卷积神经网络LeNet5,基于TensorFlow的实现
今天用一个小时,实现了LeNet5,一个经典的简单卷积神经网络,前面看西瓜书和《TensorFlow实践》也打下了一些基础。
神经网络的最基础的结构是这样的:
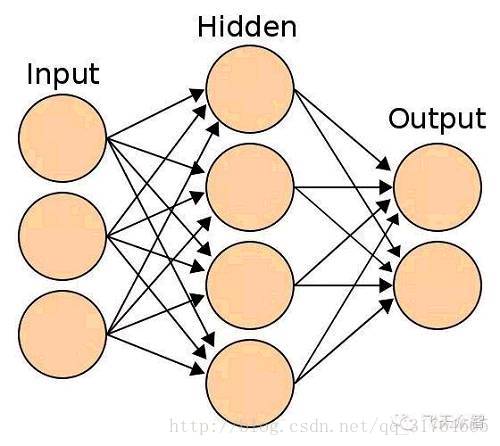
每条连线上都有一个权重,除Input层外,其他层每个结点都有一个偏置量,这些值是神经网络的关键,用来触发激活函数。通过激活函数最后在Output层输出结果。
卷积神经网络主要应用于计算机对图片的识别。目前最NB的卷积神经网络是微软研究院的ResNet V2,据说是由三个华人提出的。为国争光!!
基本的卷积神经网络结构是这样的:
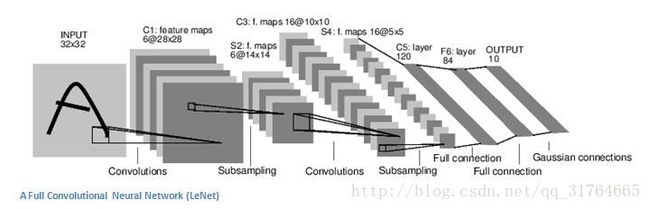 卷积神经网络并不直接输入图片整体,而是将一张图片分为若干小块来看,这样可以不受平移,旋转,亮度等的影响,而且这也是卷积神经网络的精髓所在。
卷积神经网络并不直接输入图片整体,而是将一张图片分为若干小块来看,这样可以不受平移,旋转,亮度等的影响,而且这也是卷积神经网络的精髓所在。
c1,c3是卷积层,s2,s4是池化层。卷积层看起来像一堆纸一样,其实是卷积核的个数,每个卷积核分别对输入的图片的一小部分提取一个特征,然后池化层将图片进一步变小,只留下特征明显的部分,如图,通过2次卷积,池化,再接入2个全连接层对图片进行辨认,得到结果。
下面附上我的代码,备注清晰,学习TensorFlow可以参考一下。
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
sess = tf.InteractiveSession()
'''
初始化权重函数
'''
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev= 0.1)
return tf.Variable(initial)
'''
初始化偏置函数
'''
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
'''
conv2d是2维卷积函数
x是输入
w是卷积参数[a.b.c.d],a,b是卷积核的大小,c是图片的channel,d是卷积核的数量
strides是卷积样板移动的步长
padding是边界处理方式
'''
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
'''
池化函数
ksize是池化前后的像素
strides是池化的步长,这是横竖方向设为2,若为1,则返回一个尺寸不变的图片
'''
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
x = tf.placeholder(tf.float32,[None,784])
y_ = tf.placeholder(tf.float32,[None,10])
#将输入1*784转为28*28的原始结构,-1代表样本数量不变,1代表样本channel数量
x_image = tf.reshape(x,[-1,28,28,1])
#卷积层conv1
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,w_conv1) + b_conv1)
#池化层pool1
h_pool1 = max_pool(h_conv1)
#卷积层conv2
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2) + b_conv2)
#池化层pool2
h_pool2 = max_pool(h_conv2)
#将pool2输入转为1D的向量,7*7是因为此时图片已经只有原来的1/4大小,即7*7
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
#连接一个全连接层
w_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1) + b_fc1)
#Dropout层防止过拟合
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
#输出层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,w_fc2) + b_fc2)
#loss fuction
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
#优化器
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.arg_max(y_conv,1),tf.arg_max(y_,1)) #得到正确的预测结果,返回布尔值
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
init = tf.global_variables_initializer()
init.run()
for i in range(2000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d,training accuracy %g"%(i,train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print(sess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob: 1.0}))