MDNet代码运行(一) Tracking
文章目录
- **先用代码所给的预训练模型跑一下(新增的mdnet_imagenet_vid.pth)**
- **先看导入的库文件,和从其他文件导入的方法**
- **然后看`main`函数**
- **Run tracker `run_mdnet()`**( 得到result,result_bb,fps)
- init bbox
- init mode
- Init criterion and optimizer
- Load first image
- Draw pos/neg samples
- EXtract pos/neg features
- Initial training
- Train bbox regressor(只用第一帧训练,使用1000个样本)
- Init sample generators for update
- Init pos/neg features for update
- Main loop(Tracking)
- 保存结果
- 可视化
代码链接: py-mdnet
**环境配置**: python3.6.6
torch 1.1.0
opencv 3.0+
下载此代码:git clone 链接
这部分用到的代码为:tracking下的所有和modules下的大部分
先用代码所给的预训练模型跑一下(新增的mdnet_imagenet_vid.pth)
python tracking/run_tracker.py -s DragonBaby [-d (display fig)] [-f (save fig)]
DragonBaby是OTB 中的一个序列,-d可以可视化结构,-s可以保存结果,方便后续写paper
下图是我跑的结果,可以看到有一行错误信息,虽然不影响,但是还是看着眼疼,错误如下:
QXcbConnection: XCB error: 145 (Unknown), sequence: 171, resource id: 0, major code: 139 (Unknown)
查了一下,是用MobaXterm运行程序时报上面的错,解决方法如下::
点击settings ->Configuration-> X11里 将 RANDR 里的勾去掉后点击OK,然后出现you must download the “CygUtils” plugin in order to use MobaXterm Bash local shell.这是让我下载"CygUtils"插件,我下载后重启MobaXterm,然后重新运行上述命令错误就没有了。参考
至于原理嘛,我不知道,如果有知道告诉我,谢谢。上传前图片很清晰,上传后就模糊了,凑合着看吧。打印出的参数如下:frame\overlap\score\time
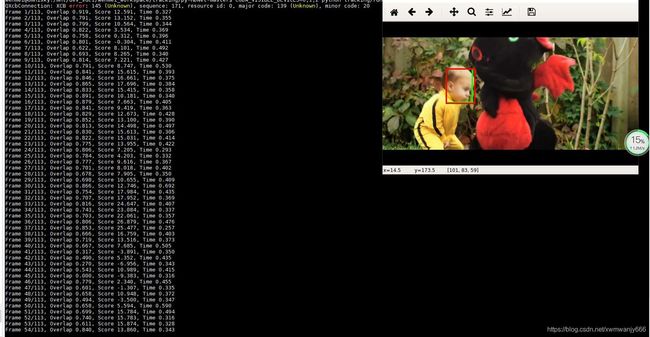

看完可视化的感受就是,想起Matrix最后一部在雨中经典快速的武打动作变成了慢动作,我还专门记了一下时间,113帧的DragonBaby用时01:23,而siamfc可视化113帧的感觉是一闪就没有了,用时00:10.
接着在pycharm看代码,遇到了找不到文件的问题:FileNotFoundError: [Errno 2] No such file or directory:
怪的要死,我在服务器可以运行,为什么到了pycharm就不能了,我各种project interpreter,sources Root,Excluded,把pycharm重启呀,把项目的路径添加呀,都不对,最后改了work directory到项目路径才对。吐血
先看导入的库文件,和从其他文件导入的方法
TOML、 JSON 、 YAML三种数据结构的表示方法(import yaml,json) 这是修改后的版本,以前的版本没有yaml,使用load函数读取options.yaml中的参数opts
然后看main函数
解析参数(运行的序列,是否可视化,是否保存图片)这里只给出一个视频序列,那对于OTB100个视频序列怎么跑呢?一个一个来太费时间了吧,有解决方案的请联系我,谢谢
生成视频序列配置文件(图片序列、真值、初始bbox、保存最后结果( 图片和json文件)的路径、)gen_config()函数
os.listdir() 返回指定路径下的文件和文件夹列表。os.path.join() 路径拼接。np.loadtxt(filename,delimiter=’,'默认是空格) 加载TXT文件,也就是真值。init_bbox=160,83,56,65
Run tracker run_mdnet()( 得到result,result_bb,fps)
init bbox
init mode
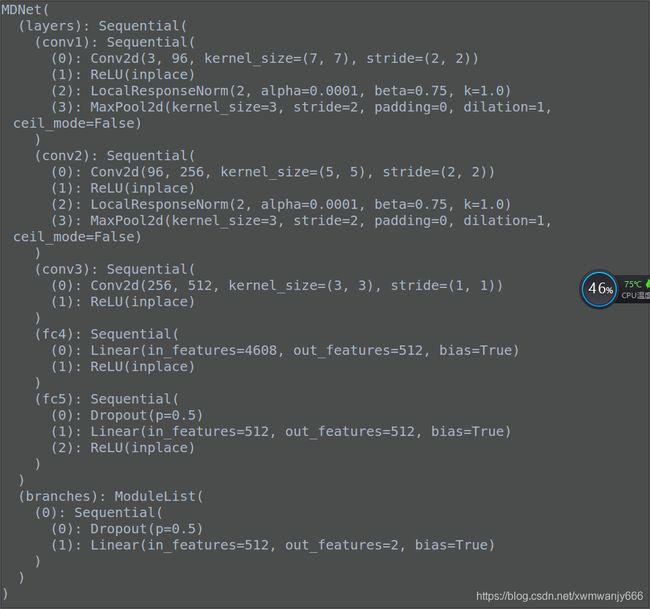
调用了modules/model.py MDNet() 此时K=1, Pytorch中nn.ModuleList和nn.Sequential的用法和区别 模型结构如图所示:
专门重新给nn.Linear层初始化, 通过**.modules()** 来找到nn.Linear,相当于给fc4、fc5 、fc6初始化
