【考研笔记】计算机组成原理与思维导图(二)第二章 数值数据的表示
计算机组成原理与思维导图(二)
喜欢的话请给个关注或者点个赞再走吧,你们的支持是我创作的动力!
谢谢你们 祝大家早日上岸 点个收藏吧!后续会有考研真题更新哦!
第二章 数值数据的表示
一、数值数据的编码表示
1、基本概念
在计算机中,数据常用二进制来表示,也即为 “0” 和 ”1“,数据有 无符号数 和 带符号数 之分,其中 带符号数 根据编码的不同又分 原码 补码 和 反码 三种表示形式。
2、无符号数和带符号数
(一) 无符号数
无符号数:所谓无符号数就是一个数的 二进制 数据中都是数值位。相当于数的绝对值 。例如
![]()
无符号数直接存储
(二) 带符号数
带符号数:在计算机中,使用的大多都是带符号数,即一个数的数据中以最高位作为 符号位,以0代表正数,以1代表 负数,其它位作为 数值位 。带符号数的 数值部分 在计算机中常被称为 真值。例如

带符号数需要存储符号位
3、原码表示法
原码表示法 是一种最简单的机器数表示法,其最高位为符号位。符号位为0时,表明该数是 正数 ,符号位为1时,表明该数是 负数 。数值部分即为 真值相同。
(一) 真值为纯小数
当真值 纯小数 X 为正数【X】原 = X
当真值 纯小数 X 为负数时 【X】原 = 1-X
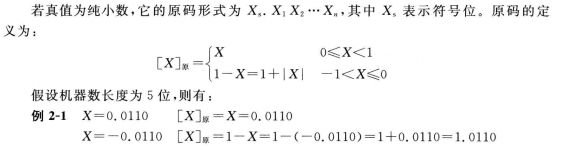
(二) 真值为纯整数
当真值 纯整数 X 为正数【X】原 = 符号位0 + X真值
当真值 纯整数 X 为负数时 【X】原 = 符号位1 +X真值
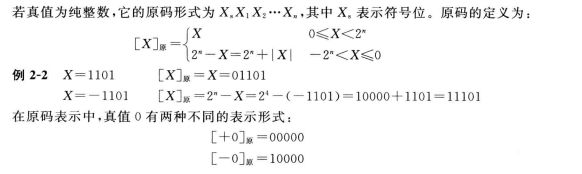
当机器数长度为5位时

4、反码表示法
(一) 真值为纯小数
当真值 纯小数 X 为正数【X】反 = X
当真值 纯小数 X 为负数时 【X】反 = 【X】原 最高位+ 【X】原 剩余数值位取反
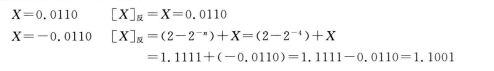
(二) 真值为纯整数
当真值 纯整数 X 为正数【X】反 =符号位0 + X真值
当真值 纯整数 X 为负数时 【X】反 = 【X】原 符号位+ 【X】原 剩余位取反

5、补码表示法
补码 = 反码末尾 + 1
如:真值 =-0.0011011
原码 = 1.0011011
反码 = 1.1100100
补码 = 1.1100101
总结:当数为正数是,原码 = 补码 = 反码。
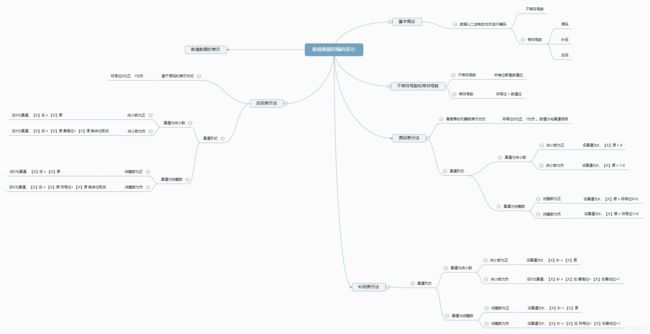
6、思维导图
如图
二、数值数据的格式表示
格式表示基于编码表示,形式表示有定点表示和浮点表示,原码即为二进制的定点表示。
计算机进行运算时,常需要指出小数点的位置,根据小数点的位置是否固定。在计算机内有两种数据格式,定点表示和 浮点表示。
1、定点表示法
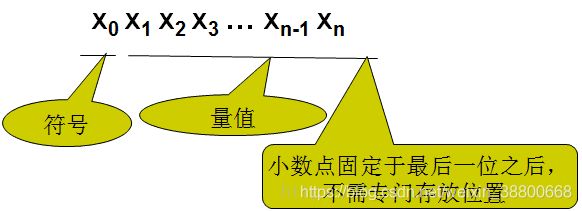
在定点表示法中约定,所有数据的小数点位置固定不变,通常,把小数固定在有效数位的前面或末尾,这就形成两类定点数。分别是 定点纯小数 和 定点纯整数。
(一) 定点纯小数
纯小数(小数点固定在量值最高位的左边,即符号位与量值之间)

