Flink 单并行度内使用多线程来提高任务的整体性能
分析痛点
笔者线上有一个 Flink 任务消费 Kafka 数据,将数据转换后,在 Flink 的 Sink 算子内部调用第三方 api 将数据上报到第三方的数据分析平台。这里使用批量同步 api,即:每 50 条数据请求一次第三方接口,可以通过批量 api 来提高请求效率。由于调用的外网接口,所以每次调用 api 比较耗时。假如批次大小为 50,且请求接口的平均响应时间为 50ms,使用同步 api,因此第一次请求响应以后才会发起第二次请求。请求示意图如下所示:
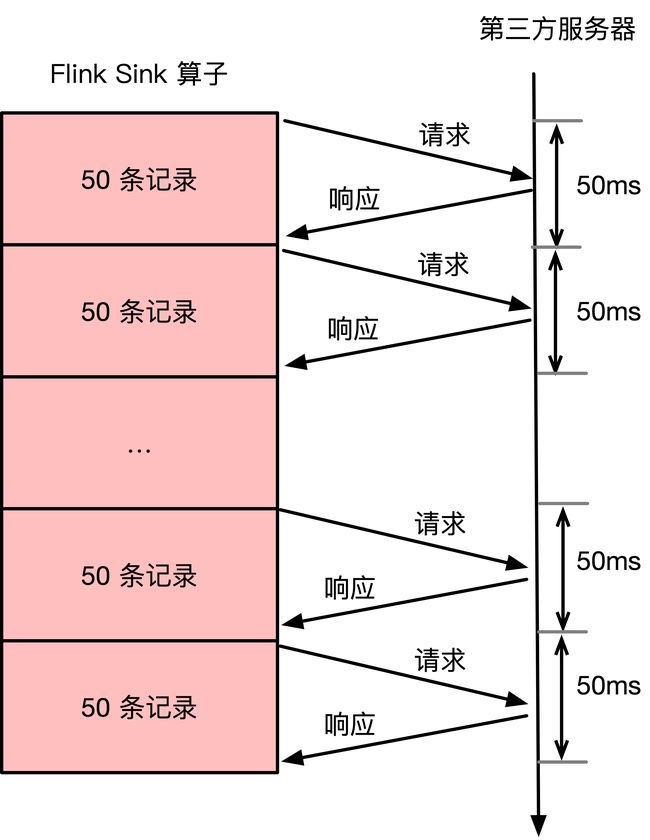
平均下来,每 50 ms 向第三方服务器发送 50 条数据,也就是每个并行度 1 秒钟处理 1000 条数据。假设当前业务数据量为每秒 10 万条数据,那么 Flink Sink 算子的并行度需要设置为 100 才能正常处理线上数据。从 Flink 资源分配来讲,100 个并行度需要申请 100 颗 CPU,因此当前 Flink 任务需要占用集群中 100 颗 CPU 以及不少的内存资。请问此时 Flink Sink 算子的 CPU 或者内存压力大吗?上述请求示意图可以看出 Flink 任务发出请求到响应这 50 ms 期间,Flink Sink 算子只是在 wait,并没有实质性的工作。因此,CPU 使用率肯定很低,当前任务的瓶颈明显在网络 IO。最后结论是 Flink 任务申请了 100 颗 CPU,导致 yarn 或其他资源调度框架没有资源了,但是这 100 颗 CPU 的使用率并不高,这里能不能优化通过提高 CPU 的使用率,从而少申请一些 CPU 呢?