加载模型mdnet_imagenet_vid.pth,os.path.splitext(“文件路径”) 分离文件名与扩展名, 得到mdnet_imagenet_vid和.pth, load_model(),也就是load共享层(shared_layers)的参数(conv1.0.weight、conv1.0.bias,conv2.0.weight,conv2.0.bias,conv3.0.weight,conv3.0.bias,fc4.0.weight,fc4.0.bias,fc5.1.weight,fc5.1.bias),加载模型时一般用model.load_state_dict(torch.load(model_path)) ,model.load_state_dict() 函数接受的参数是一个字典对象, 而不是模型文件的保存路径
然后把这些参数append到对应的层 build_param_dict() .named_children() (conv1->name conv2d relu…->module),append_params() module.children() child._parameters.items()(weight,params),
最后得到conv1_weight,cov1_bias,conv2_weight,cov2_bias,conv3_weight,cov3_bias,fc4_weight,fc4_bias,fc5_weight,fc5_bias,
fc6_0_weight,fc6_0_bias各自对应的params,前五层加载预训练模型的,fc6加载网络自己初始化的 .model.cuda()
Init criterion and optimizer
criterion:BCELoss二分类交叉熵,设置fc层需要学习(required_grad=True) set_learnable_params()
optimizer: set_optimizer() set_learnable_params() set_optimizer() init_optimizer fc4、fc5 lr=0.0005,fc6 lr=0.005 ,momentum=0.9,w_decay=0.0005 用optim.SGD来更新些参数
update_optimizer set_optimizer() lr 由0.0005改为0.001、0.01
设置学习率初始化和后来的更新很重要
**计时:**tic = time.time()
Load first image
image=Image.open(img_list[0]).convert('RGB')
size=
Draw pos/neg samples
按照gaussian\uniform\whole\这些方式,以初始bbox(转化为中心坐标188,115.5,56,65)进行样本的取样,并进行bbox 的调整,然后再算(min_x,min_y,w,h),500个正样本,5000个负样本。

SampleGenerator() 调用modules/sample_generator.py 进行__init __初始化,再使用__call__方法,_gen_samples()方法,np.tile()(例如np.tile(b, (2, 1))#沿X轴复制1倍(相当于没有复制),再沿Y轴复制2倍) None其实就是增加了维度
np.clip(a, a_min, a_max, out=None) 限制一个array的上下界给定一个范围[min, max]
提取样本后,接着算其IOU, 以判断是正样本还是负样本 overlap_ratio() 参考代码
overlap_pos_init: [0.7, 1]
overlap_neg_init: [0, 0.5]
EXtract pos/neg features
forward_samples() 方法,输入参数为(model,image,pos_examples),model.eval(),输出 conv3特征
调用了data_prov.py中的RegionExtractor()方法 ,extract_regions() 根据samples提取样本区域,crop_image2()裁剪方法【以前版本不是这样的,这是重新修改的】
根据上面提取的正负样本的bbox,从原图中进行裁剪并scale为107x107大小,padding=16, 提取batch_size=256个,进行了数据增强,没有使用flip matrix,rotation matrix,只使用了Translation matrix,Scaling matrix,revert_t_matrix,将这三个矩阵合并在一起,作为cv2.warpPerspective(img,matrix,(im_size,img_size),borderValue=128)透视变换的变换矩阵,变化的图片如图所示:
这是原图:

regions = regions.astype('float32') - 128这句话是数据0中心处理,没有可视化,我不清楚最后是什么样子的?