(二) 定点纯整数
纯整数(小数点固定在量值最低位的右边)
2、浮点表示法
普及:最早的计算机只有两种表示方式:小数定点机和整数定点机。如果计算很大的数值时需要程序员手动调节小数点的位置。另一方面为了解决编程上的困难,就推出使用 浮点表示法 去表示数值。
概念: 小数点位置 随 阶码 不同而浮动。

指数 = 阶符 + 阶码
尾数 = 数符 + 尾数
(一) 阶码
阶码: 在机器中表示一个浮点数时需要给出指数,这个指数用整数形式表示,这个整数叫做 阶码 ,阶码指明了 小数点 在数据中的位置。在大多数计算机中,阶码为 纯整数,常用移码或 补码 表示。
(二) 阶符
**阶符:**阶符是当一个数用科学计数法表示时,它的 指数 的符号,指数是正还是负,正负号就是阶符。
(三) 数符
数符: 数符就是数字符号的简称。
(四) 尾数
尾数: 小数点后面的数字。在大多数计算机中,尾数为纯小数,常用原码或补码表示。
(五) IEEE754标准
IEEE754标准: IEEE754标准 (规定了浮点数的表示格式,运算规则等)
一: 基数 2是固定常数,故可不表示出来
二: 尾数 用 原码
三: 指数 用 移码(便于对阶和比较,不需要判断符号位)
四: 指数的 阶符 被隐含中移码中故可不表示出来,正因为如此,可以理解为 阶符隐藏,指数 = 阶码。 但又按照ieee754的标准,即指数 = 阶码 = 真值e + 偏移量。
五: 浮点数 的规格化表示: 当 尾数的值不为0 时,尾数域的最高有效位应为1(类似于0.011强制要求用1.1∗2−21.1∗2−2表示),又因为最高位固定为1,即尾数域表示的值是1.M,故最高位的1也不予存储.要除去E用全0和全1表示零和无穷大的情况,如本来是0-255则变成1~254。
PS:这里的 移码 = 阶码 + 偏移量
六: 单精度(32位)位浮点数

真值e为二进制浮点数的表示形式的指数。
七:双精度(64位)位浮点数

八: 表示范围


32位二进制转8位的十六进制使用8421法。同样地8位十六进制转32位二进制也是使用8421反推.

3、思维导图
如图
三、非数值数据的表示
1、基本概念
非数值数据,又称 字符数据 ,通常指 字符 、 字符串 、图形符号等数据。它们不用来表达 数值大小,一般情况下不进行 运算 .
2、字符和字符串的表示
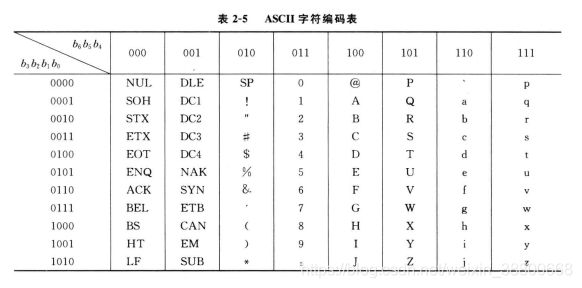
(一) ASCII字符编码
由于计算机只能识别和处理 二进制代码 ,所以字符必须按照一定的规则用二进制编码去表示。字符编码的方式有很多种,现在使用最广泛的就是 美国国家信息交换标准字符码(American Standard Code for Information Interchange),也就是ASCII。
常见的ASCII码用 7 位二进制表示一个字符,它包括10个十进制数字(0-9),26个英文字母的大小写。
对照如下表
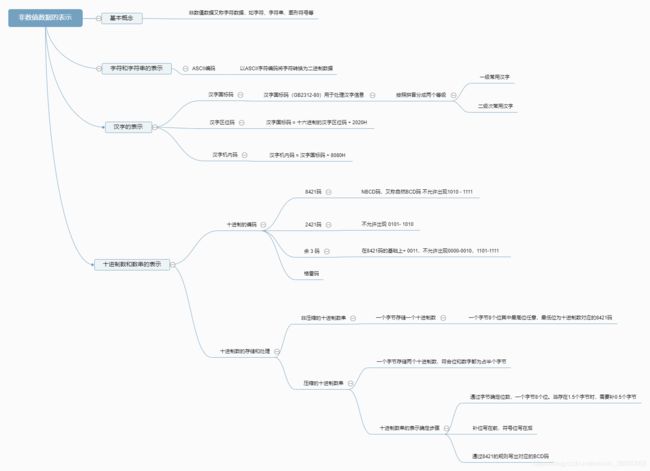
3、汉字的表示
(一) 汉字国标码
汉字国标码又称 汉字交换码 ,主要用于处理汉字信息系统或者通信系统之间交换信息用。最新的汉字国标码标准为 汉字国标码(GB2312-80),把汉字按照 拼音顺序 分成 一级常用汉字,二级 “ 次” 常用汉字 两个等级。
(二) 汉字区位码
汉字国标码 = 十六进制 汉字区位码 + 2020H

