图文展示目标检测的现代发展历史
Author:Đặng Hà Thế Hiển
Translated by:哪咔吗
Date:2018-10-16
文章目录
- MiniMap
- 六大技术
- 一、图像分类
- 二、物体定位
- 三、物体检测
- 四、语义分割
- 五、实例分割
- 六、关键点检测
- 重要的CNN概念
- 一、特征^[A4,A5,A8]^(图案, 神经元的激活值, 特征检测器)
- 二、感受野^[A2]^(单个特征点对应的原图的区域)
- 三、Feature Map^[A1]^(隐藏层的某一个通道)
- 四、Feature Volume^[A3]^(卷积网络的某个隐藏层)
- 五、Fully connected layer as Feature Volume^[B2]^
- 六、反卷积^[A1]^ (fractional strided convolution, deconvolution, upsampling)
- 七、端到端的物体识别管道 (端到端训练系统)
- 重要的物体识别概念
- 一、边界框提案(感兴趣区域, 区域提案, 矩形框提案)
- 二、Intersection over Union(IoU, Jaccard similarity)
- 三、非极大值抑制 (NMS)
- 四、边界框回归 (边界框优化)
- 五、Prior box (default box, anchor box)
- 六、Box Matching Strategy
- 七、Hard negative example mining(负样本挖掘)
- 引用
MiniMap
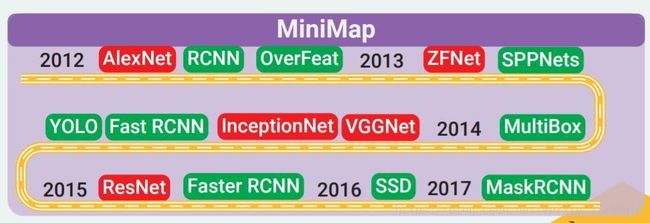
六大技术

一、图像分类
根据图像中的主要物体对图像进行分类。
数据集:MNIST,CIFAR,ImageNet
主体需要占据图像的大范围面积
二、物体定位
先预测原图中包含要检测物体的区域,然后对该区域进行图像分类操作。
数据集:ImageNet
三、物体检测
定位图像中包含的所有物体并对他们进行分类。通常包含两个步骤:推荐可能包含物体的区域+对这些区域进行分类。
数据集:PASCAL,COCO
四、语义分割
给图像中的每个像素归类到它所属的类别,例如人、羊、草地
数据集:PASCAL,COCO
五、实例分割
给图像中的每个像素归类到它所属的类别,以及所属的实例。
数据集:PASCAL,COCO
六、关键点检测
检测物体的关键点,这些关键点是预先定义好的,例如检测一个人的身体关节关键点或者脸部关键点。
数据集:COCO
重要的CNN概念
一、特征[A4,A5,A8](图案, 神经元的激活值, 特征检测器)
当图像的一个特定区域(神经元的感受野范围)中出现了一个特定的图案(特征)时,那么这个区域对应的隐藏的神经元就会被激活。
一个神经元对应的激活图案可以通过以下方式可视化
- 优化输入区域以最大化神经元的激活值(deep dream)
- 将神经元激活值对应的输入像素的梯度或者经引导的梯度进行可视化。(反向传播和经引导后的反向传播)
- 将训练集中激活神经元最多的图像区域进行可视化

二、感受野[A2](单个特征点对应的原图的区域)
输入图像的区域会影响特征的激活。换句话说,单个特征点就是原图中某个区域的映射。
通常,高层的单个特征点会有更大的感受野,这让它可以学会抽取更复杂、抽象的图案。卷积网络结构决定了每一层感受野的变化。
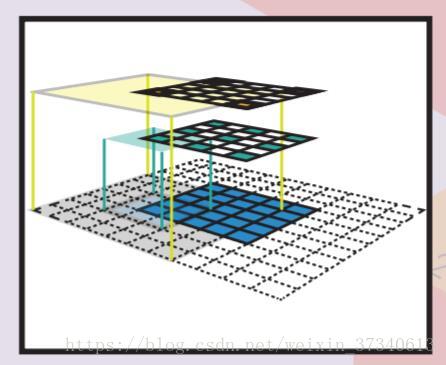
三、Feature Map[A1](隐藏层的某一个通道)
通过将同一个特征检测器以滑窗的方式作用在一副图像的不同位置上(卷积),就得到了一系列的特征。一张特征图上的所有特征(点)拥有同样的感受野范围,并且他们都在原图中寻找同样的激活图案,只是位于不同的位置。这种特性造就了卷积网络的空间不变性。

