×0.9+0.9×0.1×0.1=0.162+0.072+0.072+0.09=0.315 式(30)
类似的:
p ( G = 0 ∣ F = 0 ) = ∑ B ∈ { 0 , 1 } p ( { G = 0 ∣ F = 0 } , B ) = ∑ B ∈ { 0 , 1 } p ( G = 0 ∣ B , F = 0 ) p ( B ) = 0.81 式 ( 31 ) \begin{aligned} p(G=0|F=0)&=\sum_{B\in \{0,1\}} p(\{G=0|F=0\}, B)\\ &=\sum_{B\in \{0,1\}} p(G=0|B,F=0)p(B)=0.81 \ 式(31) \end{aligned} p(G=0∣F=0)=B∈{0,1}∑p({G=0∣F=0},B)=B∈{0,1}∑p(G=0∣B,F=0)p(B)=0.81 式(31)
利用这些结果:
p ( F = 0 ∣ G = 0 ) = p ( G = 0 ∣ F = 0 ) p ( F = 0 ) p ( G = 0 ) ≃ 0.257 式 ( 32 ) p(F=0|G=0)=\frac{p(G=0|F=0)p(F=0)}{p(G=0)} \simeq 0.257 \ 式(32) p(F=0∣G=0)=p(G=0)p(G=0∣F=0)p(F=0)≃0.257 式(32)
所以 p ( F = 0 ∣ G = 0 ) > p ( F = 0 ) p(F=0|G=0)>p(F=0) p(F=0∣G=0)>p(F=0)。因此观察到仪表读数为空使油箱确实是空的可能性更大。
接下来检查电池的状态,发现没电即 B = 0 B=0 B=0。现在我们已经观察到了燃料表和电池的状态,如上图右图所示。根据燃油表和电池状态的观测,给出油箱为空的后验概率为:
p ( F = 0 ∣ G = 0 , B = 0 ) = p ( G = 0 , B = 0 , F = 0 ) p ( G = 0 , B = 0 ) = p ( G = 0 , B = 0 , F = 0 ) ∑ F ∈ { 0 , 1 } p ( G = 0 , B = 0 , F ) = p ( G = 0 ∣ B = 0 , F = 0 ) p ( B = 0 , F = 0 ) ∑ F ∈ { 0 , 1 } p ( G = 0 ∣ B = 0 , F ) p ( B = 0 , F ) = p ( G = 0 ∣ B = 0 , F = 0 ) p ( B = 0 ) p ( F = 0 ) ∑ F ∈ { 0 , 1 } p ( G = 0 ∣ B = 0 , F ) p ( B = 0 ) p ( F ) = p ( G = 0 ∣ B = 0 , F = 0 ) p ( F = 0 ) ∑ F ∈ { 0 , 1 } p ( G = 0 ∣ B = 0 , F ) p ( F ) = 0.9 × 0.1 0.9 × 0.1 + 0.8 × 0.9 = 1 9 ≃ 0.111 式 ( 33 ) \begin{aligned} p(F=0|G=0,B=0)&=\frac{p(G=0,B=0,F=0)}{p(G=0,B=0)}\\ &=\frac{p(G=0,B=0,F=0)}{\sum_{F\in \{0,1\}}p(G=0,B=0, F)}\\ &=\frac{p(G=0|B=0,F=0)p(B=0,F=0)}{\sum_{F\in \{0,1\}}p(G=0|B=0, F)p(B=0,F)}\\ &=\frac{p(G=0|B=0,F=0)p(B=0)p(F=0)}{\sum_{F\in \{0,1\}}p(G=0|B=0, F)p(B=0)p(F)}\\ &=\frac{p(G=0|B=0,F=0)p(F=0)}{\sum_{F\in \{0,1\}}p(G=0|B=0, F)p(F)} \\ &=\frac{0.9 \times 0.1}{0.9 \times 0.1+0.8 \times 0.9} \\ &=\frac{1}{9} \simeq 0.111 \ 式(33) \end{aligned} p(F=0∣G=0,B=0)=p(G=0,B=0)p(G=0,B=0,F=0)=∑F∈{0,1}p(G=0,B=0,F)p(G=0,B=0,F=0)=∑F∈{0,1}p(G=0∣B=0,F)p(B=0,F)p(G=0∣B=0,F=0)p(B=0,F=0)=∑F∈{0,1}p(G=0∣B=0,F)p(B=0)p(F)p(G=0∣B=0,F=0)p(B=0)p(F=0)=∑F∈{0,1}p(G=0∣B=0,F)p(F)p(G=0∣B=0,F=0)p(F=0)=0.9×0.1+0.8×0.90.9×0.1=91≃0.111 式(33)