同步批量请求优化为异步请求
首先可能想到可能是将同步请求改为异步请求,使得任务不会阻塞在网络请求这一环节,请求示意图如下所示。
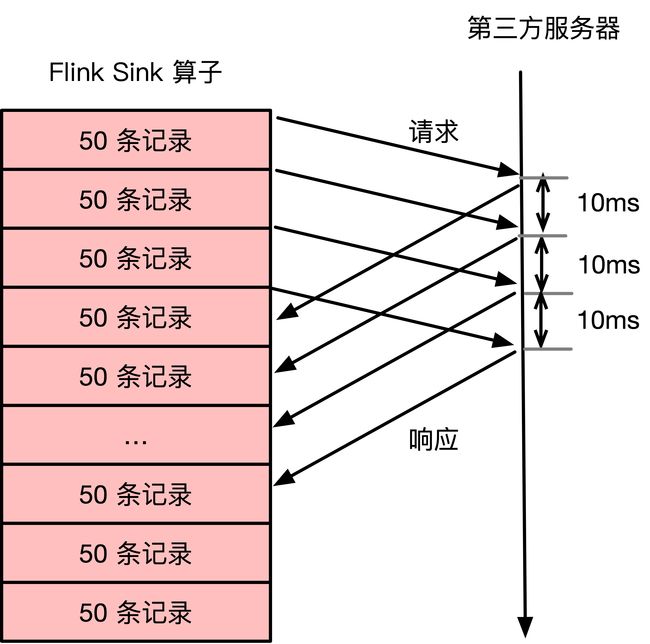
异步请求相比同步请求而言,优化点在于每次发出请求时,不需要等待请求响应后再发送下一次请求,而是当下一批次的 50 条数据准备好之后,直接向第三方服务器发送请求。每次发送请求后,Flink Sink 算子的客户端需要注册监听器来等待响应,当响应失败时需要做重试或者回滚策略。通过异步请求的方式,可以优化网络瓶颈,假如 Flink Sink 算子的单个并行度平均 10ms 接收到 50 条数据,那么使用异步 api 的方式平均 1 秒可以处理 5000 条数据,整个 Flink 任务的性能提高了 5 倍。对于每秒 10 万数据量的业务,这里仅需要申请 20 颗 CPU 资源即可。关于异步 api 的具体使用,可以根据场景具体设计,这里不详细讨论。
多线程 Client 模式
对于一些不支持异步 api 的场景,可能并不能使用上述优化方案,同样,为了提高 CPU 使用率,可以在 Flink Sink 端使用多线程的方案。如下图所示,可以在 Flink Sink 端开启 5 个请求第三方服务器的 Client 线程:Client1、Client2、Client3、Client4、Client5。这五个线程内分别使用同步批量请求的 Client,单个 Client 还是保持 50 条记录为一个批次,即 50 条记录请求一次第三方 api。请求第三方 api 耗时主要在于网络 IO(性能瓶颈在于网络请求延迟),因此如果变成 5 个 Client 线程,每个 Client 的单次请求平均耗时还能保持在 50ms,除非网络请求已经达到了带宽上限或整个任务又遇到其他瓶颈。所以,多线程模式下使用同步批量 api 也能将请求效率提升 5 倍。
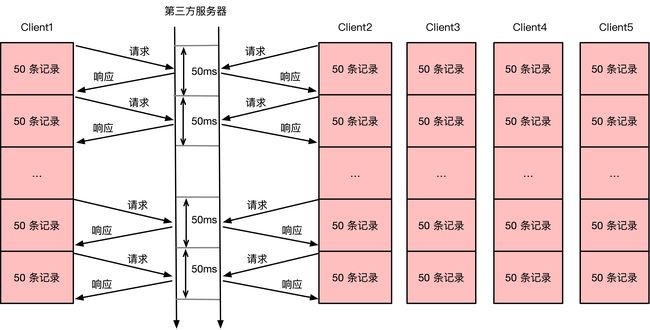
多线程的方案,不仅限于请求第三方接口,对于非 CPU 密集型的任务都可以使用该方案在降低 CPU 数量的同时,使得单个 CPU 承担多个线程的工作,从而提高 CPU 利用率。例如:请求 HBase 的任务或磁盘 IO 是瓶颈的任务,都可以降低任务的并行度,使得每个并行度内处理多个线程。
Flink 算子内多线程实现
Sink 算子的单个并行度内现在有 5 个 Client 用于消费数据,但 Sink 算子的数据都来自于上游算子。如下图所示,一个简单的实现方式是 Sink 算子接收到上游数据后通过轮循或随机的策略将数据分发给 5 个 Client 线程。
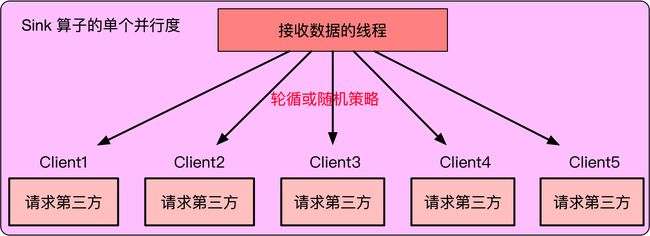
但是轮循或者随机策略会存在问题,假如 5 个 Client 中 Client3 线程消费较慢,会导致给 Client3 分发数据时被阻塞,从而使得其他正常消费的线程 Client1、2、4、5 也被分发不到数据。
为了解决上述问题,可以在 Sink 算子内申请一个数据缓冲队列,队列有先进先出(FIFO)的特性。Sink 算子接收到的数据直接插入到队列尾部,五个 Client 线程不断地从队首取数据并消费,即:Sink 算子先接收的数据 Client 先消费,后接收的数据 Client 后消费。若队列一直是满的,说明 Client 线程消费较慢、Sink 算子上游生产数据较快。若队列一直为空,说明 Client 线程消费较快、Sink 算子的上游生产数据较慢。五个线程共用同一个队列完美地解决了单个线程消费慢的问题,当 Client3 线程阻塞时,不影响其他线程从队列中消费数据。这里使用队列还起到*削峰填谷*的作用。

代码实现
原理明白了,具体代码如下所示,首先是消费数据的 Client 线程代码,代码逻辑很简单,一直从 bufferQueue 中 poll 数据,取出数据后,执行相应的消费逻辑即可,在本案例中消费逻辑便是 client 积攒批次并调用第三方 api。
public class MultiThreadConsumerClient implements Runnable {
private LinkedBlockingQueue bufferQueue;
public MultiThreadConsumerClient(LinkedBlockingQueue bufferQueue) {
this.bufferQueue = bufferQueue;
}
@Override
public void run() {
String entity;
while (true){
// 从 bufferQueue 的队首消费数据
entity = bufferQueue.poll();
// 执行 client 消费数据的逻辑
