Weakly Supervised Action Localization by Sparse Temporal Pooling Network
摘要
1.介绍
这篇文章的主要贡献:
•我们引入了原理性深层神经网络架构,用于对未修剪的视频进行弱监督动作识别和定位,其中从网络识别的稀疏子帧中检测动作。
•我们提出一种技术来计算时间类激活映射,然后使用学习的注意力权重对时间动作建议进行本地化目标动作。
•所提出的弱监督动作定位技术在THUMOS14 [14]上实现了最新的准确性,并在ActivityNet1.3 [12]的首次公开评估中表现出色。
本文的其余部分安排如下。 我们在第2节中讨论相关工作,并在第3节中描述我们的动作局部化算法。第4节介绍了我们的实验的细节,第5节总结本文
2相关工工作 (略)
3 Proposed 算法
我们仅基于视频级动作标签描述了我们的弱监督时间动作定位算法。这个目标是通过设计一个基于稀疏子段的视频分类的深度神经网络和识别与目标类别相关的时间间隔来实现的。
3.1大致想法
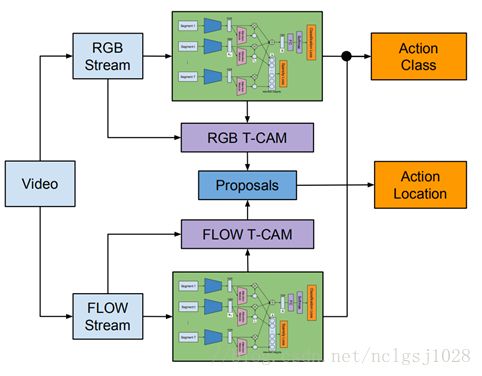
我们声称可以通过识别一系列呈现重要动作组件的关键片段来从视频中识别动作。我们的算法提出了一种新颖的深度神经网络,使用一组具有代表性和独特的片段来预测每个视频的类别标签,以针对从输入视频自动选择的动作。请注意,所提出的深层神经网络是为分类而设计的,但能够测量每个分段在预测分类标签中的重要性。在每个视频中查找相关类别之后,我们通过计算各个片段的时间关注度,生成时间行为建议,以及汇总相关建议来估计与所标识的动作相对应的时间间隔。我们的方法仅依赖于视频级别标签来执行时间动作本地化,并提供了一种方法来提取关键段并确定与目标动作相对应的适当时间间隔。使用我们的框架,可以在单个视频中识别和本地化多个操作。图2说明了我们的弱监督动作识别组件的深层神经网络架构。我们描述了我们的算法的每个步骤如下。

图2:我们的弱监督时间动作定位的神经网络架构。 我们首先使用预训练网络从一组均匀采样的视频片段中提取特征表示。 注意模块生成对应于各个特征的注意力权重,这些特征被用于通过时间加权平均池合计算视频级表示。 该表示被赋予分类模块,并且在这个注意权重向量上施加l1损失来强制执行稀疏约束。
3.2. Action Classification
为了预测每个视频中的类别标签,我们首先从输入视频中采样一组视频片段,并使用预训练的卷积神经网络从每个片段提取特征表示。 然后将这些表示中的每一个呈现给由两个全连接(FC)层和位于两个FC层之间的ReLU层组成的注意模块。 第二个FC层的输出被赋予一个S形函数,迫使生成的注意力权重在0和1之间归一化。然后使用这些注意力权重调整时间平均池 - 特征向量的加权总和 - 创建视频级别表示。 我们通过FC和S形图层传递这个表示来获得分类分数。
形式上,Xt∈Rm是从时间t中心的视频片段提取的m维特征表示,λt是相应的关注权值。 视频等级表示(由![]() 表示)对应于注意加权时间平均池,这是由公式:
表示)对应于注意加权时间平均池,这是由公式:

其中λ = (λ1, . . . , λT )T是来自sigmoid函数的标量输出的矢量以标准化激活范围,并且T是为分类而配置的视频段的总数。 注意力权重向量λ以类不可知的方式用稀疏性约束来学习。这有助于识别与任何感兴趣的动作相关的时间片段并估计动作候选者的时间间隔。
该网络中的损失函数由分类损失和稀疏损失两个项组成。![]()
其中Lclass表示在视频级别上计算的分类损失,稀疏性是稀疏损失,β是控制这两个项之间的权衡的常数。分类损失是基于ground-truth和![]() 之间标准的多标签交叉熵损失(经过如图2所示的几个层次之后),而稀疏损失则由l1注意力损失权重为||λ|| 1。由于我们对每个注意权重λt都应用了一个Sigmoid函数,所有的注意权值都可能有接近0-1的二进制值,这是由于“l1损失”造成的。请注意,集成稀疏损失与我们声称可以通过视频中关键段的稀疏子集识别动作是一致的。
之间标准的多标签交叉熵损失(经过如图2所示的几个层次之后),而稀疏损失则由l1注意力损失权重为||λ|| 1。由于我们对每个注意权重λt都应用了一个Sigmoid函数,所有的注意权值都可能有接近0-1的二进制值,这是由于“l1损失”造成的。请注意,集成稀疏损失与我们声称可以通过视频中关键段的稀疏子集识别动作是一致的。
为了确定与目标事件相对应的时间间隔,我们首先提取一些行动间隔候选。 基于[46]中的想法,我们推导出时间域中的一维类激活映射,称为时间类激活映射(T-CAM)。 通过Wc(k)表示分类模型参数w中的第k个元素,对应于类c。类c的最后sigmoid层的输入是

