论文笔记D3S – A Discriminative Single Shot Segmentation Tracker
论文笔记D3S – A Discriminative Single Shot Segmentation Tracker
- 1. 论文标题及来源
- 2. 拟解决问题
- 3. 解决方法
- 3.1 算法流程
- 3.2 GIM
- 3.3 GEM
- 3.4 Refinement
- 3.5 bounding box fitting module
- 4. 实验结果
- 4.1 VOT2016
- 4.2 VOT2018
- 4.3 GOT-10k
- 4.4 TrackingNet
- 4.5 消融实验
- 4.6 DAVIS
- 5. 总结
1. 论文标题及来源
D3S – A Discriminative Single Shot Segmentation Tracker, CVPR, 2020
下载地址:https://arxiv.org/abs/1911.08862
2. 拟解决问题
a. SiamMask未将localization和segmentation联合在一起提升鲁棒性
b. SiamRPN中固定的目标不能适应动态变化的场景
3. 解决方法
3.1 算法流程
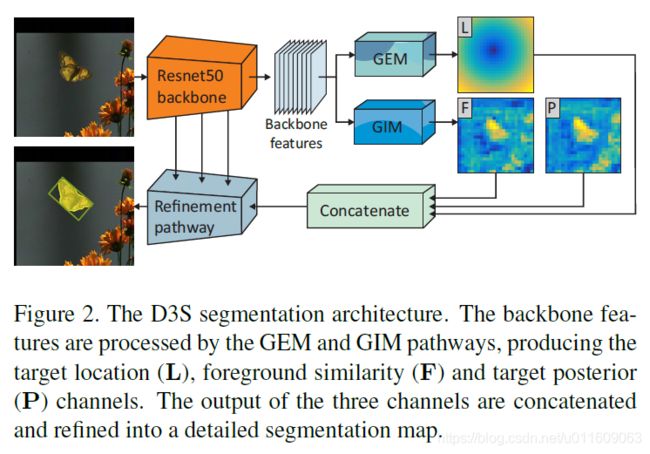
a. 将第一帧输入骨干网络提取特征
b. 将提取的特征分别输入GIM模块和GEM模块,通过GIM模块得到前景和背景信息,通过GEM模块得到定位信息
c. 将三者通过Concat融合,然后输入refinement得到第一帧mask和bounding box
d. 在跟踪时,使用骨干网络提取待跟踪帧搜索区域的特征
e. 将提取的特征输入GIM模块,通过与第一帧搜索区域比较得到像素级的前景相似度和背景相似度
f. 取每个像素相似度最高的前K个,然后分别求平均得到该帧的前景相似度和背景相似度
g. 重复c即可得到该帧的mask和bounding box
GIM模块GEM模块和refinement模块将在后续详细介绍
3.2 GIM
GIM表示geometrically invariant model(几何不变模型)。它的网络结构图如下

a.将骨干网络提取的特征输入该模块
b. 通过1x1和3x3卷积使特征适应该模块
c. 在第一帧target的每个像素上提取分割特征向量作为 X F X^F XF,在第一帧target附近的区域(搜索区域中非target部分)的每个像素上提取分割特征向量作为 X B X^B XB
d. 在跟踪时提取待跟踪帧search region的像素级特征,记为 X G I M X_{GIM} XGIM
e. 通过 X G I M X_{GIM} XGIM计算前景相似度和背景相似度
f. 取每个像素相似度最高的前K个,然后分别求平均得到该帧的前景相似度和背景相似度
该模块与VideoMatch: Matching based Video Object Segmentation中的软匹配层(见下图)思想非常相似,它的计算方式如下图所示(和原文不同的是,本文中的K取3)。

参考链接:https://blog.csdn.net/zxyhhjs2017/article/details/103458809
3.3 GEM
GEM表示geometrically constrained Euclidean model。它的网络结构如下所示。

