【Flink】流式处理--DataStream API 开发
一、入门案例
Flink 流处理程序的一般流程
1) 获取 Flink 流处理执行环境
2) 构建 source
3) 数据处理
4) 构建 sink
需求:使用socket统计单词个数
步骤
1) 获取 Flink 批处理运行环境
2) 构建一个 socket 源
3) 使用 flink 操作进行单词统计
4) 打印
前提:安装nc服务
yum install -y nc
代码
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1、获取流处理运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.api.scala._
//2、构建socket流数据源,并指定IP地址和端口号
val testDataStream: DataStream[String] = env.socketTextStream("node01",7777)
//3、对接收到的数据穿换成单词元祖
val wordDataStream: DataStream[(String, Int)] = testDataStream.flatMap(_.split(" ")).map(_ -> 1)
//4、使用keyBy进行分流(分组)
//在批处理中针对于dataset, 如果分组需要使用groupby
//在流处理中针对于datastream, 如果分组(分流)使用keyBy
val groupedDataStream: KeyedStream[(String, Int), Tuple] = wordDataStream.keyBy(0)
//5、使用timeWindow指定窗口长度(每5秒计算一次)
//spark-》reduceBykeyAndWindow val windowDataStream: Windowed
val windowDataStream: WindowedStream[(String, Int), Tuple, TimeWindow] = groupedDataStream.timeWindow(
Time.seconds(5)
)
windowDataStream
//6、使用sum执行累加
val sumDataStream: DataStream[(String, Int)] = windowDataStream.sum(1)
sumDataStream.print()
env.execute()
}
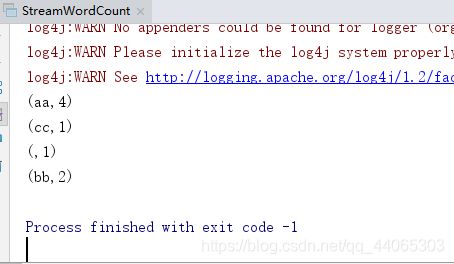
}开启nc服务输入数据

执行代码
二、输入数据集 Data Sources
Flink 中你可以使用 StreamExecutionEnvironment.addSource(source) 来为你的程序添
加数据来源。
Flink 已 经 提 供 了 若 干 实 现 好 了 的 source functions ,当 然 你 也 可 以
通 过 实 现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction
接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
1、Flink 在流处理上常见的 Source
Flink 在流处理上常见的 Source
,
Flink 在流处理上的 source 和在批处理上的 source
基本一致。
大致有 4 大类
基于本地集合的 source
(Collection-based-source)
基于文件的 source
(File-based-source)- 读取文本文件,即符合 TextInputFormat 规
范 的文件,并将其作为字符串返回
基于网络套接字的 source
(Socket-based-source)- 从 socket 读取。元素可以用分隔符
切分。
自定义的 source
(Custom-source)
2、基于集合的 source
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import scala.collection.immutable.{Queue, Stack}
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import org.apache.flink.api.scala._
object StreamDataSourceDemo {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
//0.用Element创建DataStream(fromElements)
val ds0: DataStream[String] = senv.fromElements("spark","flink")
ds0.print()
//1.用Tuple创建DataStream(fromElements)
val ds1: DataStream[(Int, String)] = senv.fromElements((1,"spark"),(2,"flink"))
ds1.print()
//2、用Array创建DataStream
val ds2: DataStream[String] = senv.fromCollection(Array("spark","flink"))
ds2.print()
//3、用ArrayBuffer创建DataStream
val ds3: DataStream[String] = senv.fromCollection(ArrayBuffer("spark","flink"))
ds3.print()
//4.用List创建DataStream
val ds4: DataStream[String] = senv.fromCollection(List("spark", "flink"))
ds4.print()
//5.用List创建DataStream
val ds5: DataStream[String] = senv.fromCollection(ListBuffer("spark", "flink"))
ds5.print()
//6.用Vector创建DataStream
val ds6: DataStream[String] = senv.fromCollection(Vector("spark", "flink"))
ds6.print()
//7.用Queue创建DataStream
val ds7: DataStream[String] = senv.fromCollection(Queue("spark", "flink"))
ds7.print()
//8.用Stack创建DataStream
val ds8: DataStream[String] = senv.fromCollection(Stack("spark", "flink"))
ds8.print()
//9.用Stream创建DataStream(Stream相当于lazy List,避免在中间过程中生 成不必要的集合)
val ds9: DataStream[String] = senv.fromCollection(Stream("spark", "flink"))
ds9.print()
//10.用Seq创建DataStream
val ds10: DataStream[String] = senv.fromCollection(Seq("spark", "flink"))
ds10.print()
//11.用Set创建DataStream(不支持)
//val ds11: DataStream[String] = senv.fromCollection(Set("spark", "flink"))
//ds11.print()
}
}
3、基于文件的 source(File-based-source)
import org.apache.flink.streaming.api.datastream.DataStreamSource
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
object StreamFileSourceDemo {
def main(args: Array[String]): Unit = {
//1.构建流处理的环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2.基于文件的source,构建数据集
val textDStream: DataStreamSource[String] = env.readTextFile("E:\\资料\\第二学年第二学期\\flink\\day02资料\\测试数据源\\wordcount.txt")
//3.打印输出
textDStream.print()
// 4.执行程序
env.execute("StreamFileSourceDemo")
}
}4、基于网络套接字的 source(Socket-based-source)
val source = env.socketTextStream("IP", PORT)