Linux大数据平台搭建master、slave1、slave2
实验采用的刚装好的三台虚拟机,名字分别为master、slave1、slave2.
用到的软件如下:

一、前期操作
1、启动网卡:(三台机器)
修改配置文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33将ONBOOT=no改为ONBOOT=yes,esc、:wq 保存退出
重启网卡:
sudo service network restartipaddr 或 ifconfig查看ip地址
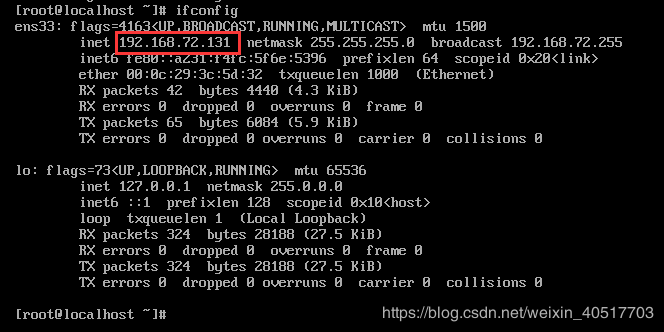
使用xshell软件远程连接电脑


2、上传相关软件(master)
创建安装包目录 mkdir /opt/soft
使用ftp工具上传软件,这里使用的是Xftp

3、修改主机名(三台机器)
以master为例
hostnamectl set-hostname master永久修改主机名 修改network相关参数
vi /etc/sysconfig/networkNETWORKING=yes
HOSTNAME=master下载相关工具
yum install -y net-tool重启计算机:reboot
查看是否生效:hostname
4、配置hosts文件(三台机器)
vi /etc/hosts内容如下:(ip地址视具体电脑的ip而定,使用ipaddr或ifconfig命令查看)
192.168.72.131 master
192.168.72.132 slave1
192.168.72.132 slave2其余两台机器相同操作
5、关闭防火墙(三台机器)
关闭防火墙:
systemctl stop firewalld禁止开机启动:
systemctl disable firewalld查看状态:
systemctl status firewalld
#或
firewall-cmd --state
6、时间同步
使用date命令查看机器当前时间
选择时区:tzselect 依次选择 亚洲 中国 北京时间 是否覆盖
5Asia->9China->1Beijing Time->1Yes
下载ntp(三台机器)
yum install -y ntp修改ntp配置文件(master)
vi /etc/ntp.conf末尾添加内容如下
service 127.127.1.0 #local clock
fudge 127.127.1.0 stratum 10 #stratum设置为其他值也可以,范围0~15重启ntp服务:
/bin/systemctl restart ntpd.service其他两台机器使用命令ntpdate master同步该master服务器时间
ntpdate master7、配置ssh免密
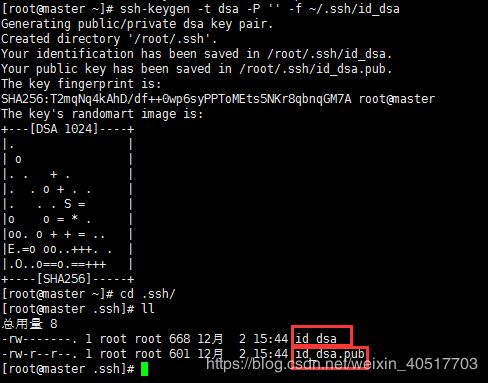
产生公钥秘钥(三台机器)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa进入目录查看:id_dsa为私钥,id_dsa.pub为公钥
cd .ssh/
在.ssh/路径下操作,将公钥文件复制成authorized_keys文件(master)
cat id_dsa.pub >> authorized_keys使用ssh master命令连接自己,也叫做ssh内回环
使用exit退出
让主节点能够通过ssh免密登录子节点
复制mater公钥文件到.ssh/目录且重命名为master_dsa.pub(slave1)
scp master:~/.ssh/id_dsa.pub ./master_dsa.pub.ssh/路径下将mater节点的公钥文件追加到authorized_keys中(slave1)
cat master_dsa.pub >> authorized_keys这是master就可以免密登录slave1了。
在slave2中按照在slave1操作执行即可。
二、软件安装
1、JDK的安装(三台机器)
建立工作路径并解压JDK
mkdir -p /usr/javatar -zxvf /opt/soft/jdk-8u171-linux-x64.tar.gz -C /usr/java/修改环境变量:
vi /etc/profile添加内容如下:
#jdk
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH生效环境变量:
source /etc/profile查看java版本:
java -version将master中的JDK复制到slave1、slave2中(保证slave1、slave2中已有相应目录)
scp -r /usr/java/jdk1.8.0_171/ slave1:/usr/java/scp -r /usr/java/jdk1.8.0_171/ slave2:/usr/java/2、zookeeper的安装(三台机器)
修改hosts文件(三台机器)可以在之前就设置好
192.168.72.131 master master.root
192.168.72.132 slave1 slave1.root
192.168.72.133 slave2 slave2.root
创建zookeeper工作目录并解压软件包(master):
mkdir -p /usr/zookeepertar -zxvf /opt/soft/zookeeper-3.4.10.tar.gz -C /usr/zookeeper/配置文件conf/zoo.cfg:进入zookeeper-3.4.10/conf目录,将zoo_sample.cfg拷贝一份并命名为zoo.cfg
scp zoo_sample.cfg zoo.cfg修改zoo.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata #需要修改
clientPort=2181
#以下信息需要添加
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888创建配置文件中的两个目录,zookeeper-3.4.10目录下
mkdir zkdatamkdir zkdatalog进入zkdata文件夹,创建文件myid 输入zoo.cfg文件中server后面的数字,比如master中就填入1
cd zkdatavi myid远程分发安装文件到子节点:
scp -r /usr/zookeeper root@slave1:/usr/scp -r /usr/zookeeper root@slave2:/usr/修改myid文件,slave1中为2,slave2中为3(slave1和slave2中)
vi /usr/zookeeper/zookeeper-3.4.10/zkdata/myid配置环境变量:(三台机器)
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile生效