四、Feature Volume[A3](卷积网络的某个隐藏层)
一系列的特征图,每个特征图都在上一层特征图中寻找特定的图案。所有特征都拥有相同的感受野范围。

五、Fully connected layer as Feature Volume[B2]
全连接层通常被连接到卷积网络的末尾作为分类层。
具有k个隐藏节点的全连接层可以看做是11k的特征块,这个特征块的每个特征层只有一个特征点,并且这个特征点的感受野覆盖了整幅图像。
一个全连接层中的权重矩阵W可以被转化为卷积核。在形如whd的卷积特征块上作用一个whk的卷积核可以得到一个11k的特征块(作用效果等于具有k个节点的全连接层,但是权重数量是全连接层的1/(w*h))。通过这种方式,我们可以把卷积网络作用在任意尺寸的图像上。

六、反卷积[A1] (fractional strided convolution, deconvolution, upsampling)
反卷积是对卷积中的梯度的反向传播。换句话说,它是卷积层的反向传递。一个反卷积操作可以看做是一个普通的卷积操作,只是需要事先在原特征图的特征点之间插入0值。

上述左图中,红色的输入特征点影响了输出特征图中的左上角的4个特征点,因此,它从左上角的4个特征点接收反向传播的梯度。这个梯度反向传播的过程可以表示为右图显示的反卷积操作。
七、端到端的物体识别管道 (端到端训练系统)
在一个物体识别的管道中,可以通过优化某个特殊的损失函数以实现所有阶段(预处理,区域推荐,分类,后处理)共同训练的目的。这个特殊的损失函数区别于每个阶段独有的损失函数。这种端到端的管道与传统的识别管道是相反的,传统的识别管道把各个阶段用一种不可微分的方式连接在一起(这使得方向传播无法贯穿整个识别管道)。在这种方式下,我们无法知道改变某个阶段的参数对整个识别管道的影响,因此每个识别阶段都要被单独训练或轮流训练。
重要的物体识别概念
一、边界框提案(感兴趣区域, 区域提案, 矩形框提案)
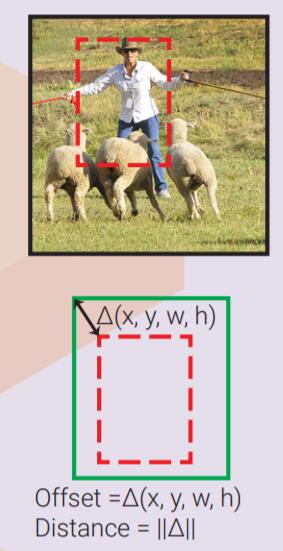
这是一个可能含有一个物体的相对于原图的边界框。这些边界框可以由一些启发式的搜索算法给出,如:objectness,selective search。也可以由一个区域提案网络(RPN)结合特征图给出。一个矩形边界框有两种方式表示,一种是给出左上角和右下角的坐标(x0,y0,x1,y1),另一种(更普遍)是给出中心点坐标以及宽度和高度(x,y,w,h)。一个矩形框通常都包含该矩形框中包含一个物体的可能性。
两个矩形框之间的差异通常用代表它们两者的向量的L2距离来表示。其中w和h在计算距离前会先被对数化。
L2距离即L2-norm(L2范式),即欧式距离
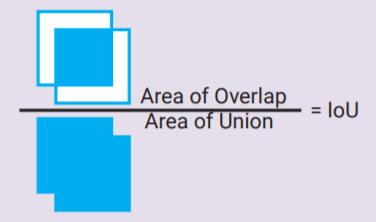
二、Intersection over Union(IoU, Jaccard similarity)
一种度量两个矩形框的相似性的方法。即两个矩形框的交集与它们的并集的比值。
三、非极大值抑制 (NMS)
用来合并重叠的矩形框(提案或者是识别结果)。与更高置信度的矩形框高度重叠(IoU>预设的阈值)的矩形框将被抑制(移除)

