二叉树查找树与平衡二叉树原理剖析与实现
文章目录
- 1、什么是二叉树(Binary Tree)
- 2、二叉树的存储方式
- 3、二叉树的遍历
- 4、二叉查找树(Binary Search Tree)
- 4.1 查找操作
- 4.2 插入操作
- 4.3 删除操作
- 5、平衡二叉树(AVL Tree)
1、什么是二叉树(Binary Tree)
二叉树是一种特殊的树,之前我们所讲的数据结构都是线性结构,今天说的二叉树就是一种非线性结构的数据结构。它是具有如下特点的树:其一,每个结点最多只有两棵子树(也就是二叉树中不存在结点的度大于2的结点);其二,二叉树的子树具有左右之分,而且顺序不能颠倒。这里我不会对树的概念以及二叉树的概念做太多的赘述,如果不了解请您可以先查查关于更多树和二叉树的定义和性质。
二叉树具有以下性质:(1)在二叉树的第 i 层上最多有2^(i - 1)个结点;(2)深度为 k 的二叉树最多有(2 ^ k) -1 个结点;(3)对任何一棵二叉树,如果其叶子结点数为n0,度为2的结点数为n2,则n0 = n2 + 1;
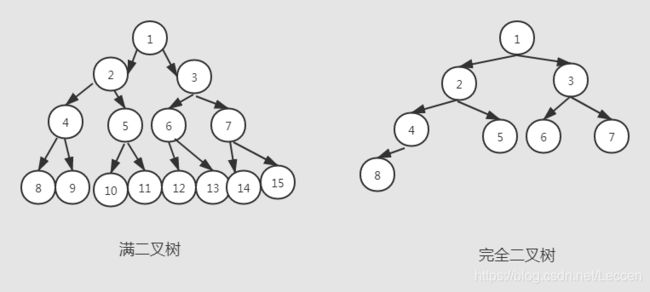
这里我们看看满二叉树的概念,一棵深度为k且有(2 ^ k) -1个结点的二叉树为满二叉树。 如果我们约定给满二叉树从上到下,从左到右依次编号,那么当且仅当深度为k的二叉树的所有结点都能与满二叉树的编号一一对应,我们说这棵二叉树是完全二叉树。
2、二叉树的存储方式
二叉树的存储方式有两种,一种是顺序存储方式,一种是链式存储方式。所谓顺序存储方式就是用连续地址的内存来存储二叉树也就是数组。
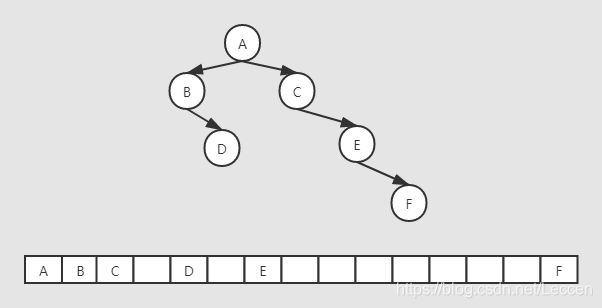
基于数组的存储方式,对于完全二叉树比较友好,但是对于非完全二叉树而言就比较浪费内存空间。我们记根结点的数组索引下标为 i ,因此,其左子树根结点下标就为2 * i,右子树根结点的下标索引为 2 * i + 1,依次类推,当遇到某个结点的子树为空时,这个结点对应的索引的数组就为空。因此当二叉树为非完全二叉树会造成数组过于稀疏,从而浪费存储空间,例如
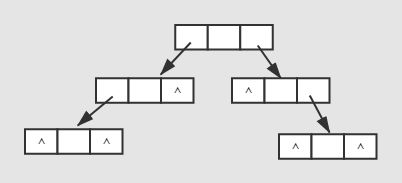
对于非完全二叉树我们一般采用链式存储方式,链式存储方式就是使用链表的方式将二叉树中的结点连接起来。每个结点有两个指针域,分别指向左子树和右子树。
3、二叉树的遍历
我们从定义可以看出其实二叉树是一种递归定义的结构,因此我们在遍历的时候也可以递归进行。一般来讲二叉树的遍历有三种方式:前序遍历,中序遍历,后序遍历
(1)前序遍历:先访问根结点,前序遍历左子树,前序遍历右子树;
(2)中序遍历:中序遍历左子树,访问根结点,中序遍历右子树;
(3)后序遍历:后序遍历左子树,后序遍历右子树,访问跟结点;
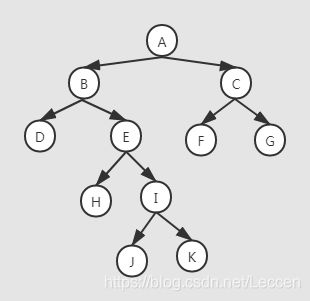
如图所示的二叉树:
其先序遍历结果为:A,B,D,E,H,I,J,K,C,F,G
其中序遍历的结果为:D,B,H,E,J,I,K,A,F,C,G
其后序遍历结果为:D,H,J,K,I,E,B,F,G,C,A
对于二叉树的遍历主要就是理解它的递归过程,通过写递归公式,这样就很简单地写出代码,其遍历的时间复杂度为O(n):
// 三种遍历方式的代码
void preOrder(Node* root) {
if (root == null) return;
visit(root); // 访问结点
preOrder(root->left);
preOrder(root->right);
}
void inOrder(Node* root) {