doSomething(entity);
}
}
// client 消费数据的逻辑
private void doSomething(String entity) {
// client 积攒批次并调用第三方 api
}
} Sink 算子代码如下所示,在 open 方法中需要初始化线程池、数据缓冲队列并创建开启消费者线程,在 invoke 方法中只需要往 bufferQueue 的队尾添加数据即可。
public class MultiThreadConsumerSink extends RichSinkFunction {
// Client 线程的默认数量
private final int DEFAULT_CLIENT_THREAD_NUM = 5;
// 数据缓冲队列的默认容量
private final int DEFAULT_QUEUE_CAPACITY = 5000;
private LinkedBlockingQueue bufferQueue;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// new 一个容量为 DEFAULT_CLIENT_THREAD_NUM 的线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(DEFAULT_CLIENT_THREAD_NUM, DEFAULT_CLIENT_THREAD_NUM,
0L,TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
// new 一个容量为 DEFAULT_QUEUE_CAPACITY 的数据缓冲队列
this.bufferQueue = Queues.newLinkedBlockingQueue(DEFAULT_QUEUE_CAPACITY);
// 创建并开启消费者线程
MultiThreadConsumerClient consumerClient = new MultiThreadConsumerClient(bufferQueue);
for (int i=0; i < DEFAULT_CLIENT_THREAD_NUM; i ) {
threadPoolExecutor.execute(consumerClient);
}
}
@Override
public void invoke(String value, Context context) throws Exception {
// 往 bufferQueue 的队尾添加数据
bufferQueue.put(value);
}
} 代码逻辑相对比较简答,请问上述 Sink 能保证 Exactly Once 吗?答:不能保证 Exactly Once,Flink 要想端对端保证 Exactly Once,必须要求外部组件支持事务,这里第三方接口明显不支持事务。那么上述 Sink 能保证 At Lease Once 吗?言外之意,上述 Sink 会丢数据吗?答:会丢数据。因为上述案例中使用的批量 api 来消费数据,假如批量 api 是每积攒 50 条数据请求一次第三方接口,当 Checkpoint 时可能只积攒了 30 条数据,所以 Checkpoint 时内存中可能还有数据未发送到外部系统。而且 Checkpoint 时数据缓冲队列中可能还有缓存的数据,因此上述 Sink 在 Checkpoint 时会出现 Checkpoint 之前的数据未完全消费的情况。
例如,Flink 任务消费的 Kafka 数据,当 Checkpoint 时,Flink 任务消费到 offset 为 10000 的位置,但实际上 offset 10000 之前的一小部分数据可能还在数据缓冲队列中还未完全消费,或者因为没积攒够一定批次所以数据缓存在 client 中,并未请求到第三方。当任务失败后,Flink 任务从 Checkpoint 处恢复,会从 offset 为 10000 的位置开始消费,此时 offset 10000 之前的一小部分缓存在内存缓冲队列中的数据不会再去消费,于是就出现了丢数据情况。
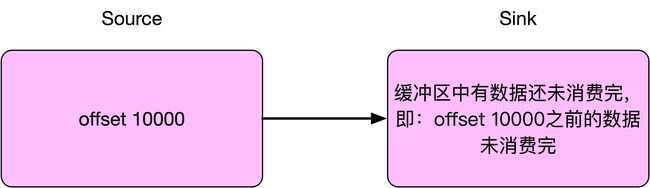
处理丢数据情况
如何保证数据不丢失呢?很简单,可以在 Checkpoint 时强制将数据缓冲区的数据全部消费完,并对 client 执行过 flush 操作,保证 client 端不会缓存数据。实现思路:Sink 算子可以实现 CheckpointedFunction 接口,当 Checkpoint 时,会调用 snapshotState 方法,方法内可以触发 client 的 flush 操作。但 client 在 MultiThreadConsumerClient 对应的五个线程中,这里需要考虑线程同步的问题,即:Sink 算子的 snapshotState 方法中做一个操作,要使得五个 Client 线程感知到当前正在执行 Checkpoint,此时应该把数据缓冲区的数据全部消费完,并对 client 执行过 flush 操作。
