Numpy鸢尾花
import numpy
from sklearn.datasets import load_iris
#从sklearn包自带的数据集中读出鸢尾花数据集data
iris_data = load_iris()
# 查看data类型,包含哪些数据
print("数据类型: ", type(iris_data))
print("包含数据: ", iris_data.keys()) # 看包含哪些数据
plt.scatter(X[:, 0], X[:,1])
plt.show()
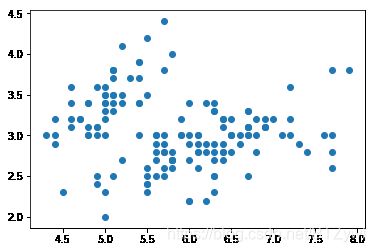
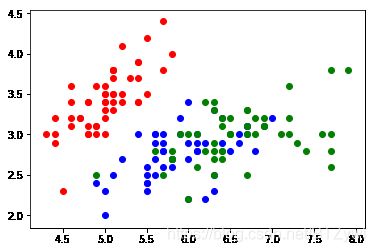
y = iris.target #y为标签
plt.scatter(X[y==0, 0], X[y==0, 1], color='red')
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue')
plt.scatter(X[y==2, 0], X[y==2, 1], color='green')
plt.show()
plt.scatter(X[y==0, 0], X[y==0, 1], color='red', marker='o') plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='+') plt.scatter(X[y==2, 0], X[y==2, 1], color='green', marker='x') plt.show()
X = iris.data[:,2:]#后两个
plt.scatter(X[y==0, 0], X[y==0, 1], color='red', marker='o')
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='+')
plt.scatter(X[y==2, 0], X[y==2, 1], color='green', marker='x')
plt.show()

解释:
