Pytorch菜鸟入门(3)——快速搭建/保存提取NN/批训练/各类optimizer【代码】
Pytorch菜鸟入门(3)——快速搭建/保存提取NN/批训练/各类optimizer【代码】
- 快速搭建NN
- 保存提取NN
- 批训练数据(Epoch,Batch,step含义)
- 5种优化器比较
- 可执行代码【all】
- 本系列文章为小白针对Morvan的课程中Pytorch学习过程中理解和记录,用于自己复习回顾,可参考。
快速搭建NN
原来搭建的神经网络是net1,
现在快速搭建和net1一样的net2

快速搭建,直接把隐藏层和预测层写进来,同时把RELU激励函数作为一层写进去。相当于第一层是输入1个特征,输出10个隐藏层神经元;第二层把激励函数RELU当作一层;第三层是net1种的prediction层,输入时10,输出时预测结果为1.
#效果和net1是一样的,运用了nn.Sequential
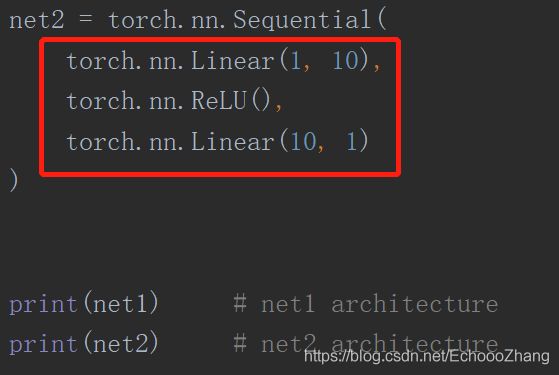
输出结果:上方为net1,下为net2

保存提取NN
这部分主要是需要了解,如何保存一个神经网络和调用它:
都有两种情况:
Save NN时:
(1)保存整个NN
torch.save(net1, 'net.pkl')
(2)理解为只保存该NN的参数parameters
torch.save(net1.state_dict(), 'net_params.pkl')
因此提取保存的NN时候也是两种情况:
(1)保存为整个NN时,提取也直接提取整个Net
net2 = torch.load('net.pkl')
(2)只保存该NN的parameters,提取前先构造一个和Net1一样的NN再把参数提取。
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
net3.load_state_dict(torch.load('net_params.pkl'))
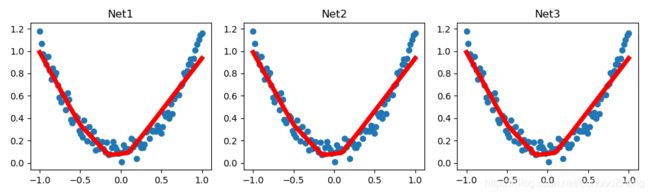
最后用同样数据训练三个网络,证明它们一模一样:
net1:原始 NN
net2:save entire NN then reload
net3:save only NN parameters then construct net3 (same as net1),
Then reload saved Parameters
批训练数据(Epoch,Batch,step含义)
首先必须需要:
import torch.utils.data as Data
给出假数据:
x是1到10 的十个数
y是10到1的十个数
x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
设置:
batch_size=5
意味着每次选择批处理十个数据中的5个[batch_size),可以理解为一共需要2步(step),即第一次处理5个,第2次处理5个。
【注】如果设置batch_size是8,则第一次处理8个,第2次处理2个。
epoch指的是处理所有数据的次数。
shuffle意思是每次批处理取数据时候是否随机取。
if shuffle is false则第一次取得是1,2,3,4,5,
第二次是6,7,8,9,10

torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # random shuffle for training
num_workers=2, # subprocesses for loading data
)
结果:
处理完所有数据才算一个epoch。

5种优化器比较
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式.
- 默认的 network 形式
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
- 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
- 优化器 Optimizer
接下来在创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差. 我们用几种常见的优化器, SGD, Momentum, RMSprop, Adam.
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss
训练/出图
接下来训练和 loss 画图:
# training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
注:
下面这句里,zip合并了三个list,在下面调用时,第一个net,opt,l_his,就分别是神经网络列表nets,优化器列表optimizers,和误差列表中对应的第一个值。
for net, opt, l_his in zip(nets, optimizers, losses_his):

SGD 是最普通的优化器, 也可以说没有加速效果,
Momentum 是 SGD 的改良版, 它加入了动量原则.
RMSprop 又是 Momentum 的升级版.
Adam又是 RMSprop 的升级版.
从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳.
我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器。
可执行代码【all】
#快速搭建/保存提取NN/批训练/各类optimizer
import torch
import torch.nn.functional as F
def build_nn_quickly():
# replace following class code with an easy sequential network
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
net1 = Net(1, 10, 1)
# 1.快速搭建,直接把隐藏层和预测层写进来,同时把RELU激励函数作为一层写进去。
# 效果和net1是一样的,运用了nn.Sequential
# easy and fast way to build your network
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
print(net1) # net1 architecture
print(net2) # net2 architecture
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# fake data
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
# The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors
# x, y = Variable(x, requires_grad=False), Variable(y, requires_grad=False)
def save():
# save net1
net1 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
optimizer = torch.optim.SGD(net1.parameters(), lr=0.1)
loss_func = torch.nn.MSELoss()
for t in range(200):
prediction = net1(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# plot result
plt.figure(1, figsize=(10, 3))
plt.subplot(131)
plt.title('Net1')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
# 2 ways to save the net
torch.save(net1, 'net.pkl') # save entire net
torch.save(net1.state_dict(), 'net_params.pkl') # save only the parameters
def restore_net():
# restore entire net1 to net2
net2 = torch.load('net.pkl')
prediction = net2(x)
# plot result
plt.subplot(132)
plt.title('Net2')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
def restore_params():
# restore only the parameters in net1 to net3
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
# copy net1's parameters into net3
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
# plot result
plt.subplot(133)
plt.title('Net3')
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.show()
#2.保存和提取
def save_reload():
# save net1
save()
# restore entire net (may slow)
restore_net()
# restore only the net parameters
restore_params()
#3.批处理
import torch.utils.data as Data
# torch.manual_seed(1) # reproducible
#
# BATCH_SIZE = 5
# # BATCH_SIZE = 8
#
# x = torch.linspace(1, 10, 10) # this is x data (torch tensor)
# y = torch.linspace(10, 1, 10) # this is y data (torch tensor)
#
# torch_dataset = Data.TensorDataset(x, y)
# loader = Data.DataLoader(
# dataset=torch_dataset, # torch TensorDataset format
# batch_size=BATCH_SIZE, # mini batch size
# shuffle=False, # random shuffle for training
# num_workers=2, # subprocesses for loading data
# )
#
#
# def show_batch():
# for epoch in range(3): # train entire dataset 3 times
# for step, (batch_x, batch_y) in enumerate(loader): # for each training step
# # train your data...
# print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
# batch_x.numpy(), '| batch y: ', batch_y.numpy())
#
#
# if __name__ == '__main__':
# show_batch()
#4.5种优化器比较
LR = 0.01
BATCH_SIZE = 32
EPOCH = 10
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
# put dateset into torch dataset
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
# default network
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
if __name__ == '__main__':
# different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss
# training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()