【今日CV 计算机视觉论文速览 第140期】Wed, 3 Jul 2019
今日CS.CV 计算机视觉论文速览
Wed, 3 Jul 2019
Totally 49 papers
?上期速览✈更多精彩请移步主页

Interesting:
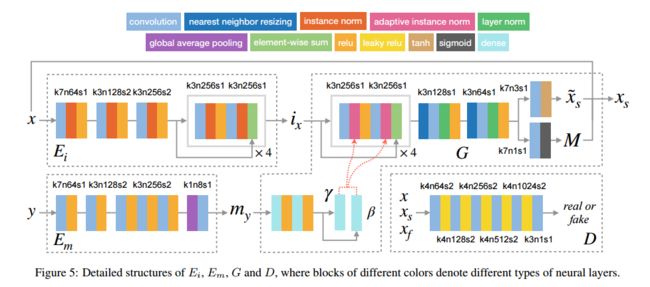
?DMT解耦的妆容迁移框架,研究人员提出了一种基于解耦的妆容迁移框架,将图像中的任务编码与妆容编码分别表示,随后利用不同的妆容编码与任务编码进行联合解码实现了妆容的渐变、插值、混合,人脸混合与多模态采样的等美妆任务。 (from 上交)

文中提出的方法,同时还引入了mask注意力机制:
学习到的嵌入空间表示,不同的妆有一个明显的聚类:
人脸妆容渐变与混合:

人脸插值与妆容编码随机采样:


最后还探索了隐空间编码(8-vector)每个维度对于妆容各方面的影响:

code:https://github.com/Honlan/DMT
?一种智能图像裁剪方法, 研究人员提出了一种淤血学习图像中主体构成的框架用于评价图像的美学质量。其中一个锚区域用于检测,并利用高斯核保证了图像中主体的完整性。随后馈入到一个轻量级的网络中,直接映射出最终的剪切结果。计算资源消耗较低。(from 北邮)
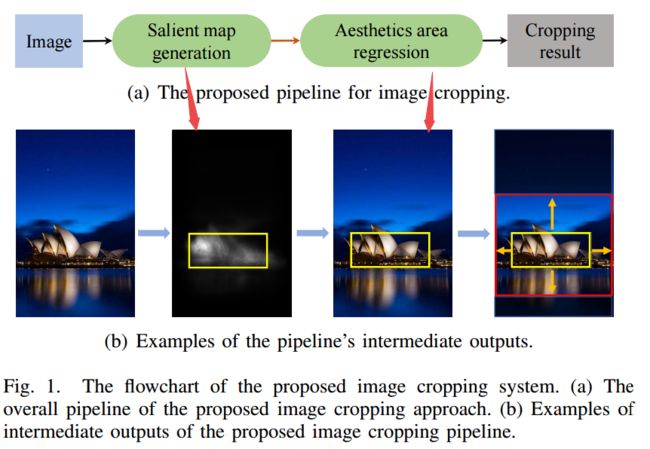
研究人员提出的显著性检验方法和美学区域回归器:
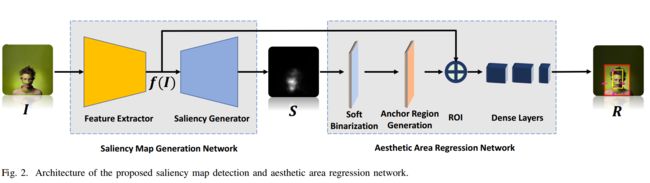
其中限制性检验的网络利用了类型四Unet的方法:
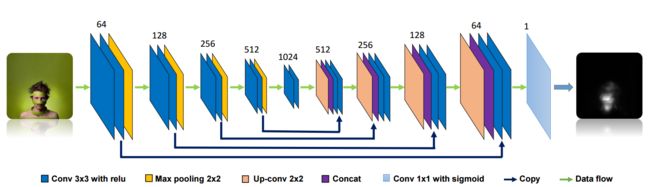
在不同数据集上的结果:
智能剪切的结果:

code:https://github.com/CVBase-Bupt/EndtoEndCroppingSystem
?提出了一种可以从单个或多个视角预测物体三维形状的模型, (from Stanford University Google Inc. Facebook AI Research)

?BMOD一个移动端的OCR数据集, 一个用于低质量光学字符识别的数据集,包含非均匀光照、模糊、噪声以及各种人工痕迹的缺陷。(from Brno University of Technology)