因此,由于对电池状态的观察,邮箱空的概率降低了(从0.257降低到0.111)。电池没电解释了燃料表读值为空。我们看到燃料箱的状态和电池的状态确实变得相互依赖,这是观察燃料表读数的结果。如果不直接观察燃油量表而是观察 G G G的后代,结果也是一样的。
注意概率 p ( F = 0 ∣ G = 0 , B = 0 ) ≃ 0.111 p(F=0|G=0,B=0)\simeq 0.111 p(F=0∣G=0,B=0)≃0.111大于先验概率 p ( F = 0 ) = 0.1 p(F=0)=0.1 p(F=0)=0.1因为燃料的观测读数零仍然提供了一些证据支持油箱是空的。
3 D-separation
现在给出有向图的d-separation特性的一般描述。考虑一个通用的有向图,其中 A A A、 B B B和 C C C是任意的非相交节点集(它们的并集可能小于图中的完整节点集)。
我们希望确定一个特定的条件独立语句 A ⊥ ⊥ B ∣ C A\perp\!\!\!\perp B|C A⊥⊥B∣C是否被一个给定的有向无环图所暗示。为此,我们考虑从 A A A中的任意节点到 B B B中的任意节点的所有可能路径。如果任何这样的路径包含这样的节点,则该路径被阻塞(blocked):
- ( a ) (a) (a)路径上的箭头在节点处头尾相接或尾尾相接(head-to-tail or tail-to-tail)并且节点在集合 C C C中
- ( b ) (b) (b)箭头在该节点上迎头相接(head-to-head),该节点及其后代节点(descendants)都不在集合 C C C中
如果所有路径受阻,那么说 A A A与 B B B之间被 C C C有向分离(d-separated),图中对所有变量的联合分布满足 A ⊥ ⊥ B ∣ C A\perp\!\!\!\perp B|C A⊥⊥B∣C。
d-separation的概念如下图所示:
- 图 ( a ) (a) (a):从 a a a到 b b b的路径没有被节点 f f f阻塞,因为它是一个尾到尾的节点路径并且不是观测到的,也不被 e e e节点阻塞。尽管后者是一个头到头的节点,但其后代 c c c也在条件集合里且被观测到,所以条件独立声明 a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c不符合这个图。
- 图 ( b ) (b) (b):从 a a a到 b b b的路径被节点 f f f阻塞,因为它是一个尾到尾的节点路径并且是观测到的,所以条件独立属性 a ⊥ ⊥ b ∣ f a\perp\!\!\!\perp b|f a⊥⊥b∣f满足于根据这个图进行因式分解的任何分布。注意,此路径也被节点 e e e阻塞,因为 e e e是一个头对头节点,它和它的后代节点都不在条件集合中。
![[PRML]图模型-条件独立_第6张图片](http://img.e-com-net.com/image/info8/cb167cc229dc4a6ba6eebc8dc8fff594.jpg)
对于d-separation的目的,参数如下图中的 α \alpha α和 σ 2 \sigma^2 σ2(用小的填充圆圈表示),其行为与观察到的节点相同。但是,没有与这些节点相关的边际分布。因此,参数节点本身从不具有父节点,所以通过这些节点的所有路径将始终是尾尾相接的(tail-to-tail),会被阻塞(blocked)。因此它们在d-separation中没有作用。
![[PRML]图模型-条件独立_第7张图片](http://img.e-com-net.com/image/info8/bb5d92fa5cb1452b92db0891eff637e2.jpg)
条件独立和d-separation的另一个例子是独立同分布(i.i.d.,independent identically distributed)数据的概念。
考虑寻找单变量高斯分布的均值的后验分布的问题。这可以用下面的有向图来表示,其中联合分布由先验 p ( μ ) p(\mu) p(μ)和一组条件分布 p ( x n ∣ μ ) , n = 1 , . . . , N p(x_n|\mu),n=1,...,N p(xn∣μ),n=1,...,N给出。在实践中,我们观察到 D = { x 1 , … , x N } D=\{x_1,…,x_N\} D={x1,…,xN}以及我们的目标是推断 μ \mu μ。