a. 将骨干网络提取的特征通过1x1卷积降维
b. 将降维后的特征使用相关滤波思想得到响应图
c. 计算响应图中最大响应的位置到搜索区域中剩余像素的欧式距离,得到目标位置通道
此处的DCF模块借鉴Martin的ATOM。
3.4 Refinement
GEM模块能提供一个鲁棒但是不准确的目标估计,GIM模块能提供一个更多细节但是判别性更差的目标表示;此外,这些特征的分辨率很低,所以提出了refinement模块。
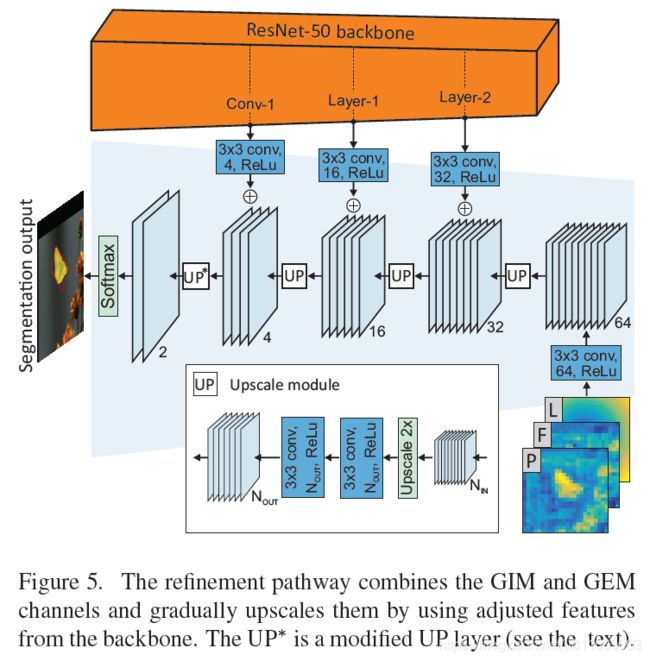
a. 将GIM和GEM模块输出的特征通过Concat融合
b. 使用3x3卷积固定其channel为64
c. 然后通过上采样模块提高分辨率,并与骨干网络中的特征通过相加得到融合特征
d. 重复c,最后通过Softmax得到mask
3.5 bounding box fitting module
使用椭圆代替矩形框。做法如下:
a. 只保留mask中最大连接部分
b. 通过最小二乘法将椭圆拟合到其轮廓上
c. 使用coordinate descent优化下列函数,从而得到精准的位置估计
I o U M O D = N I N + α N I N − + N I N + + N O U T + IoU^{MOD} = \frac{N^+_{IN}}{\alpha N^-_{IN} + N^+_{IN} + N^+_{OUT}} IoUMOD=αNIN−+NIN++NOUT+NIN+
其中N表示像素点数量,+前景,-表示背景,IN表示在矩形框内,OUT表示在矩形框外,例如 N I N + N^+_{IN} NIN+表示矩形框内属于前景像素点的数量, N O U T + N^+_{OUT} NOUT+表示矩形框外属于前景像素点的数量, N I N − N^-_{IN} NIN−表示矩形框内属于背景像素点的数量
该模块是一个trick,耗时2ms,但是收益较大
4. 实验结果
4.1 VOT2016

4.2 VOT2018

4.3 GOT-10k

4.4 TrackingNet

4.5 消融实验

椭圆fitting起关键作用(3.5节): 如果这套算法去掉最后的椭圆fitting的部分,仅仅采用旋转最小bounding box的形式,结果将下降4.5个百分点(0.489 vs 0.444),如果在分割结果上直接采用垂直bounding box,结果与采用旋转椭圆fitting框相比下降9.1个百分点(0.489 vs 0.398),可想而知,旋转椭圆fitting矩形框的效果是多么好了。
ATOM在线跟踪鲁棒性尤为关键:如果去掉ATOM定位分支,算法的Robustness将变得极差,EAO结果下降20几个百分点,可想而知,定位在整套算法中的地位。
4.6 DAVIS
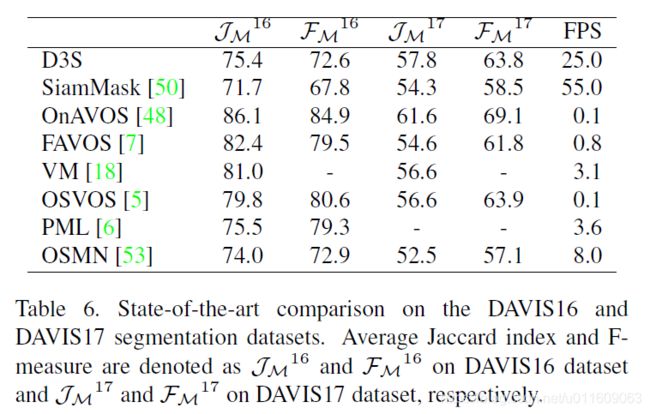
5. 总结
该算法将目标跟踪与实例分割相结合,利用骨干网络提取特征,然后通过GIM模块输出前景和背景信息,通过GEM模块输出大致的位置信息,然后将三者通过refine模块进行上采样,最终输出mask。VOT2016数据集的EAO, Accuracy, Robustness分别是0.493, 0.66, 0.131;VOT2018数据集的EAO, Accuracy, Robustness分别是0.48, 0.64, 0.15;GOT-10k的AO, S R 0.75 SR_{0.75} SR0.75, S R 0.5 SR_{0.5} SR0.5分别是59.7, 46.2, 67.6;TrackingNet的AUC, Prec, P r e c N Prec_N PrecN分别是72.8, 66.4, 76.8。该算法的性能非常好。