?Language2Pose将语言转换为位姿模拟动画的新方法,研究人员提出了Joint Language-toPose(JL2P) 的方法俩学习语言与动作的联合嵌入空间。(from CMU,Language Technologies Institute)

project:http://chahuja.com/language2pose/
?高铁 铁轨扣件的高速检测, (from 北邮)

基于faster-rcnn的方法:

Daily Computer Vision Papers
| ++HO-3D: A Multi-User, Multi-Object Dataset for Joint 3D Hand-Object Pose Estimation Authors Shreyas Hampali, Markus Oberweger, Mahdi Rad, Vincent Lepetit 我们提出了一种用于从彩色图像估计3D手对象姿态的新数据集,以及用于有效地注释该数据集的方法,以及基于该数据集的3D姿势预测方法。目前缺乏训练数据使得3D手对象姿势估计非常具有挑战性。这种缺乏是由于使用3D姿势标记许多真实图像以及生成具有各种真实交互的合成图像的复杂性。此外,即使合成图像可用于训练,仍需要带注释的真实图像进行验证。为了应对这一挑战,我们使用由单个RGB D相机组成的简单设置捕获序列。我们还使用彩色相机从侧视图对序列进行成像,但仅用于验证。我们介绍了一种基于全局优化的新方法,该方法利用深度,颜色和时间约束来有效地注释序列,我们用它来训练另一种新方法,该方法从单个彩色图像预测手部和物体的3D姿势。我们希望鼓励其他研究人员为我们的数据集开发更好的注释方法然后可以应用这种方法捕获并轻松注释用单个RGB D相机捕获的序列,以轻松创建额外的训练数据,从而解决3D手的主要问题之一物体姿态估计。 |
| Obj-GloVe: Scene-Based Contextual Object Embedding Authors Canwen Xu, Zhenzhong Chen, Chenliang Li 最近,随着大规模图像数据集的普及,类之间的共现信息变得丰富,需要一种新的方式来利用它来促进推理。在本文中,我们提出了Obj GloVe,一种基于通用场景的常见视觉对象的上下文嵌入,我们采用嵌入方法GloVe来利用实体之间的共现。我们在预处理的Open Images V4数据集上训练嵌入,并通过降维和沿特定语义轴投影向量提供广泛的可视化和分析,并展示最常见对象的最近邻居。此外,我们揭示了Obj GloVe在物体检测和文本到图像合成方面的潜在应用,然后分别验证了它在这两种应用中的有效性。 |
| +++Attribute-Driven Spontaneous Motion in Unpaired Image Translation Authors Ruizheng Wu, Xin Tao, Xiaodong Gu, Xiaoyong Shen, Jiaya Jia 当前的图像转换方法虽然对于在各种应用中产生高质量结果是有效的,但仍然没有考虑太多的几何变换。我们在本文中提出自发运动估计模块以及细化模块,以学习源域和目标域之间的属性驱动变形。广泛的实验和可视化证明了这些模块的有效性。我们在不成对的图像翻译任务中取得了可喜的成果,并以自发运动为基础实现了有趣的应用。 |
| +++An End-to-End Neural Network for Image Cropping by Learning Composition from Aesthetic Photos Authors Peng Lu, Hao Zhang, Xujun Peng, Xiaofu Jin 作为图像编辑的基本技术之一,图像裁剪丢弃了不相关的内容,并且仍然是图像的令人愉悦的部分,以增强整体构图并实现更好的视觉美感。在本文中,我们主要关注提高自动图像裁剪的准确性,并进一步探索其在公共数据集中的高效潜力。从这个方面来说,我们提出了一个基于深度学习的框架,用于从具有高美学品质的照片中学习对象组合,其中通过具有高斯核的卷积神经网络CNN来检测锚区域以维持感兴趣的对象的完整性。然后将该初始检测到的锚定区域馈送到轻量级回归网络中以获得最终的裁剪结果。与传统方法不同,迭代地提出并评估多个候选者,在我们的模型中仅产生单个锚定区域,其直接映射到最终输出。因此,所提出的方法需要低计算资源。公共数据集的实验结果表明,裁剪的准确性和效率都达到了现有的性能水平。 |
| Where are the Masks: Instance Segmentation with Image-level Supervision Authors Issam H. Laradji, David Vazquez, Mark Schmidt 实例分割的主要障碍是现有方法通常需要许多每像素标签才能有效。这些标签需要大量的人力,并且对于某些应用,这种标签不容易获得。为了解决这个限制,我们提出了一种新的框架,可以有效地训练图像级标签,这些标签的获取成本要低得多。例如,人们可以对汽车一词进行互联网搜索,并以最小的努力获得汽车所在的许多图像。我们的框架包括两个阶段1训练分类器以生成感兴趣对象的伪掩码2在这些伪掩码上训练完全受监督的掩码R CNN。我们的两个主要贡献是提出一个易于实现的管道,并且适用于不同的分割方法,并且为这个问题设置实现了新的最先进的结果。我们的结果是基于PASCAL VOC 2012评估我们的方法,PASCAL VOC 2012是弱监督方法的标准数据集,我们展示了与现有方法相比在平均精度方面的主要性能提升。 |