假设以 μ \mu μ为条件,考虑观测值的联合分布。使用d-separation,注意到从任何节点 x i x_i xi到任何节点 x j ≠ i x_{j\neq i} xj=i都有一条唯一的路径,并且该路径相对于观察到的节点是首尾相接的。每条这样的路径都被阻塞,因此给定 μ \mu μ观测值 D = { x 1 , … , x N } D=\{x_1,…,x_N\} D={x1,…,xN}是独立:
p ( D ∣ μ ) = ∏ n = 1 N p ( x n ∣ μ ) 式 ( 34 ) p(\mathcal{D}|\mu)=\prod_{n=1}^Np(x_n|\mu) \ 式(34) p(D∣μ)=n=1∏Np(xn∣μ) 式(34)
![[PRML]图模型-条件独立_第8张图片](http://img.e-com-net.com/image/info8/7a22e5128ad64b6385678c1a90831745.jpg)
然而,如果我们对 μ \mu μ积分,则观察值一般不再独立:
p ( D ) = ∫ 0 ∞ p ( D ∣ μ ) p ( μ ) d μ ≠ ∏ n = 1 N p ( x n ) 式 ( 35 ) p(\mathcal{D})=\int_0^{\infty} p(\mathcal{D}|\mu)p(\mu)d\mu \neq \prod_{n=1}^Np(x_n) \ 式(35) p(D)=∫0∞p(D∣μ)p(μ)dμ=n=1∏Np(xn) 式(35)
μ \mu μ是一个潜变量(latent variable),因为它的值没有被观察到(not observed)。
另一个表示i.i.d.数据的模型示例如下图所示,图对应贝叶斯多项式回归(Bayesian polynomial regression)。 随机节点对应于 { t n } \{t_n\} {tn}, w \mathbf{w} w和 t ^ \hat{t} t^。我们看到从 t ^ \hat{t} t^到 t n t_n tn的任一节点的路径中 w \mathbf{w} w的节点是尾尾相接的,因此有下面的条件独立属性:
t ^ ⊥ ⊥ t n ∣ w 式 ( 36 ) \hat{t}\perp\!\!\!\perp t_n|\mathbf{w} \ 式(36) t^⊥⊥tn∣w 式(36)
因此,以多项式系数 w \mathbf{w} w为条件, t ^ \hat{t} t^的预测分布独立于训练数据 { t 1 , … , t N } \{t_1,…,t_N\} {t1,…,tN}。因此,我们可以先用训练数据确定系数 w \mathbf{w} w的后验分布,然后抛弃训练数据,利用 w \mathbf{w} w的后验分布来做新输入观测 x ^ \hat{x} x^的预测 t ^ \hat{t} t^。
![[PRML]图模型-条件独立_第9张图片](http://img.e-com-net.com/image/info8/459fa2a9a82549ada0f0a1be372e88fc.jpg)
一个相关的图形结构出现在一种称为朴素贝叶斯模型(naive Bayes)的分类方法中,在这种方法中我们使用条件独立假设来简化模型结构。
假设我们观察到的变量由一个 D D D维向量 x = ( x 1 , … , x D ) T \mathbf{x}=(x_1,…,x_D)^T x=(x1,…,xD)T组成,我们希望将 x \mathbf{x} x的观测值赋给 K K K个类中的一个。使用 1 − o f − K 1-of-K 1−of−K编码方案,可以用一个 K K K维的二进制向量 z \mathbf{z} z表示这些类。然后,我们可以通过在类标签上引入一个多项式先验 p ( z ∣ μ ) p(\mathbf{z}|\mu) p(z∣μ)来定义一个生成模型,其中的第 k k k个分量 μ k \mu_k μk是类 C k C_k Ck的先验概率,以及观察到的向量 x \mathbf{x} x的条件分布 p ( x ∣ z ) p(\mathbf{x}|\mathbf{z}) p(x∣z)。朴素贝叶斯模型的关键假设是,在类 z \mathbf{z} z的条件下,输入变量 x 1 , . . . , x D x_1,...,x_D x1,...,xD的分布是独立的。