启动zookeeper集群(三台机器)
启动:
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start查看状态:
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh statusjps查看进程:进程名:QuorumPeerMain
3、Hadoop的安装
创建工作目录并解压软件包到相应目录:(master)
mkdir /usr/hadooptar -zxvf /opt/soft/hadoop-2.7.3.tar.gz -C /usr/hadoop/配置环境变量:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/binsource /etc/profile生效文件
编辑hadoop环境配置文件hadoop-env.sh
修改export JAVA_HOME=
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_171编辑core-site.xml文件
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
/usr/hadoop/hadoop-2.7.3/hdfs/tmp
io.file.buff.size
131072
fs.checkpoint.period
60
fs.checkpoint.size
67108864
编辑yarn-site.xml文件
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.webapp.address
master:18088
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.nodename.aux-services
mapreduce_shuffle
yarn.nodename.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
编辑hdfs-site.xml文件
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/usr/hadoop/hadoop-2.7.3/hdfs/name
true
dfs.datanode.name.dir
file:/usr/hadoop/hadoop-2.7.3/hdfs/data
true
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
编辑mapred-site.xml(没有这个文件,需要将mapred-site.xml.template复制成mapred-site.xml)
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xmlvi /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
编写slaves文件,添加子节点
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/slavesslave1
slave2编写master文件,添加主节点
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/mastermaster分发hadoop(master)
scp -r /usr/hadoop/ root@slave1:/usr/scp -r /usr/hadoop/ root@slave2:/usr/子节点配置环境变量(slave1、slave2)
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/binmaster中格式化hadoop(/usr/hadoop/hadoop-2.7.3/etc/hadoop目录下)
hadoop namenode -formatmaster中开启集群,仅在master中开启操作命令,会带起从节点的启动
/usr/hadoop/hadoop-2.7.3/sbin/start-all.shjps查看进程,
master中的SecondaryNameNode、ResourceManager、NameNode
slave1、slave2中的进程:DataNode、NodeManager
浏览器输入masterIp:50070访问集群WebUI,比如:192.168.72.131:50070
查看hdfs
查看根目录文件:hadoop fs -ls /
在hdfs上创建文件夹data:hadoop fs -mkdir /data
再次查看会有创建的文件夹:hadoop fs -ls /
在web中查看的方式:Utilities->Browse the file system
4、hbase的安装
建立工作路径:
mkdir -p /usr/hbase解压软件包:
tar -zxvf /opt/soft/hbase-1.2.4-bin.tar.gz -C /usr/hbase/修改配置文件hbase-env.sh
vi /usr/hbase/hbase-1.2.4/conf/hbase-env.sh# Set environment variables here.
export HBASE_MANAGES_ZK=false
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/java/jdk1.8.0_171
# Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/hadoop配置hbase-site.xml
vi /usr/hbase/hbase-1.2.4/conf/hbase-site.xml
hbase.rootdir
hdfs://master:9000/hbase
hbase.cluster.distributed
true
hbase.master
hdfs://master:6000
hbase.zookeeper.quorum
master,slave1,slave2
hbase.zookeeper.property.dataDir
/usr/zookeeper/zookeeper-3.4.10
配置regionservers:这里列出了希望运行的HRegionServer,一行写一个host。列在这里的server会随着集群的启动而启动,集群的停止而停止。
vi /usr/hbase/hbase-1.2.4/conf/regionservers slave1
slave2将hadoop配置文件拷入hbase的conf目录下(当前位置为hbase的conf文件夹),注意后面的点
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml .
