数据流交换策略
1. Dataflow Programming
在讨论流处理的基本概念之前,我们首先介绍一下数据流编程(dataflow programming)的基本概念与术语。
数据流图
数据流程序一般在由数据流图表示,数据流图描述了数据如何在操作之间流动。在数据流图中,节点被称为operator,代表计算;边代表数据依赖。
Operator是dataflow 应用中的基本单元,它们从输入消费数据,在之上执行计算,并生产数据提供给下一步处理。
没有输入的operators 称为数据源(data sources),没有输出的operator称为数据接收器(data sink)。一个dataflow graph 必须有至少一个data source以及一个data sink。例如:
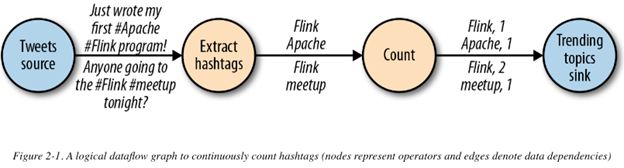
类似上图的dataflow graph 称为逻辑的(logical)数据流图,因为它们从高层的视角展示了计算逻辑。在执行时,逻辑图会被转换为物理图(physical dataflow graph),具体的执行逻辑会在物理数据流图中给出,如下图:
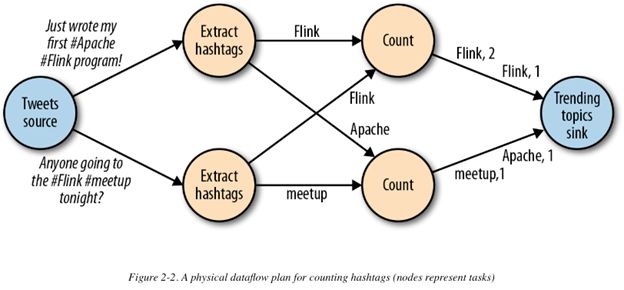
例如,如果我们使用分布式处理引擎,每个operator可能有多个并行的任务跑在不同的物理机器上。逻辑图表示了执行的逻辑,而物理图表示了具体的任务。
数据并行与任务并行
数据并行是指:将输入数据做partition,然后使用多个同样的task并行处理数据的子集。数据并行的意义在于将数据分散到多个计算节点上。
任务并行是指:有多个不同的task任务并行处理相同的或不同的数据。任务并行的意义在于更好的使用集群中的计算资源。
数据交换策略
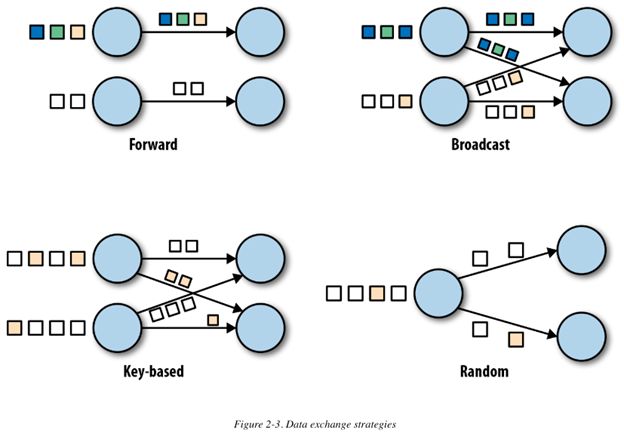
数据交换策略定义了:在physical dataflow graph中,数据条目如何分发到task 中。下面是几种常见的数据交换策略:
- 前向(forward)策略:从一个task发送数据到另一个接受task。如果两个task均在一个机器上,则可以避免网络传输
- 广播(broadcast)策略:数据发送到所有并行task中。此策略涉及到数据复制及网络传输,所以较为消耗资源
- key-based 策略:根据key做partition,使具有相同key 的条目可以被同一个task处理
- 随机(random)策略:随机均匀分布数据到task中,均衡集群计算负载
2. 并行流处理
在了解以上概念后,我们接下来讨论并行流处理。首先,我们定义数据流(data stream):数据流是一个(可能)无限的事件序列。
延迟与吞吐
对于批处理应用,我们一般关注的是一个job的整个执行时间,或是处理引擎需要多长时间读数据、计算、以及写入结果。而流处理应用是持续运行的,并且输入数据可能是无限的,所以对于整个应用的执行时间其实并没有太多关注。但是,流处理程序在处理高频率的事件输入的同时,还必须要在输入数据后尽可能快的提供结果。我们使用延迟(latency)与吞吐(throughput)来衡量这个需求。
延迟
延迟表示的是处理一个event所需要的时间。本质上,它是从:接受到event -> 到处理完此event -> 并在结果中有体现,这段时间。举个例子,假设你去咖啡店买咖啡,前面有人排队,在到你点完单后,店里会做咖啡,做好后叫号,然后你来取,取完后开始喝。这里的latency指的就是从你进咖啡店开始,一直到你喝到第一口咖啡的间隔时间。
在data streaming 中,latency由时间衡量,例如毫秒。根据application的不同,你可能会关注平均延迟、最高延迟、或是百分位数延迟(percentile latency)。例如:平均延迟为10ms,表示events平均在10ms内被处理。而百分位 95 的延迟为10ms表示的是有95% 的events在10ms内被处理。平均延迟值隐藏了处理延迟的分布,可能会难以定位问题。例如:如果咖啡师在为你准备咖啡时用光了牛奶,则你不得不去等待咖啡师去拿牛奶,这里你的咖啡会有更大的延迟,但是其他大部分用户并不会受到影响。