此模型的图形表示如下图所示,可以看到 z \mathbf{z} z对 z \mathbf{z} z的观测阻塞了 x i x_i xi和 x j x_j xj( j ≠ i j\neq i j=i)之间的路径(因为这样的路径在节点 z \mathbf{z} z是尾对尾的),所以 x i x_i xi和 x j x_j xj在给定 z \mathbf{z} z下是条件独立的。
但是,如果我们将 z \mathbf{z} z边缘化(这样 z \mathbf{z} z就不会被观察到),那么从 x i x_i xi到 x j x_j xj的路径在节点 z \mathbf{z} z(尾部到尾部的)就不会再被阻塞。这告诉我们,一般来说,边际密度 p ( x ) p(\mathbf{x}) p(x)不会对 x \mathbf{x} x的分量进行因式分解。
![[PRML]图模型-条件独立_第10张图片](http://img.e-com-net.com/image/info8/d0fa0c3ba06d4a16b00bfbde41ba15f0.jpg)
如果我们有一个标记的训练集,包含输入 { x 1 , … , x N } \{\mathbf{x}_1,…,\mathbf{x}_N\} {x1,…,xN}以及它们的类标签,然后利用最大似然法( maximum likelihood)将朴素贝叶斯模型与训练数据进行拟合,假设数据与模型无关。
利用相应的标记数据分别对每个类的模型进行拟合得到解。如假设每个类内的概率密度为高斯分布。在这种情况下,朴素贝叶斯假设意味着每个高斯函数的协方差矩阵是对角的(diagonal),并且每个类内的恒定密度的轮廓将是轴向排列的椭球体。???
但是,边际密度是由对角高斯叠加得到的(权重系数由类先验给出),因此不再对其分量(components)进行因式分解(factorize)。
当输入空间的维数 D D D较大时,朴素贝叶斯假设是有帮助的,使得整个 D D D维空间的密度估计更具挑战性。如果输入向量同时包含离散变量和连续变量,这也很有用,因为每个变量都可以使用适当的模型分别表示(例如,二进制观测的伯努利分布或实值变量的高斯分布)。
这个模型的条件独立假设显然是一个强有力的假设,它可能导致相当差的类条件密度的表示。然而,即使这个假设不完全满足,该模型在实践中仍可能提供良好的分类性能,因为决策边界可能对类条件密度中的一些细节不敏感。
从上可以看出,一个特定的有向图的联合概率分布可以分解为特定的条件概率的乘积。图还表达了一组通过d-separation准则得到的条件独立命题,d-separation定理实际上是这两个性质等价性的表达。可以将有向图看作一个过滤器。
假设我们考虑一个特定的联合概率分布 p ( x ) p(\mathbf{x}) p(x),变量 x \mathbf{x} x对应于图中未被观察到的节点。当且仅当此分布可以用图中隐含的因子分解(式5)表示时,过滤器将允许此分布通过。
如果我们将变量 x \mathbf{x} x集合上所有可能的分布 p ( x ) p(\mathbf{x}) p(x)的集合呈现给过滤器,那么过滤器传递的分布子集将被记为 D F DF DF(distributions passed by the filter ),用于有向因式分解(directed factorization),如下图所示。
![[PRML]图模型-条件独立_第11张图片](http://img.e-com-net.com/image/info8/d0a44fc414fc4bc08604fd5e1cd693c0.jpg)
或者可以将图作为另一种过滤器使用。首先列出对图应用d-separation准则获得的所有条件独立性属性,然后只允许满足所有这些属性的分布通过。如果我们把所有可能的分布 p ( x ) p(\mathbf{x}) p(x)呈现给第二种滤波器,那么d-separation定理告诉我们允许通过的分布的集合就是 D F DF DF。
需要强调的是,从d-separation得到的条件独立特性适用于该特定有向图所描述的任何概率模型。无论变量是离散的、连续的还是它们的组合,这都是正确的。我们看到一个特定的图形描述了整个系列的概率分布。