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml .分发hbase(master)
scp -r /usr/hbase root@slave1:/usr/
scp -r /usr/hbase root@slave2:/usr/配置环境变量(三台机器)
#hbase
export HBASE_HOME=/usr/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin运行和测试(在master上执行,保证hadoop和zookeeper已开启)
/usr/hbase/hbase-1.2.4/bin/start-hbase.sh 相关进程:
master:HMaster
slave:HRegionServer
访问master的hbase web界面:http://masterIP:16010/master-status
例如:http://192.168.72.131:16010/master-status
进入hbase交互界面,查看状态与版本信息等
[root@master ~]# hbase shell
hbase(main):002:0> status
1 active master, 0 backup masters, 2 servers, 0 dead, 1.0000 average load
hbase(main):003:0> version
1.2.4, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016
hbase(main):004:0> exit
[root@master ~]# 三、构建数据仓库
1、slave2中安装mysql server
安装EPEL源:
yum -y install epel-release安装mysql server包,下载源安装包(如果没有wget需要下载wget)
yum install -y wgetwget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm安装源:
rpm -ivh mysql57-community-release-el7-8.noarch.rpm 查看是否有包:mysql-community.repo、mysql-community-source.repo
cd /etc/yum.repos.d
ll安装MySQL:
yum install -y mysql-community-server启动服务:
重置所有修改过的配置文件:
systemctl daemon-reload开启服务:
systemctl start mysqld开机自启:
systemctl enable mysqld获取初始密码:
grep 'temporary password' /var/log/mysqld.log![]()
登录MySQL:
mysql -u root -p修改MySQL密码安全策略:
设置密码强度为低级:
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)设置密码长度:
mysql> set global validate_password_length=4;
Query OK, 0 rows affected (0.00 sec)修改本地密码:
mysql> alter user 'root'@'localhost' identified by '123456';
Query OK, 0 rows affected (0.01 sec)使用\q或exit退出mysql
设置远程登录:
用新密码登录mysql:mysql -u root -p
创建用户:
mysql> create user 'root'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)允许远程连接:
mysql> grant all privileges on *.* to 'root'@'%' with grant option;
Query OK, 0 rows affected (0.00 sec)刷新权限:
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)2、安装hive(master、slave1)
master和slave1中建立工作目录:
mkdir -p /usr/hivemaster中解压安装包:
tar -zxvf /opt/soft/apache-hive-2.1.1-bin.tar.gz -C /usr/hivemaster远程复制解压文件到slave1中:
scp -r /usr/hive/apache-hive-2.1.1-bin root@slave1:/usr/hive设置环境变量(master、slave1):
#hive
export HIVE_HOME=/usr/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin因为服务器端需要和mysql通信,所以需要mysql的lib安装包到HIVE_HOME/conf目录下(master)
复制到slave2中:
scp /opt/soft/mysql-connector-java-5.1.5-bin.jar root@slave2:/lib复制到slave1中:
scp /opt/soft/mysql-connector-java-5.1.5-bin.jar root@slave1:/usr/hive/apache-hive-2.1.1-bin/lib修改hive-env.sh中HADOOP_HOME:(salve1)
复制conf下的hive-env.sh.template并重命名为hive-env.sh
cp /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh.template /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh编辑HADOOP_HOME
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.shHADOOP_HOME=/usr/hadoop/hadoop-2.7.3修改hive-site.xml(slave1 conf文件夹新建)(slave1)
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
hive.metastore.warehouse.dir
/user/hive_remote/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.metastore.schema.verification
false
datanucleus.schme,autoCreateAll
true
Master作为客户端
解决版本冲突和 jar 包依赖问题。 由于客户端需要和 Hadoop 通信,所以需要更改 Hadoop 中 jline 的版本。即 保留一个高版本的 jline jar 包,从 hive 的 lib 包中拷贝到 Hadoop 中 lib 位置
(master和slave1)
cp /usr/hive/apache-hive-2.1.1-bin/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/master中修改hive-env.sh(复制模板文件并重命名)
cp /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh.template /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.shvi /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.shHADOOP_HOME=/usr/hadoop/hadoop-2.7.3master中修改hive-site.xml(master conf文件夹新建)
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
hive.metastore.warehouse.dir
/user/hive_remote/warehouse
hive.metastore.local
false
hive.metastore.uris
thrift://slave1:9083
启动hive:
启动hive server(slave1)
/usr/hive/apache-hive-2.1.1-bin/bin/hive --service metastore启动hive client(master)
/usr/hive/apache-hive-2.1.1-bin/bin/hive