(三) 汉字机内码
汉字机内码 = 汉字国标码 + 8080H = 汉字区位码 +2020H +8080H
![]()
4、十进制数与数串的表示
(一) 十进制的编码
二进制是计算机最适合的数据表示方式,通常把 十进制数 转换为一组 二进制数 来表示。以4位二进制数表示1位十进制。
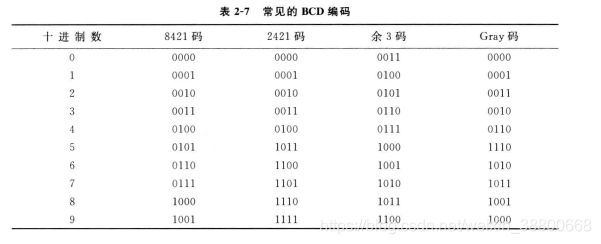
① 8421码

不允许出现1010 - 1111
② 2421码

同时也是 对 9 的自补码 ,如3的2421码是 0011,3对9的补数是6,而6的2421码即为3的取反。即为1100。
不允许出现0101 - 1010
③ 余 3 码

由于它的每个字符编码比相应的8421码多3,故称为余三码。
同时也是 对 9 的自补码
不允许 0000-0010,1101-1111
④ 格雷码( Gray 码)

(二) 十进制的存储和处理 - 数串
十进制数在计算机内是以 数串 的形式进行存储和处理的,十进制数串的长度是可变。
十进制在计算机内有两种表示形式,非压缩的十进制数 和 压缩的十进制数。
① 非压缩的十进制数串
非压缩十进制数据表示,一个字节可存放一位BCD码表示的十进制数,即一个字节存储一位十进制数。其中高4位可任意,低4位为相应十进制数字的BCD码。
如十进制数字 6 ASCII码为 0011 0110 非压缩十进制数为 0000 0110 只取低四位。最高4位可任意
② 压缩的十进制数串

一个字节存储两个十进制数, 其中+为C -为D 。
如+123 就需要两个字节才能存储,1和2需要一个字节,+和3需要一个字节。(符号位占半个字节)
所以按照8421的规则,+123按顺序符号位写在最后表示为
1 2 3 C 即为 0001 0010 0011 1100。
又如-2648,2、6为一个字节,4、8为一个字节,-为半个字节,所以需要补0凑多半个字节,共3个字节。
所以按照8421的规则,-2648按顺序符号位加补位写在最后表示为 0 2 6 4 8 D 即为 0000 0010 0110 0010 1000 1101
③ 总结
第一步:按照字节推出数串长度。
第二步 按照 8421码 的规则,写出每个十进制数的8421码。
第三步:按照符号位在后,补位在前的规则将数完整写出来。
5、思维导图
如图
四、数据校验码
1、基本概念
数据在传送和存取的过程中可能会发生错误,这时就需要使用 数据校验码 去修正错误了。也就是说 数据校验码 是指能够 发现 和 自动纠正 数据错误的 数据编码格式。
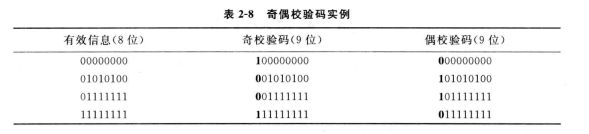
2、奇偶校验码
奇偶校验码是一种最简单的校验码,它的码距等于 2, 可以检测 一位 错误(或者 奇数位错误 )。
所谓码距,是指一个编码系统中任意两个合法编码之间至少有多少个二进制位不同。
缺点: 不能确定 错误的位置 和 判断 偶数位 的错误。
实现方法:

奇校验:在有效位的前提下 + 校验位(0或1),让校验码1的个数变为奇数。
偶校验:在有效位的前提下 + 校验位(0或1),让校验码1的个数变为偶数。
整个校验码 = 校验位 + 有效信息位