在一种极端情况下,我们有一个完全连通的图,它完全没有条件独立性,并且可以表示给定变量上的任何可能的联合概率分布。集合 D F DF DF将包含所有可能的分布 p ( x ) p(\mathbf{x}) p(x)。在另一个极端,我们有完全断开的图即一个链接都没有。这对应于被分解为图中节点组成的变量的边际分布的乘积的联合分布。
注意对于任何给定的图,分布集和 D F DF DF将包括除图中描述的分布之外具有附加独立性的任何分布。如一个完全因式分解的分布总是能通过对应变量集合上的任何图所隐含的过滤器传递。
通过探讨Markov blanket 或 Markov boundary的概念来结束对条件独立性质的讨论。考虑联合分布 p ( x 1 , . . . , x D ) p(\mathbf{x}_1,...,\mathbf{x}_D) p(x1,...,xD)由一个有 D D D个节点的有向图表示,并考虑一个特定节点的条件分布,其中变量 x i \mathbf{x}_i xi以所有剩余变量 x j ≠ i \mathbf{x}_{j\neq i} xj=i为条件。使用因子分解属性(式5),可以将此条件分布表示为以下形式:
p ( x i ∣ x { j ≠ i } ) = p ( x 1 , . . . , x D ) ∫ p ( x 1 , . . . , x D ) d x i = ∏ k p ( x k ∣ p a k ) ∫ ∏ k p ( x k ∣ p a k ) d x i \begin{aligned} p(\mathbf{x}_i|\mathbf{x}_{\{j\neq i\}})&=\frac{p(\mathbf{x}_1,...,\mathbf{x}_D)}{\int p(\mathbf{x}_1,...,\mathbf{x}_D)d\mathbf{x}_i}\\ &=\frac{\prod_kp(\mathbf{x}_k|pa_k)}{\int \prod_kp(\mathbf{x}_k|pa_k)d \mathbf{x}_i} \end{aligned} p(xi∣x{j=i})=∫p(x1,...,xD)dxip(x1,...,xD)=∫∏kp(xk∣pak)dxi∏kp(xk∣pak)
在离散变量的情况下,积分被求和所代替。我们现在观察到,任何对 x i \mathbf{x}_i xi没有函数依赖关系的因子 p ( x k ∣ p a k ) p(\mathbf{x}_k|pa_k) p(xk∣pak)都可以放在对 x i \mathbf{x}_i xi的积分之外,因此可以在分子和分母之间消掉。
剩下的唯一因素将是节点 x i \mathbf{x}_i xi本身的条件分布 p ( x i ∣ p a i ) p(\mathbf{x}_i|pa_i) p(xi∣pai),以及任何节点 x k \mathbf{x}_k xk的条件分布,比如节点 x i \mathbf{x}_i xi位于 p ( x i ∣ p a i ) p(\mathbf{x}_i|pa_i) p(xi∣pai)的条件集中,换句话说, x i \mathbf{x}_i xi是 x k \mathbf{x}_k xk的父节点。
条件 p ( x i ∣ p a i ) p(\mathbf{x}_i|pa_i) p(xi∣pai)将依赖于节点 x i \mathbf{x}_i xi的父节点,而条件 p ( x k ∣ p a k ) p(\mathbf{x}_k|pa_k) p(xk∣pak)将依赖于 x i \mathbf{x}_i xi的子节点,以及共同父节点(co-parents)上的变量,即与节点 x k \mathbf{x}_k xk的父节点对应的变量,而不是与节点 x i \mathbf{x}_i xi对应的变量。
由父节点、子节点和共同父节点组成的节点集称为Markov blanket,如下图所示。我们可以把节点 x i \mathbf{x}_i xi的Markov blanket看作是把 x i \mathbf{x}_i xi从图的其余部分分离出来的最小节点集。注意,仅包含节点 x i \mathbf{x}_i xi的父节点和子节点是不够的,因为解释消失的现象意味着子节点的观察不会阻塞到共同父节点的路径。因此,我们还必须观察共同父节点(co-parents)。
![[PRML]图模型-条件独立_第12张图片](http://img.e-com-net.com/image/info8/1938529ecb034a9197a0099e9acfcca8.jpg)