Electron学习之旅3,富文本编辑器与选择,state设计原则,回调数据流,反向数据流,vh,state和useState的immutable问题,uuid,flatten state哈希map
1、富文本编辑器与选择
根据七牛云自身的需求,符合的开源项目为:simplemde-markdown-editor
但是其最后一次维护是4年前,经fork搜寻。
定位新项目:easy-markdown-editor,github官网地址
但是该项目并非基于react框架环境,然后继续在开源世界寻找,果然找到了react可用的依赖。
RIP21/react-simplemde-editor git地址
引入后简单使用如下:

注:较著名的富文本编辑器还有TinyMCE、ueEditor、fckEditor。
二、State设计原则
1、最小化state原则
2、DRY: Don’t Repeat Yourself
3、使数据尽量基于已有State计算得出
4、使用多个State变量,而不是每次回溯全部数据。
七牛云state分析:
1、左侧面板已有的文件,的列表
2、搜索框搜索后,筛选出的文件,的列表
3、右侧面板未保存的文件,的列表
4、右侧面板 已被点击,或打开的文件,的列表
5、当前被打开的文件
数据结构初次设计
files: [{id: '1'},{id: '2'}, ...]
searchedFiles: [{id: '1'}, ...]
unsavedFiles:[{id: '4'}, ...]
openedFiles:[{id: '2'}, {id: '4'},...]
activeFile: {id: '2'}
注:上述数据设计是有问题的,每次都将重复的列表数据一遍又一遍放入state中
进化后的数据结构
files: [{id: '1'},{id: '2'}, ...]
unsavedFileIDs:['1','2']
openedFileIDs:['2','4']
activeFileID: '2'
unsavedFile、opendFile、activeFile完全可以基于Files计算得出。
三、回调数据流
1、展示型组件,抽离出其逻辑api,自身不处理任何逻辑,全都交由父组件App去管理。
App: tabClick 子组件: onTabClick
四、反向数据流
从子组件开始,不断完善父组件的逻辑api。
五、vh
css3新属性,height: 100vh; 使 高度占据视窗的100%
六、state和useState问题,以及immutable
偶然发现修改数组某对象的字段,根本不用重新set,也会触发数据更新,但并不是重新render。
也就是引用地址相同,字段被改变,会自动更新该字段。
![]()
而普通class类型组件通过引用地址修改字段是不会更新的,也不会重渲必须setState才可以。
张轩老师说了,useState Hook,去修改引用地址内的字段是可以工作的,但是react文档写过state是immutable的,是不可以修改的。修改会造成一定的BUG。
目前useState这个hook还在学习阶段,发现和class的state相比,更轻量,但是注意点也挺多。
七、uuid
创建一个通用唯一表示码
// 使用之前安装依赖,npm install uuid --save
import uuidv4 from 'uuid/v4';
const newID = uuidv4();
// newID: 2241badb-57df-48d5-845a-479a58666291
八、flatten state哈希map
扁平化数据
1、解决数组冗余
2、数据处理更加方便
看下述两段代码,其实每次调用都要写遍历语句,去找到对应id的数据。
// 左侧面板移除文件
const deleteFile = (id) => {
// 筛选文件
const newFiles = files.filter(file => file.id !== id);
setFiles(newFiles)
tabClose(id);
}
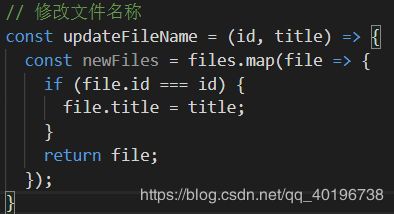
// 修改文件名称
const updateFileName = (id, title) => {
const newFiles = files.map(file => {
if (file.id === id) {
file.title = title;
file.isNew = false;
}
return file;
});
setFiles(newFiles);
}
是因为数据本身是数组且存储的对象,不能通过key值去快速定位,那么经过哈希 map优化之后的数据格式是怎样的呢?
// 原始数据
const files = [
{
id: '1',
title: 'first post',
body: 'should be aware of this',
createAt: 1563762965704
},
{
id: '2',
title: 'second post',
body: '## i love meatmeat',
createAt: Date.now()
}
]
// 哈希map优化之后
const files = {
'1': {...file},
'2': {...files}
}
优化之后数据的操作如下
// 查找一个数据
const activeFile = files[activeFileID]
// 修改一个数据,需要执行保存
const modifiedFile = { ...files[id],titile,isNew: false}
// 删除数据
delete files[deletedID]
创建helper.js工具库
// 扁平化数组
export const flattenArr = (arr) => {
return arr.reduce((map, item) => {
map[item.id] = item;
return map;
}, {});
}
// 还原数组
export const objToArr = (obj) => {
return Object.keys(obj).map(key => obj[key]);
}