3、简单奇偶校验
简单奇偶校验只实现 横向 的奇偶校验
(一) 奇偶校验码的校验过程
奇偶校验码的编码和校验是通过特定的电路去实现的,常见的有 并行奇偶统计电路。 如图1
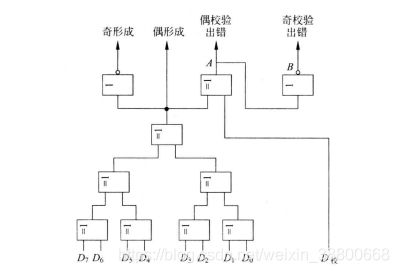
同时给出 奇形成、偶形成、偶校验出错、奇校验出错 的信号。如图2
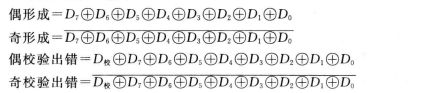
① 校验码的形成和存入主存步骤
当要把D7-D0写入主存时就需要把它们 同时 送入奇偶校验逻辑电路(图一),该电路产生的 “奇形成” 就是校验位,其后校验位 和 8位有效数值位一起 作为 奇校验码 写入到 主存 中。
若D7-D0有奇数个1,则奇形成为 “0”
若D7-D0有偶数个1,则奇形成为 “1”
② 校验检测
将校验码从主存中读出,将读出的9位数值又 同时 送入 奇偶校验逻辑电路 进行检测,若代码没有出错,则 “奇校验出错” 为 0,若代码出错,则“奇校验出错” 为 1。从而指出这9位数值有出错的地方,但不能检测到出错的位置。
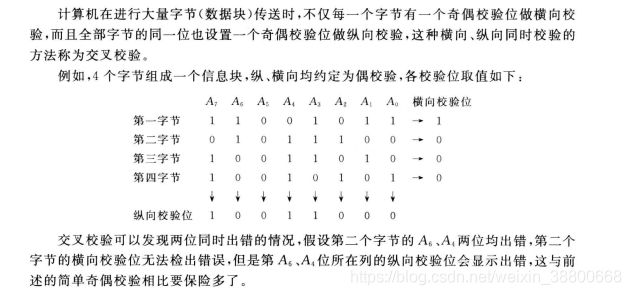
4、交叉奇偶检验
计算机在进行大量字节传送时,对每一个字节 设置 横向校验 和 纵向校验。这样不仅每一个字节(8个位)有 横向检验码 也有 纵向检验码 。
5、思维导图
如图
五、汉明校验码
1、基本概念
汉明校验码 也是一种 数据校验码,实际它上是一种 多重的奇偶校验码。它与奇偶检验码想比就是 它扩大自身的码距,使校验更加准确。通常 由 有效位 + 几位校验码 形成 汉明码 。
汉明码默认是 偶校验
汉明码只能检测2位错的错误
2、汉明码的构成
(一) 汉明码公式
2^k ≥ k + n + 1,其中n为有效位位数,K为校验码位数
汉明码的构成都是需要满足于公式方可构成。
(二) 构成步骤
汉明码 = 有效位 + 几位校验码
例如如下序列:
1100
我们想要让其变成海明码只需如下操作
① 基于公式求出K
由 2^k ≥ k+n+1,求出k = 3。即整段海明码长度为 4+3 = 7
②将序列按长度展开,并以2^k次幂从0开始去确定校验码位置
因为只有3位校验码,所以 2^k次幂也就展开3次
即为 2^0 = 1 ,2^1 = 2,2^2 = 4.。即为 1,2 ,4
算出的1,2,4位置即为校验码所在的位置
| H7 | H6 | H5 | H4 | H3 | H2 | H1 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 检验码3 | 0 | 检验码2 | 检验码1 |
③ 将校验码所在的“位置” 转换为3位 二进制数据
位置为 1,2,4
| 1 | 2 | 4 |
|---|---|---|
| 001 | 010 | 100 |
④ 将二进制数据作为通配表
将0变为*
| 1 | 2 | 4 |
|---|---|---|
| **1 | 1 | 1** |
⑤以通配表 匹配 海明码 各“位置”的序列,确定每位校验码所要检验的位置。
首先将 1-7的序列展开
| 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|
| 111 | 110 | 101 | 100 | 011 | 010 | 001 |
最后 我们将7->1依次与上面的通配表进行匹配
| 1 | 2 | 4 |
|---|---|---|
| **1 | 1 | 1** |
| 001(1) | 010(2) | 100(4) |
| 011(3) | 011(3) | 101(5) |
| 101(5) | 110(6) | 110(6) |
| 111(7) | 111(7) | 111(7) |
⑥确定要校验的位置,以偶校验的前提去确定校验码
由上述可知
在1位置的校验码 校验:1,3,5.7位有效位
在2位置的校验码 校验:2,3,6.7 位有效位
在4位置的校验码 校验:4,5,6.7 位有效位
以偶校验的前提可得:
H3,H5,H7 1的个数为奇数 因此H1=1
H3,H6,H7 1的个数为偶数 因此H2=0
H5,H6,H7 1的个数为偶数 因此H4=0
⑦得汉明码
| H7 | H6 | H5 | H4 | H3 | H2 | H1 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 1 |
3、思维导图
4、参考
参考:https://www.cnblogs.com/godoforange/p/12003676.html