if (root == null) return;
inOrder(root->left);
visit(root);
inOrder(root->right);
}
void postOrder(Node* root) {
if (root == null) return;
postOrder(root->left);
postOrder(root->right);
visit(root);
}
4、二叉查找树(Binary Search Tree)
二叉查找树又称为二叉排序树,它的定义如下:二叉查找树是一棵空树或者是具有如下性质的二叉树:(1)若它的左子树不为空,则左子树上所有结点的值均小于根结点;(2)若它的右子树不为空,则它的右子树的所有结点均大于根结点;(3)它的左子树和右子树也分别为二叉查找树
-
4.1 查找操作
根据二叉查找树的定义,现在我们给定一个数据对象的关键字key,现在我们根据关键字key先与根结点比较,假如等于则直接找到返回,如果给定关键字key小于根结点则从左子树递归查找,如果Key大于根结点则从右子树递归查找。因此我们看见实际上,这很像二分查找算法。例如我们在下图的二叉树中查找结点为 42的结点,其过程为下图中的红色箭头:
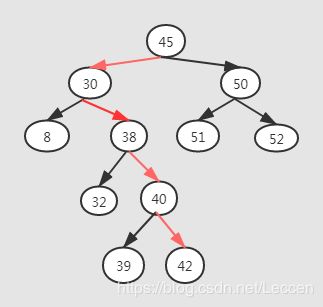
那么二叉查找树的查找性能如何呢?我们从图中可以看到,查找的次数取决于二叉树的深度,因此查找性能与二叉树的形态密切相关,这里我们为了简单分析,假设这棵二叉树是结点为 n 的完全二叉树,我们怎么计算它的深度呢?我这里直接给出结论,就不证明了,你可以根据二叉树的性质自己推算很简单。deep = log2n向下取整 +1。因此查找的时间复杂度为O(logn)。
假如我们要插入的数据是一个与二叉树中某个结点重复的怎么办呢?其中一个解决办法是,把这个结点当作比二叉树中重复的结点大的结点,然后将其插入右子树。
-
4.2 插入操作
二叉查找树的插入过程有点类似查找操作。新插入的数据一般都是在叶子节点上,所以我们只需要从根节点开始,依次比较要插入的数据和节点的大小关系。如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位置;如果不为空,就再递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点数值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;如果不为空,就再递归遍历左子树,查找插入位置。插入操作我就不给图示了。
-
4.3 删除操作
相比于查找和插入操作,删除操作会稍微麻烦一些,需要分为三种情况来讨论:
(1)如果需要删除的结点是叶子结点,则我们直接将其删除即可,然后修改父节点的指针
(2)如果待删除的结点至少包含一个子树,则只需要修改待删除结点的父节点让父节点的指针指向待删除结点的子树即可
(3)如果待删除的结点包含两棵子树就比较麻烦,我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。例如删除下图所示的38的结点:
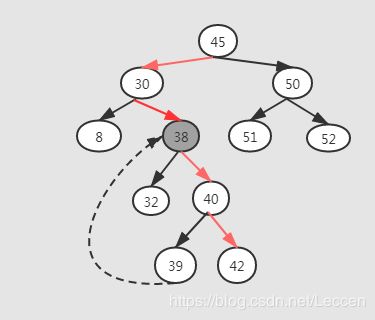
我们根据二叉查找树的特点,很容易就能得到有序序列,只需要中序遍历这棵树就可以了。
5、平衡二叉树(AVL Tree)