with torch.no_grad()代替volatile,表示不需要求导
做完这些准备工作,终于可以提取特征了,调用model(regions,out_layer='conv3') regions(256,3,107,107),自然是用forward()函数来处理,in_layer=‘conv1’,out_layer=‘conv3’,x=module(x) 256,3,107,107->256,96,25,25->256,256,5,5->256,512,3,3->view为(256,4608),未输入到fc4 层做准备;另一批为(244,3,107,107),然后cat, 得到torch.Size([500, 4608])
eat.detach().clone())截断反向传播的梯度流,并进行复制
5000个负样本处理方法同上
Initial training
train(model,criterion,init_optimizer,pos_feats,neg_feats,50)以前版本训练30次,现在要训练50次
model.train(),in_layer=‘fc4’
pos_idx ,先打乱顺序,np.random.permutation(),然后进行扩充,500->
hard negative mining
model.eval(),算出score=model(batch_neg_feats,in_layer=fc4),out_layer=fc6,调用forward()函数,(256,4608)->(256,512)->(256,512)->(256,2)
最后得到1024个负样本的得分,score.detach()[:, 1].clone(),从中挑选96个分数最高的,
_, top_idx = neg_cand_score.topk(batch_neg) 分别得到分数,和对应的索引。再从对应的索引中获取相应的特征,最后设置model.train()
forward( 算得分)
pos_score = model(batch_pos_feats, in_layer=in_layer) batch_pos_feats( torch.Size([32, 4608]))
neg_score = model(batch_neg_feats, in_layer=in_layer) batch_neg_feats( torch.Size([96, 4608]))
optimize
BCELoss() 输入pos_score,neg_score
model.zero_grad() #将参数的梯度归零
loss.backward()
梯度裁剪 (nn.utils.clip_grad_norm(parameters, max_norm, norm_type=2)),max_norm=10最大梯度范数/ 范数类型,norm_type=2
optimizer.step()进行模型的更新(只更新fc层的)
del init_optimizer, neg_feats
torch.cuda.empty_cache() #释放不再需要的缓存
Train bbox regressor(只用第一帧训练,使用1000个样本)
参考 Draw pos/neg samples overlap_bbreg: [0.6, 1]
得到1000个样本后,从原图剪取相应的exaples并resize107x107, 提取特征,out_layer=‘conv3’,torch.Size([1000, 4608])
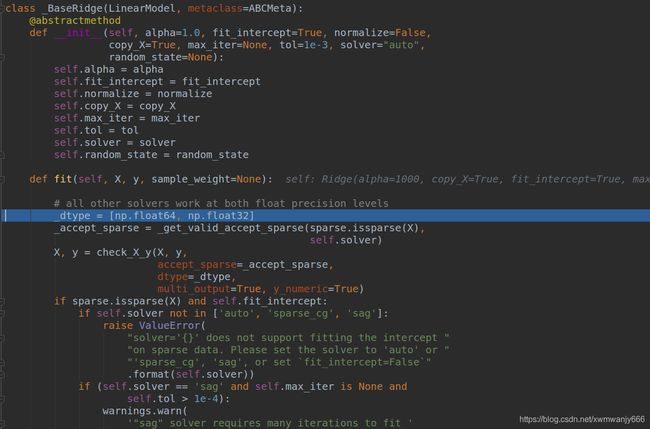
bbreg=BBRegressor(image.size) #进行初始化(bbreg.py 的init方法)self.model=Ridge(alpha=1000)
bbreg.train(bbreg_feats,bbreg_examples,target_bbox) # 参数分别为 输出的conv3的特征,1000个bbox,和
gt bbox
bbreg.py/BBRegressor() self.model = Ridge(alpha=self.alpha) 初始化
bbreg.train(bbreg_feats, bbreg_examples, target_bbox), 算1000个样本和给定的bbox 的IOU,然后挑选出572个正样本,根据ID找出对应的样本和特征, get_examples(bbox,gt) 基于中心坐标,参考 boundingbox regresson 进行微调, 得到最后的Y,这里的Y 代表已预测的bbox与真值的误差。
接着用岭回归的方法:self.model.fit(X, Y) X:正样本特征 (561,4608) Y:微调bbox 的变量dx,dy,dw,dh.,也就是给定正确的调整方案,让网络去学习拟合
del bbreg_feats, torch.cuda.empty_cache()
之后的每一帧都可以用.predict()函数进行预测,输入的两个参数分别是特征和bbox,return self._decision_function(X),如下:
def _decision_function(self, X):
check_is_fitted(self)
X = check_array(X, accept_sparse=['csr', 'csc', 'coo'])
return safe_sparse_dot(X, self.coef_.T,
dense_output=True) + self.intercept_
