图上的机器学习系列-聊聊LINE
前言
本篇继续GraphEmbedding旅途,来聊聊LINE这个方法,对应的paper为《LINE: Large-scale Information Network Embedding》。
---广告时间,欢迎关注本人公众号:

LINE的核心方法
首先,还是先来脑补一下LINE方法的思考过程: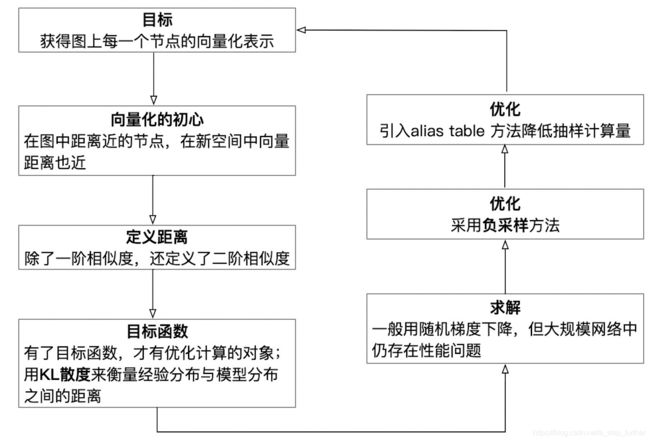
相似度&距离
在上一篇中,我们已经知道DeepWalk是采用类似于Word2Vec的方法,用一个节点的邻居序列来保存节点在网络中的拓扑结构,使得图中距离较近的节点在新的向量空间中也有较近的距离,但确实没有显示化地定义一个距离相似度的目标函数,也不是基于对目标函数的求解来得到向量表达的。LINE方法则明确定义一个量化的相似度计算公式,而且不仅包含一阶相似度,还包括了二阶相似度。
一阶相似度通常就是节点之间直接相连的边,可以用边的权重来度量。二阶相似度其实也容易理解,就是两个节点很可能没有边相连,但它们有很多共同的邻居节点,如下图所示:
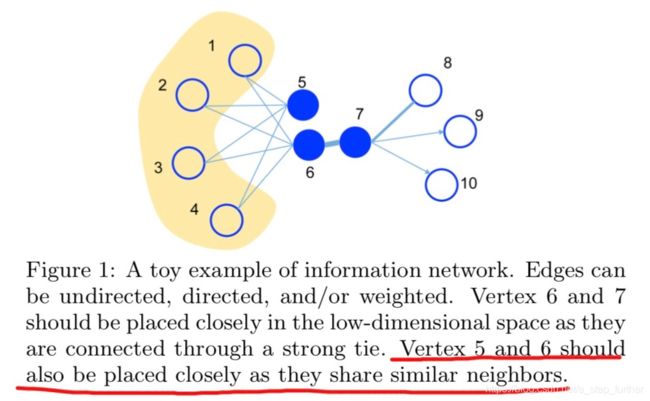
事实上,我们回想一下DeepWalk的方法,也可以捕捉到5,6两个节点的邻居相似性对吧?但因为DeepWalk本身没有引入节点之间边的权重,所以较难量化6,7之间的直接相似度大小。
具体地,LINE对一阶、二阶相似度的定义如下所示:


事实上,**这仍然是在图上的距离表示**,在新的向量空间中,作者并没有给出明确的距离公式,反而是用概率分布函数来论述的。一阶、二阶的概率密度函数分别如下:


但为什么是这样?不知道。网上也没有找到推导过程。甚至我猜想作者在思考的过程中是反过来的,即:
需要保留节点之间的相似度 -> 怎么衡量相似度呢?想到了KL散度方法来表达两个概率分布之间的相似度 -> 节点在图上的相似度用概率分布很好构造,但新的向量空间中的相似度怎么定义呢? -> 找一个随着向量距离大小递增的、介于0-1区间范围的函数吧 -> 哎呀,想到了sigmoid函数(一阶)、softmax函数(二阶)。
除了归因于灵光一现+打怪经验,我没有猜出来为啥会这样设计。
目标函数
有了分布的表达后,分别定义了一阶、二阶情况下的KL散度:


事实上,这些形式与交叉熵完全一致。所以也有很多人在刻画两个分布的差异性时直接用交叉熵,因为求极值的情况下,有一堆常数项是可以拿掉的。
优化方法
定义了上述的目标函数后,LINE还使用了一些降低计算量的优化技巧,而这样技巧同样是借鉴自文本处理领域。
对于二阶相似度的KL散度目标函数而言(公式如下),


这个与DeepWalk当中在神经网络的输出层面临softmax函数计算的问题何其相似啊。还记得吗,它使用了Hierarchical Softmax来降低计算量,然后文献\[4\]又找到了一种新的方法,称为NEG(在Noise Contrastive Estimation的基础上做了简化,做了Negative sampling),并定义了一个目标函数如下图所示:

LINE方法就是直接借用了这个想法,定义了如下所示的一个目标函数:
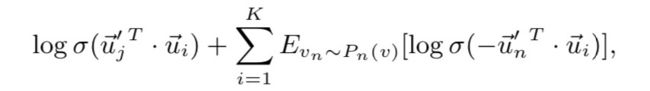
这个方法的本质是要将目标向量从一个噪声分布中识别出来。但是在优化该目标的过程中,又涉及到边采样的问题,又引入了一个alias table的概率抽样方法,这是一个很有趣的方法,具体原理可参考5、6两个附录的资料。
最终的向量化表示
事实上,LINE方法是分别求解了一阶、二阶相似度目标函数后,得到了两个向量化表示,然后进行了合并。

看github上LINE的代码,可以知道其实就是把两个向量串联拼接了起来:

个人感觉
其实LINE这个方法并不简洁,虽然对于图上节点之间的相似度定义还蛮直观的,但是接下来转化为优化问题求解的过程还是挺费解的,先转换为概率分布之间的距离,后续过程中又使用了较多的优化技巧,有一种慕容功夫博采众长的感觉,反倒不及DeepWalk那种一套降龙十八掌打下来的完整感和畅快感。
参考资料
1. [https://arxiv.org/abs/1503.03578]
2. [https://github.com/tangjianpku/LINE]
3. A. Q. Li, A. Ahmed, S. Ravi, and A. J. Smola. Reducing the sampling complexity of topic models. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 891–900. ACM, 2014.
4. T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems, pages 3111–3119, 2013.
5. [https://www.keithschwarz.com/darts-dice-coins/]
6. [https://www.wangliguang.cn/?p=9]