之前我们分析了二叉查找树的性能,时间复杂度,请试想一下这种情况。假如我们的二叉查找树是一棵单支树,也就是不存在度为2的结点,此时二叉树就退化成了链表,因此时间复杂度退化为O(n)。因此,我们要避免在插入和删除操作中出现的让二叉查找树性能下降的情况,也就是说我们要动态维护这棵二叉树。这就是平衡二叉树,它的定义是这样的:它或者是一棵空树或者是具有以下性质的二叉树:它的左子树和右子树都是平衡二叉树,并且左子树和右子树的深度之差的绝对值不超过 1。如果将左右子树的深度差定义为平衡因子,那么平衡因子的值就只可能为0,-1, 1。
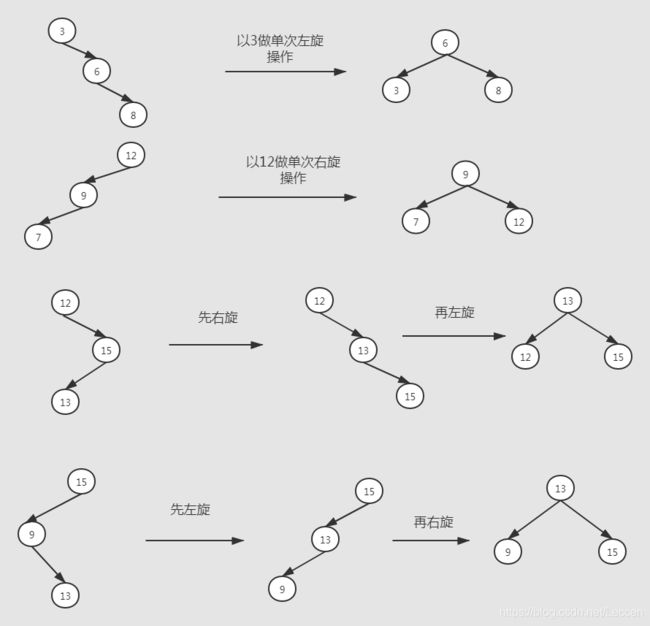
当我们在建立一棵二叉树的时候,或者在插入的时候,就会判断插入操作是否会让这棵二叉树失去平衡,如果失去平衡我们就要动态调整,让它恢复平衡。怎么让它恢复平衡呢?一般我们是采取旋转操作。怎么旋转呢?我们假设由于在二叉查找树上插入结点而失去平衡的最小子树根结点的指针为a(也就是说a是离插入结点最近,且平衡因子绝对值超过1的祖先结点)调整规律一般有4种:
(1)单向右旋平衡处理: 由于在 * a 的左子树根结点的左子树上插入结点,* a的平衡因子由1变为2,则需要进行一次向右的顺时针旋转操作;
(2)单向左旋平衡处理: 由于在* a的右子树根结点的右子树上插入结点,* a的平衡因子由-1 变为-2,则需要进行一次向左的逆时针旋转操作;
(3)双向旋转(先左后右)平衡处理: 由于在* a的左子树根结点的右子树插入结点,* a的平衡因子由1变为2,则需要进行两次旋转操作(先左旋后右旋);
(4)双向旋转(先右后左)平衡处理: 由于在* a的右子树根结点的左子树插入结点,* a的平衡因子由-1变为-2,则需要进行两次旋转操作(先右旋后左旋);
我们来看看对应的图示,这样帮助理解
由于AVL树的左右子树高度差是严格的小于等于1,因此它是非常严格的平衡二叉树,由于它需要保持非常严格的条件,因此再插入或者删除操作中,一旦发现二叉树不平衡了,就需要维护这棵树的平衡。但是维护二叉树的平衡就需要额外的操作,额外的操作就势必会带来额外的开销,当插入和删除操作太过频繁的时候,就会触发维护操作。但实际上我们之所以要让一棵二叉树保持平衡是为了让它的查找性能不至于急速退化,因此假如说我们对一棵二叉树的平衡并不要求它能够一定满足log2n的高度,但是接近这个高度,那么实际上查找性能也不会太差。
我们在实际的开发中,如果有一种结构能够解决我们在频繁地插入和删除操作中带来的查找性能下降的问题并且还不至于过于频繁地取维护这棵二叉树的严格平衡,这样的结构是实际我们所喜欢的。如果我们现在设计一个新的平衡二叉查找树,只要树的高度不比 log2n 大很多(比如树的高度仍然是对数量级的),尽管它不符合我们前面讲的严格的平衡二叉查找树的定义,但我们仍然可以说,这是一个合格的平衡二叉查找树。
实际上,在工程应用中,更喜欢用红黑树而不是AVL树,为什么呢?AVL树我们刚才说过为了维护它的平衡它需要付出额外的开销代价,红黑树只是做到了近似平衡,并不是严格的平衡,所以在维护平衡的成本上,要比 AVL 树要低。所以,红黑树的插入、删除、查找各种操作性能都比较稳定。对于工程应用来说,要面对各种异常情况,为了支撑这种工业级的应用,我们更倾向于这种性能稳定的平衡二叉查找树。关于红黑树,大家有兴趣可以自己去了解了解,这里我就不说了。
我们也给出常规二叉查找树的代码实现:
public class BinarySearchTree {
private Node tree;
// Node类
public static class Node {
private int data; // 数据域
private Node left; // 左子树的指针
private Node right; // 右子树的指针
public Node(int data) {
this.data = data;