得到最后的dx,dy,dw,dh,然后利用此对原来的bbox进行调整,公式RCNN上都有。
bbox_[:,:2] = bbox_[:,:2] + bbox_[:,2:]/2
bbox_[:,:2] = Y[:,:2] * bbox_[:,2:] + bbox_[:,:2]
bbox_[:,2:] = np.exp(Y[:,2:]) * bbox_[:,2:]
bbox_[:,:2] = bbox_[:,:2] - bbox_[:,2:]/2
Init sample generators for update
SampleGenerator() sample_generator / pos_generator/ neg_generator
Init pos/neg features for update
因为之前把neg_featss删了,所以还得重新选择负样本,然后提取特征。总共200负样本。500正样本
Main loop(Tracking)
准备的步骤就为这里服务了,从第二帧开始跟踪
计时: spf_total = time.time() - tic
加载图片:image=Image.open(img_lsit[1]).convert(‘RGB’)
估计target bbox: 从每张图片选取256个样本,再算分数 forward_samples() ->model(),out_layer=fc6,选取正样本分数最高的5个和对应的索引,再根据索引找到对应的样本,求5个的均值 得到target_bbox (166.37703,82.724915,55.56529,64.49544)
并定义是否成功。由最高五个分数求平均,大于0就成功
当跟踪失败时扩大搜索区域:成功trans 不变0.6,失败 trans改为1.5
Bbox regression:
成功时:提取分数最高的5个样本的特征,得到bbreg_feats,out_layer=conv3,bbreg.predict(bbreg_feats, bbreg_samples)
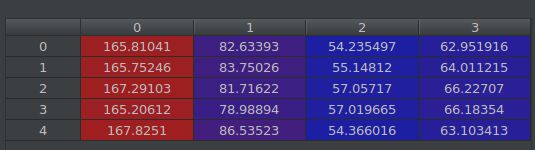

求均值 bbreg_bbox: [168.13992 86.30281 53.29604 62.781055]
失败时:bbreg_bbox = target_bbox
保存结果: result[i] = target_bbox result_bb[i] = bbreg_bbox
数据收集:(成功时才收集)
正样本:以target_box,overlap_pos_update: [0.7, 1]来采50个正样本。提取特征。conv3, 把这些特征添加到前面的正样本特征中,为:torch.Size([500, 4608]),torch.Size([50, 4608]),len=2,组成两组特征,当>100时删除第一个特征。
负样本:以target_box,overlap_neg_update: [0, 0.3]来采200个负样本。提取特征。conv3, 把这些特征添加到前面的负样本特征中,为:torch.Size([200, 4608]),torch.Size([200, 4608]),len=2,组成两组特征,当**>30时删除第一个特征**。
短时更新(不成功):
从以上收集的数据特征,正样本选一些然后cat,负样本全部 cat,再重新训练模型,训练15次
train(model, criterion, update_optimizer, pos_data, neg_data, opts['maxiter_update'])
注:这里使用的是update_optimizer
长序更新(间隔10次迭代):
从以上收集的数据特征,正样本全部 cat, 负样本全部 cat,再重新训练模型,训练15次
train(model, criterion, update_optimizer, pos_data, neg_data, opts['maxiter_update'])
注:这里使用的是update_optimizer
计时:spf = time.time() - tic spf_total += spf
最后输出最开始的那张图,print(‘Frame {:d}/{:d}, Overlap {:.3f}, Score {:.3f}, Time {:.3f}’.format(i, len(img_list), overlap[i], target_score, spf))
第二张图预测完毕,接着把整个序列都预测后,算meanIOU,fps,return result, result_bb, fps
保存结果
res:result_bb.round().tolist(),将数据四舍五入,然后转为list
type: rect
fps:fps
json.dump(res,open(result_path,'w'),indent=2),用于将dict类型的数据转成str,并写入到json文件中。
可视化
参考
gt_rect = plt.Rectangle(tuple(gt[0, :2]), gt[0, 2], gt[0, 3],linewidth=3, edgecolor="#00ff00", zorder=1, fill=False)
ax.add_patch(gt_rect)
最后,参照fc改了一下,不是一个序列一个序列跑,可以把整个OTB跑完,但是真的慢
生成的是json文件,最后转为txt 文件,用bechMark测评。
慢在哪里呢?每一个裁剪的样本都从头开始提取特征,而不是整个图提取特征再裁剪,另外在线训练bbox regressor和fc层