如何实现呢?需要借助 CyclicBarrier,CyclicBarrier 会让所有线程都等待某个操作完成后才会继续下一步行动。在这里可以使用 CyclicBarrier,让 Checkpoint 等待所有的 client 将数据缓冲区的数据全部消费完并对 client 执行过 flush 操作,言外之意,offset 10000 之前的数据必须全部消费完成才允许 Checkpoint 执行完成。这样就可以保证 Checkpoint 时不会有数据被缓存在内存,可以保证数据源 offset 10000 之前的数据都消费完成。
MultiThreadConsumerSink 具体代码如下所示:
public class MultiThreadConsumerSink extends RichSinkFunction implements CheckpointedFunction {
private Logger LOG = LoggerFactory.getLogger(MultiThreadConsumerSink.class);
// Client 线程的默认数量
private final int DEFAULT_CLIENT_THREAD_NUM = 5;
// 数据缓冲队列的默认容量
private final int DEFAULT_QUEUE_CAPACITY = 5000;
private LinkedBlockingQueue bufferQueue;
private CyclicBarrier clientBarrier;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// new 一个容量为 DEFAULT_CLIENT_THREAD_NUM 的线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(DEFAULT_CLIENT_THREAD_NUM, DEFAULT_CLIENT_THREAD_NUM,
0L,TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
// new 一个容量为 DEFAULT_QUEUE_CAPACITY 的数据缓冲队列
this.bufferQueue = Queues.newLinkedBlockingQueue(DEFAULT_QUEUE_CAPACITY);
// barrier 需要拦截 (DEFAULT_CLIENT_THREAD_NUM 1) 个线程
this.clientBarrier = new CyclicBarrier(DEFAULT_CLIENT_THREAD_NUM 1);
// 创建并开启消费者线程
MultiThreadConsumerClient consumerClient = new MultiThreadConsumerClient(bufferQueue, clientBarrier);
for (int i=0; i < DEFAULT_CLIENT_THREAD_NUM; i ) {
threadPoolExecutor.execute(consumerClient);
}
}
@Override
public void invoke(String value, Context context) throws Exception {
// 往 bufferQueue 的队尾添加数据
bufferQueue.put(value);
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
LOG.info("snapshotState : 所有的 client 准备 flush !!!");
// barrier 开始等待
clientBarrier.await();
}
@Override
public void initializeState(FunctionInitializationContext functionInitializationContext) throws Exception {
}
} MultiThreadConsumerSink 实现了 CheckpointedFunction 接口,在 open 方法中增加了 CyclicBarrier 的初始化,CyclicBarrier 预期容量设置为 client 线程数加一,表示当 client 线程数加一个线程都执行了 await 操作时,所有的线程的 await 方法才会执行完成。这里为什么要加一呢?因为除了 client 线程外, snapshotState 方法中也需要执行过 await。