T-CAM,记为![]() ,表示在时间步骤t该表示与各个类别的相关性,其中给出用于类别c(c = 1,...,C)的每个元素
,表示在时间步骤t该表示与各个类别的相关性,其中给出用于类别c(c = 1,...,C)的每个元素![]()
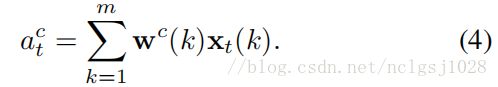
图3给出了由所提出的算法给出的视频中的attention weights和T-CAM输出的示例。 我们可以观察到,attention weights和T-CAM有效地突出了区分性时间区域。 请注意,一些具有较大定位权重的时间间隔不对应于较大的T-CAM值,因为这些间隔可能代表了其他干扰行为。 attention weights测量时间视频片段的泛化动作,而T-CAM呈现类别特定信息。

图3:THUMOS14 [14]数据集中ThrowDiscus类的真实状况时间间隔,时间关注和T-CAM示例视频的示意图。 图中的横轴表示时间索引。 在这个例子中,ThrowDiscus的T-CAM值提供了准确的动作定位信息。 请注意, temporal attention weights在几个不符合真实状况注释的地点很大。 这是因为时间关注权重是以类别不可知的方式训练的。
3.5. Temporal Action Localization
对于输入视频,我们首先根据3.2节描述的深度神经网络的视频水平分类评分来确定相关的类标签。 对于每个相关动作,我们生成时间提议,即一个可能由多个片段组成的时间间隔及其class labels 和confidence scores。提议对应于潜在包含目标动作的视频片段,并使用T -CAM在我们的算法中。
为了产生 temporal proposals,我们首先使用公式(4)作为![]() ,从RGB和 flow streams计算TCAMs,并利用它们导出加权
,从RGB和 flow streams计算TCAMs,并利用它们导出加权![]() as:
as:

注意,λt是稀疏向量λ的元素,乘以λt可以解释为从以下S形函数中对值进行的软选择。与[46]类似,我们将阈值应用于加权![]() 以分割这些信号。然后,temporal proposals是独立地从每个流中提取的一维连通分量。使用加权T-CAM生成action proposals,而不是直接从attention weights中产生,因为每个建议都应包含一种行为。 任意的,我们在阈值化之前对采样段之间的加权T-CAM信号进行线性内插,以改进提案的临时解决方案。
以分割这些信号。然后,temporal proposals是独立地从每个流中提取的一维连通分量。使用加权T-CAM生成action proposals,而不是直接从attention weights中产生,因为每个建议都应包含一种行为。 任意的,我们在阈值化之前对采样段之间的加权T-CAM信号进行线性内插,以改进提案的临时解决方案。
与原始的只保留最大的边框的CAM-based bounding box proposals [46]不同,我们保留所有通过预定义阈值的连通组件。由[tstart,tend]定义的每个 proposal 被分配一个分数作为该提案中所有框架的加权平均T-CAM:
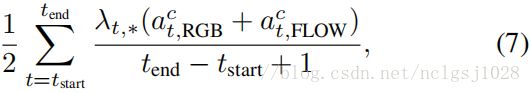
其中*∈{RGB,FLOW}。 该值对应于类c的每个流中的temporal proposal分数。 最后,我们独立地执行每个类的时间提议中的非最大抑制,以去除高度重叠的检测。
3.6. Discussion
我们的算法试图通过分别估计稀疏注attention weights和T-CAM来针对通用和特定行为临时地定位未修剪视频中的动作。 我们认为,与现有的UntrimmedNet [35]算法相比,该方法具有原理性和新颖性,因为它具有独特的深度神经网络结构,具有分类和稀疏损失,其动作定位过程基于完全不同 利用T-CAM利用针对具体课题的行动建议。 请注意[35]遵循[2]中使用的类似框架,其中softmax函数用于两个操作类和提议; 它在处理单个视频中的多个操作类和实例时具有关键限制。
4 实验和测试不做翻译
5.结论
我们提出了一种新的弱监督时间交流定位技术,该技术基于具有分类和稀疏性损失的深度神经网络。 分类是通过评估由分段级特征的稀疏加权平均值给出的视频级表示来执行的,其中稀疏系数通过我们的深度神经网络中的稀疏性损失来学习。 对于弱超时的时间动作定位,提取一维行动建议,从中选择与目标类相关的建议以呈现事件的时间间隔。 所提出的方法实现了THUMOS14数据集中最新的结果,并且据我们所知,我们首先报告了ActivityNet1.3数据集上的弱监督时间动作定位结果。