四、边界框回归 (边界框优化)
即使推荐的矩形框比较小,没有把物体全部包含在里面,但是我们仍然能够通过观察矩形框对应的图案,推测出能更好的包围物体的矩形框。因此,我们可以训练一个回归器,它接收矩形框对应的特征并且预测该矩形框与实际矩形框之间的差异,进而优化矩形框。回归器有两种,一种是针对特定物体类别的回归器,还有一种是所有类别通用的回归器。矩形框回归器通常伴随着一个矩形框分类器,该分类器用来预测这个矩形框中含有物体的置信度。分类器同样有针对特定类别的和类别通用的两种形式。如果没有定义prior boxes,那么输入的矩形框将扮演它的角色。

五、Prior box (default box, anchor box)
我们可以训练多个矩形框回归器,每个回归器都对应自己独立的prior box(预设矩形框),它们以相同的矩形框区域作为输入,然后它们学习预测各自的prior box和ground truth box的偏移。通过这种方式,对应不同prior box的回归器可以学会预测具有不同属性的矩形框(长宽比、尺寸、位置)。prior box可以预先设置好(相对于输入矩形框),也可以通过聚类的方式进行学习。合适的矩形框回归策略对训练的收敛起到非常重要的作用。

六、Box Matching Strategy
一个矩形框回归器无法预测一个距离输入区域(或者是prior box)很远的物体的矩形框。因此我们需要一个矩形框匹配策略以确定哪个prior box和ground truth box的重叠度更高。每个成功的匹配都是回归的训练样本。可行的策略有:
- Multibox:将每个ground truth box和它对应的具有最高IoU的prior box匹配(匹配数量=ground truth box的数量)
- SSD,Faster R-CNN:将每个prior box和与它的IoU超过0.5的ground truth box进行匹配(匹配数量>ground truth box的数量,一个ground truth box可能与多个prior box匹配)

左图:一个具有3个prior boxes(虚线)的区域提案(红色虚线),绿色实线对应的是ground truth box
中图:这三个边界框回归器只关注红色框对应的输入区域,并且试图根据它们各自的prior box预测出ground truth box
右图:根据Multibox策略,ground truth box会与蓝色矩形框匹配,并且该匹配会作为训练样本用于训练回归器
七、Hard negative example mining(负样本挖掘)
对于每一个prior box都有一个边界框分类器用来分析该矩形框中含有物体的可能性。在矩形框匹配之后,每个成功匹配的prior box都是这个分类器的正样本,所有其它prior box都是负样本。如果我们使用所有这些负样本,那么在正样本和负样本之间存在明显的不平衡。有效的解决方法是:随机选择一些负样本(Faster R-CNN),或者选择那些分类器分类效果最差的样本(SSD),通过这些手段让负样本和正样本之间的比例大概是3:1。
引用
[A1]: Dumoulin, Vincent, and Francesco Visin. “A guide to convolution arithmetic for deep learning.”
[A2]:The-Hien Dang-Ha, “A guide to receptive field arithmetic for CNN”
[A3]:Karpathy, Andrej. “Cs231n: Convolutional neural networks for visual recognition.”
[A4]:Zeiler, Matthew D., and Rob Fergus. “Visualizing and understanding convolutional networks.”
[A5]:Mordvintsev, Alexander, Christopher Olah, and Mike Tyka. “Inceptionism: Going deeper into neural networks.”
[A6]:Adit Deshpande, “The 9 Deep Learning Papers You Need To Know About”
[A7]:Shelhamer, Evan, Jonathan Long, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.”
[A8]:Springenberg, Jost Tobias, et al. “Striving for simplicity: The all convolutional net.”
[A9]:Dhruv Parthasarathy “A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN”
[B1]:Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.”
[B2]:Zeiler, Matthew D., and Rob Fergus. “Visualizing and understanding convolutional networks.”
[B3]:Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.”
[B4]:Szegedy, Christian, et al. “Going deeper with convolutions.”
[B5]:He, Kaiming, et al. “Deep residual learning for image recognition.”
[C1]:Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.”
[C2]:Sermanet, Pierre, et al. “Overfeat: Integrated recognition, localization and detection using convolutional networks.”
[C3]:He, Kaiming, et al. “Spatial pyramid pooling in deep convolutional networks for visual recognition.”
[C4]:Szegedy, Christian, et al. “Scalable, high-quality object detection.”
[C5]:Girshick, Ross. “Fast r-cnn.”
[C6]:Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.”
[C7]:Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.”
[C8]:Liu, Wei, et al. “SSD: Single shot multibox detector.”
[C9]:He, Kaiming, et al. “Mask R-CNN.”