对于大部分流应用来说(例如系统告警、欺诈检测、网络监控等),保证低延迟至关重要。低延迟在流处理中是一个重要的特性,它是实现“实时”应用的基础。当前主流的流处理器(如Flink),可以提供低至几毫秒的延迟。相对而言,传统的批处理系统的延迟可一般会达到几分钟到几小时不等。在批处理中,首先需要的是将events收集为batch,然后再处理它。所以它的延迟取决于batch中最后一个event到达的时间,以及batch 的大小。真正的流处理并不引入这种延迟,所以可以实现真正的低延迟。在真正的流模型中,events在到达流系统后可以被立即处理,此时的延迟反应的是:在此event上执行的操作时间。
吞吐
吞吐用于衡量系统的处理能力:处理率。也就是说,它可以告诉我们,系统在每个时间片内可以处理多少个events。以咖啡店为例,如果咖啡店从早上7点开到晚上7点,每天服务600个客户,则它的平均吞吐为 50个顾客/每小时。在流系统中,我们需要延迟尽可能的低,而吞吐尽可能的高。
吞吐由每个时间单位内处理的evnets衡量。这里需要注意的是:处理速率取决于events的到达速率。低吞吐并不能完全说明系统性能低。在流系统中,一般希望确保系统最高能处理events的速率。也就是说,我们主要关心的是确定吞吐的峰值(peak throughput):在系统处于最高负载时的性能极限。为了更好地理解顶峰吞吐(peak throughput),我们考虑一个流处理应用,它一开始并不接收任何输入,所以此时并不小号任何系统资源。当第一个event到来时,它会立即(尽量)以最小的latency 处理。例如你是咖啡馆开门的第一个顾客,店员会立即为你去做咖啡。在理想情况下,你会希望随着更多events的进入,latency 可以保持较小值不发生太大的变动。然而,一旦输入的events到达某个速率,使得系统资源被完全使用时,就不得不开始缓存(buffering)events。拿咖啡店举例,在中午的时候,人流量会特别大,达到了咖啡店的顶峰,则这时候就需要开始排队了。这时候系统即达到了它的peak throughput,而更大的event rate只会使得latency变得更糟。如果系统继续以更高的速率接收输入(超过了它可以处理的速率),缓冲区可能会爆掉,并导致数据丢失。常规的解决方案是背压(backpressure),并有不同的策略去处理。
延迟 vs 吞吐
在这里需要明确的是,延迟与吞吐并不是两个互相独立的指标。如果事件到达数据处理管道的事件较长,便无法保证高吞吐。类似的,如果系统的性能较低,则events 会被缓存并等待,直到系统有能力处理。
再次以咖啡店为例,首先比较好理解的是,在负载低的时候,可以达到很好的一个latency。例如咖啡店里你是第一个也是唯一的一个顾客。但是在咖啡店较忙的时候,顾客就需要排队等待,此时的latency即会增加。另外一个影响延迟的因素(并继而影响到吞吐)是处理一个事件的时间。例如咖啡店为每个顾客做咖啡所消耗的时间。假设在一个圣诞节,咖啡师需要在每杯咖啡上画一个圣诞老人。也就是说,每杯咖啡制作的时间会增加,导致每个顾客在咖啡店消耗更多的时间,最终使得整体吞吐下降。
那是否可以同时达到低延迟与高吞吐?在咖啡店的例子中,你可以招聘更有经验的咖啡师,让做咖啡的效率更高。这里主要考量的地方是:减少延迟以增加吞吐。如果一个系统执行的操作更快,则它就可以在同一时间内处理更多的event。另外的方法是招聘更多的咖啡师,让同一时间有更多的客户被服务到。在流处理管道中,通过使用多个stream并行处理events,在获取更低的延时的同时,也可以在同一时间内处理更多的events。
References: