《Python机器学习基础教程》学习笔记(8) 核支持向量机
线性模型与非线性特征
线性模型在低维空间中可能非常受限,比如对于下面这个非单调二分类数据集,线性SVM做出的决策边界:


可以看出,线性SVM对这个数据集并不能给出较好的结果。
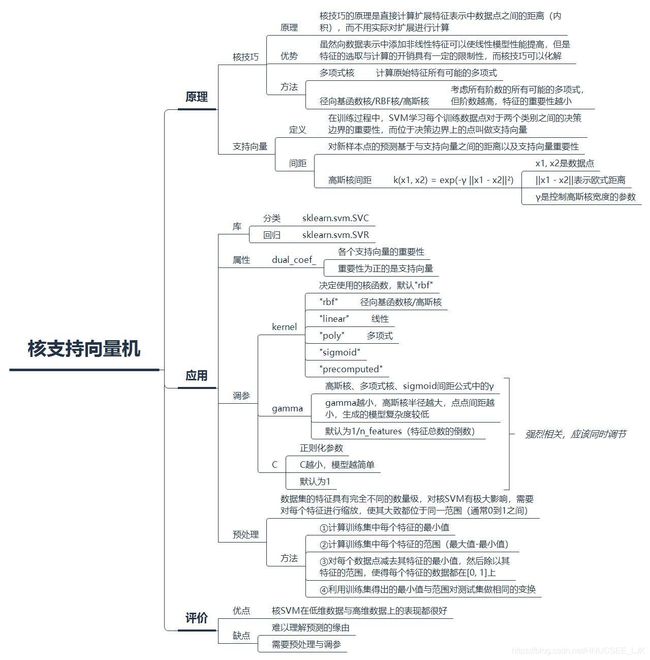
现在我们对数据集的特征进行扩展,比如添加第二个特征的平方(feature1 ** 2)作为第三个特征。这时,再看看线性SVM给出的决策边界,在高维上是线性的,但在低维上已经不是线性的了,并且给出了一个较好的结果。

核技巧
虽然向数据表示中添加非线性特征可以使线性模型性能提高,但是特征的选取与计算的开销具有一定的限制性,而核技巧可以化解。核技巧的原理是直接计算扩展特征表示中数据点之间的距离(内积),而不用实际对扩展进行计算。对于支持向量机,将数据映射到更高维的空间中有两种常用方法:一是多项式核,计算原始特征所有可能的多项式;二是径向基函数核(RBF核),也叫高斯核,考虑所有阶数的所有可能的多项式,但阶数越高,特征的重要性越小。
在训练过程中,SVM学习每个训练数据点对于两个类别之间的决策边界的重要性,而位于决策边界上的点叫做支持向量。而对新样本点的预测基于与支持向量之间的距离以及支持向量重要性,此时核技巧的作用就在于对数据点之间的距离的定义,例如高斯核的给出的数据点之间的距离:k(x1, x2) = exp(-γ ||x1 - x2||²),x1, x2是数据点,||x1 - x2||表示欧式距离,γ是控制高斯核宽度的参数。
在sklearn中,核SVM的分类模型与回归模型分别通过sklearn.svm.SVC与sklearn.svm.SVR调用。模型有一属性dual_coef_,存储了各个支持向量的重要性,其中,重要性为正的是支持向量。
调参
核SVM的参数主要有kernel,gamma,C。
kernel:决定使用的核函数。有以下几个选项,默认为rbf。
"rbf":径向基函数
"linear":线性
"poly":多项式
"sigmoid"
"precomputed"
gamma:高斯核、多项式核、sigmoid间距公式中的γ,gamma越小,高斯核半径越大,点点间距越小,生成的模型复杂度较低。默认为1/n_features(特征总数的倒数)。
C:正则化参数。C越小,模型越简单。默认为1。
其中,gamma与C是强相关的,应该同时调节。
以下是在选取高斯核的情况下,不同的gamma与C值对决策边界的影响:

预处理
在未预处理的情况下,核SVM对乳腺癌的预测:
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
stratify=cancer.target, random_state=0)
svc = SVC().fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(svc.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}\n".format(svc.score(X_test, y_test)))Accuracy on training set: 1.000 Accuracy on test set: 0.629
可以看出,模型存在着相当严重的过拟合。由于乳腺癌的各特征的数量级完全不同,而数据集的特征具有完全不同的数量级对核SVM有极大影响,所以需要对每个特征进行缩放,使其大致都位于同一范围(通常0到1之间)。
#①计算训练集中每个特征的最小值
min_on_training = X_train.min(axis=0)
#②计算训练集中每个特征的范围(最大值-最小值)
range_on_training = (X_train - min_on_training).max(axis=0)
#③对每个数据点减去其特征的最小值,然后除以其特征的范围,使得每个特征的数据都在[0, 1]上
X_train_scaled = (X_train - min_on_training) / range_on_training
#④利用训练集得出的最小值与范围对测试集做相同的变换
X_test_scaled = (X_test - min_on_training) / range_on_training再看一下缩放后的结果,可以看出预处理的作用很大:
svc = SVC().fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(svc.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}\n".format(svc.score(X_test_scaled, y_test)))Accuracy on training set: 0.955 Accuracy on test set: 0.951
而如果对C与gamma进行调参,能得到更好的精度。
评价
核SVM在低维数据与高维数据上的表现都很好,但难以理解模型预测的理由,并且需要预处理与调参。