当 Checkpoint 时 snapshotState 方法中执行 clientBarrier.await(),等待所有的 client 线程将缓冲区数据消费完。snapshotState 方法执行过程中 invoke 方法不会被执行,即:Checkpoint 过程中数据缓冲队列不会增加数据,所以 client 线程很快就可以将缓冲队列中的数据消费完。
MultiThreadConsumerClient 具体代码如下所示:
public class MultiThreadConsumerClient implements Runnable {
private Logger LOG = LoggerFactory.getLogger(MultiThreadConsumerClient.class);
private LinkedBlockingQueue bufferQueue;
private CyclicBarrier barrier;
public MultiThreadConsumerClient(
LinkedBlockingQueue bufferQueue, CyclicBarrier barrier) {
this.bufferQueue = bufferQueue;
this.barrier = barrier;
}
@Override
public void run() {
String entity;
while (true){
try {
// 从 bufferQueue 的队首消费数据,并设置 timeout
entity = bufferQueue.poll(50, TimeUnit.MILLISECONDS);
// entity != null 表示 bufferQueue 有数据
if(entity != null){
// 执行 client 消费数据的逻辑
doSomething(entity);
} else {
// entity == null 表示 bufferQueue 中已经没有数据了,
// 且 barrier wait 大于 0 表示当前正在执行 Checkpoint,
// client 需要执行 flush,保证 Checkpoint 之前的数据都消费完成
if ( barrier.getNumberWaiting() > 0 ) {
LOG.info("MultiThreadConsumerClient 执行 flush, "
"当前 wait 的线程数:" barrier.getNumberWaiting());
flush();
barrier.await();
}
}
} catch (InterruptedException| BrokenBarrierException e) {
e.printStackTrace();
}
}
}
// client 消费数据的逻辑
private void doSomething(String entity) {
}
// client 执行 flush 操作,防止丢数据
private void flush() {
// client.flush();
}
} 从数据缓冲队列中 poll 数据时,增加了 timeout 时间为 50ms。如果从队列中拿到数据,则执行消费数据的逻辑,若拿不到数据说明数据缓冲队列中数据消费完了。此时需要判断是否有等待的 CyclicBarrier,如果有等待的 CyclicBarrier 说明此时正在执行 Checkpoint,所以 client 需要执行 flush 操作。flush 完成后,Client 线程执行 barrier.await() 操作。当所有的 Client 线程都执行到 await 时,所有的 barrier.await() 都会被执行完。此时 Sink 算子的 snapshotState 方法就会执行完。通过这种策略可以保证 Checkpoint 时将数据缓冲区中的数据消费完,client 执行 flush 操作可以保证 client 端不会缓存数据。
总结
分析到这里,我们设计的 Sink 终于可以保证不丢失数据了。对 CyclicBarrier 不了解的同学请 Google 或百度查询。再次强调这里多线程的方案,不仅限于请求第三方接口,对于非 CPU 密集型的任务都可以使用该方案来提高 CPU 利用率,且该方案不仅限于 Sink 算子,各种算子都适用,本文主要帮助大家理解 Flink 中使用多线程的优化及在 Flink 算子中使用多线程如何保证不丢数据。