}
}
// 查找操作
public Node find(int data) {
Node p = tree;
while (p != null) {
// 小于该结点的值则在左子树寻找
if (data < p.data) p = p.left;
// 大于该结点的值则在右子树寻找
else if (data > p.data) p = p.right;
else return p;
}
return null;
}
// 插入操作
public void insert(int data) {
if (tree == null) {
tree = new Node(data);
return;
}
Node p = tree;
while (p != null) {
if (data > p.data) {
if (p.right == null) {
p.right = new Node(data);
return;
}
p = p.right; // 继续在右子树遍历
} else { // data < p.data
if (p.left == null) {
p.left = new Node(data);
return;
}
p = p.left; // 继续在左子树遍历
}
}
}
// 删除操作
public void delete(int data) {
Node p = tree; // p指向要删除的节点,初始化指向根节点
Node pp = null; // pp记录的是p的父节点
while (p != null && p.data != data) {
pp = p;
if (data > p.data) p = p.right;
else p = p.left;
}
if (p == null) return; // 没有找到
// 要删除的节点有两个子节点
if (p.left != null && p.right != null) { // 查找右子树中最小节点
Node minP = p.right;
Node minPP = p; // minPP表示minP的父节点
while (minP.left != null) {
minPP = minP;
minP = minP.left;
}
p.data = minP.data; // 将minP的数据替换到p中
p = minP; // 下面就变成了删除minP了
pp = minPP;
}
// 删除节点是叶子节点或者仅有一个子节点
Node child; // p的子节点
if (p.left != null) child = p.left;
else if (p.right != null) child = p.right;
else child = null;
if (pp == null) tree = child; // 删除的是根节点
else if (pp.left == p) pp.left = child;
else pp.right = child;
}
// 找最小的结点
public Node findMin() {
if (tree == null) return null;
Node p = tree;
while (p.left != null) {
p = p.left;
}
return p;
}
// 找到最大的结点
public Node findMax() {
if (tree == null) return null;
Node p = tree;
while (p.right != null) {
p = p.right;
}
return p;
}
}