分库分表的产生背景
单一DB

如图所示,这是单一DB的应用架构,db中主要包括三种业务类型的表,分表是用户、订单、商品。
而对应业务操作基本都是在一个应用中完成的,这种架构适合项目周期短、业务简单
用户相对不多需求,因为用户量少压力就不是特别大,基本一个DB完全可以支撑
而随着公司的业务规模逐渐扩大,带来的效果就是用户量和业务的复杂度日益增加,
这时这种架构就会出现一系列问题,比如响应过慢,有时候甚至会出现超时。
而通过观察,首先出问题的地方,就是DB这块,以前数据量较少的时候,一个查询操作,会快速返回结果,而现在需要等好长时间,
而查询操作过慢也导致了后续其它的操作无法进行,因为数据库的连接数有限,而一个系统的操作基本都是读多写少的操作,
所以这时我们思考,能不能把数据库的读操作和其它操作分离开呢,所以就出现了我们读写分离的架构。
读写分离

读写分离的架构就是把我们系统中读操作和写操作分离开,通常写操作的节点叫做Master节点,读操作的节点叫做slave,或者叫做主节点和从节点,
其中从节点可以部署多个,来分摊读取数据的压力。
看似是一个完美的解决方案,但是也带来一些问题
读取数据的准确性
在以前的单一DB的架构中,因为读操作和写操作,都在一个节点不会出现此问题,而这种架构读取的数据是通过主节点同步到从节点,而同步是需要花费时间的,而这块时间也会受到一系列的因素影响,有时会变的
并没有那么快,比如网络抖动等。一般正常都是毫秒级的 ,所以如果对数据实时性要求比较高的,还是需要走主节点的。
多数据源的管理
单一的DB架构中,一个数据源就可以完全搞定,现在我们程序中需要配置多个数据源来进行操作数据,而且还要区分读操作和写操作,不过市场上也有一些开源的读写分离的中间件来解决此问题。
以上两个问题解决了,系统是完全可以支撑现有业务操作的,但是一个公司业务在飞速发展,数据量还在不断增大,到一定的时间我们就会遇到第三个问题
数据量持续增大
- 读节点不管增加多个,响应还是比较慢。
- 写操作也比较耗时,往往更新一条数据。
- DB的CPU使用率内存、CPU使用率持续增加。
这时候我们分析,我们DB中表主要由用户、订单、商品组成,能不能把这三快单独放在单独的DB中,这样我们DB的数据量就会下去。
同时我们发现这种切分的,应用层面也可以切分出来了,分为用户系统、订单系统、商品,因为以前所有的表都在一个DB中,系统层面也就没分,其实开发早希望分了,
因为随着业务复杂度变高
1. 应用本身代码量交大,依赖第三方包也越来越多,全量编译、打包部署时间会大大加长,如果功能出错,需要重新操作。
2. 由于业务快速发展,不同小组负责不同业务模块,但是又没有服务契约这种约定,公共的功能都是本地api的提供,因此会造成公共功能重复开发。
通过以上问题所以引申出了我们垂直切分架构。
垂直切分

把系统中表按照业务分类,放在单独DB中,也就把数据或者分摊到不同的DB中
如图所示数据库分为用户、订单、商品库,来分摊以前单一DB所面临的压力,同时在配置上读写分离的话,是可以支撑更多的请求访问的。
但是引入一个新的架构解决问题的同时,也会带来其它的一些问题,垂直切分所带来的问题
分布式事务的问题
多个系统进行调用的
以前在单一DB架构时,同一个事务中操作了用户和商品的表,现在不在同一个库中,并且应用系统现在也不在一起,所以需要拆分出来,以服务的方式进行调用,这种会带来分布式事务的问题。
多个库中表操作
假如应用系统没有拆分,只是数据库进行了拆分,以前同一个事务中操作的表现在在多个库中,这种也会产生分布式事务问题。
跨库join的问题
以前的连表查询的语句涉及的表,现在可能不在一个库中,那么需要进行拆分出来单独调用或者找有没有单独解决此类问题的中间件来解决。
以上问题在业务上规避或者通过程序改造完成了,看似是没什么问题了,就这样以这种架构运行了一段时间。
突然有一天产品投诉说,系统中一些操作很慢,比如商品查询,好友关系的查询,我们排查发现这几张表的数据已经有2千万了,此时无论是写入还是读取都是一个很耗时的操作。如果能把这些表的数据切分到不同库中,就可以解决此问题,所以就产生出了,水平切分这样一种架构。
水平切分
把表的某个字段用某种规则来分散到多个库之中,每个表中包含一部分数据。
简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切 分到其他的数据库中
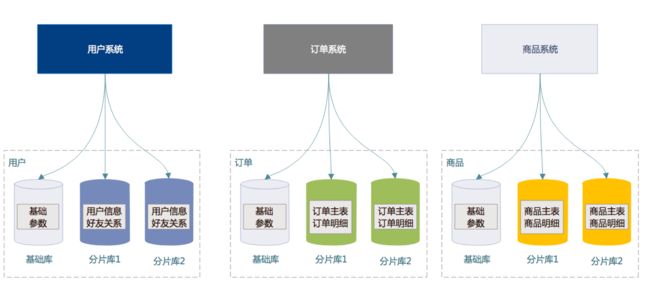
如图所示为水平切分的架构图,通过对原有用户、订单、商品库中部分表进行了切分,把压力分摊到多个库中。
其中以用户库为例,来说明水平切分大致的原则,首先对库中的表进行梳理,主要分为两大类:
基础参数的相关表
如业务参数、安全问题相关表,此类表的特点是数据量不是特别大,所以不需要水平切分。
用户相关表
此类表会随着时间的推进,表的数据会越来越大,所以需要针对这些表进行水平切分。
所以对用户库切分至3个库,分别分片库2个,基础库1个。
那水平切分有哪些问题呢,主要有以下几点:
多数据源的问题
此类问题在读写分离也会遇到,只是比以前更加复杂,以前的读写分离只需要
区分读和写操作。而水平切分更加复杂,水平切分根据表的分片规则进行计算,来决定去哪个库中操作,从而在判断操作的类型,在获取对应库中读数据源或者写数据源。
数据聚合的问题
以前查询一张表的操作,需要到单个数据源去获取就可以查询出所有的数据,水平切分后,需要到多个库中进行获取操作,然后聚合才能完成。复杂度越来越高了。
高并发下原子性的问题
以前用户的信息都在一张表中进行存储,多个用户进行注册时,输入相同的用户名,在进行数据保存时,数据库会进行唯一值判断,那么只有一个用户的数据能保存成功,这样就保证了数据的原子性。
水平切分后,多个用户注册的信息,可能不在一个库中,因为大多数切分的字段是用户ID,不同用户ID会存在在多个库中,那么就无法进行唯一值的判断 ,所有就会产生多条相同的用户名的数据。从而导致一系列问题。
如果解决以上问题,那么就可以安心使用水平切分这种架构了,但是逐渐还会遇到一些问题,如每个节点数据还会达到的瓶颈等,具体怎么做,后续章节会有介绍。