| Improving Borderline Adulthood Facial Age Estimation through Ensemble Learning Authors Felix Anda, David Lillis, Aikaterini Kanta, Brett A. Becker, Elias Bou Harb, Nhien An Le Khac, Mark Scanlon 在成年和非成年之间的边界线上实现面部年龄估计的高性能一直是一个挑战。一些研究使用了从婴儿时代到老年人的不同方法,并且已经使用不同的数据集来测量1.47至8年范围内的平均绝对误差MAE。特别是在边界线中的算法的弱点一直是本文的动机。在我们的方法中,我们开发了一种集合技术,结合我们深度学习模型DS13K提高了未成年人估计的准确性,该模型已经在Deep Expectation DEX模型上进行了微调。对于16至17岁的年龄组,我们已经达到了68的准确度,这比这个年龄段的DEX准确度好4倍。我们还对现有的基于云和离线的面部年龄预测服务进行评估,例如Amazon Rekognition,Microsoft Azure Cognitive Services, |
| Landmark Assisted CycleGAN for Cartoon Face Generation Authors Ruizheng Wu, Xiaodong Gu, Xin Tao, Xiaoyong Shen, Yu Wing Tai, Jiaya Jia 在本文中,我们感兴趣的是通过在真实面孔和卡通面孔之间使用不成对的训练数据来生成人的卡通面部。这项任务的一个主要挑战是真实和卡通人脸的结构在两个不同的领域,其外观彼此相差很大。如果没有明确的对应关系,很难生成捕捉人的基本面部特征的高质量卡通脸。为了解决这个问题,我们提出了地标辅助的CycleGAN,它利用面部地标来定义地标一致性损失,并指导在CycleGAN中训练局部鉴别器。为了强化地标的结构一致性,我们使用条件生成器和鉴别器。我们的方法能够产生高质量的卡通面孔,甚至与艺术家绘制的面孔无法区分,并且在很大程度上改善了现有技术水平。 |
| A Closest Point Proposal for MCMC-based Probabilistic Surface Registration Authors Dennis Madsen, Andreas Morel Forster, Patrick Kahr, Dana Rahbani, Thomas Vetter, Marcel L thi 在本文中,我们提出了一种非刚性表面配准算法,该算法使用马尔可夫链蒙特卡罗MCMC框架估计对应不确定性。推断登记的估计不确定性对于许多应用是重要的,例如手术计划或缺失数据重建。使用的Metropolis Hastings MH算法使用建议和验证方案将推断与后验建模分离。广泛使用的随机抽样策略导致高维空间中的收敛速度慢。为了克服这个限制,我们引入了基于ICP的知情概率提议,可以在MH算法中使用。虽然ICP算法用于推理算法,但可以独立地选择可能性。我们展示了不同的表面距离测量,例如传统的欧几里德范数和豪斯多夫距离。在量化对应的不确定性的同时,我们还通过实验验证了我们的方法比非刚性ICP算法更稳健,并提供更准确的表面配准。在重建任务中,我们展示了如何使用我们的概率框架来估计缺失数据的后验分布,而不假设一个固定的点对点对应。我们已经为社区公开了我们的注册框架。 |
| A Single Video Super-Resolution GAN for Multiple Downsampling Operators based on Pseudo-Inverse Image Formation Models Authors Santiago L pez Tapia, Alice Lucas, Rafael Molina, Aggelos K. Katsaggelos 高清和超高清显示器的普及使得需要一种方法来改善已经以低得多的分辨率获得的视频的质量。当前的视频超分辨率方法对于训练和测试退化模型之间的不匹配并不健壮,因为它们针对单个降级模型进行训练,通常是双三次下采样。这导致它们在现实生活中的性能恶化。同时,在学习期间仅使用均方误差导致所得图像太平滑。在这项工作中,我们提出了一种新的用于视频超分辨率的卷积神经网络,该网络对多种退化模型具有鲁棒性。在训练过程中,这是在大型慢速和快速运动场景数据集上进行的,除了平滑约束外,它还使用伪逆图像形成模型作为网络结构的一部分与感知损失相结合,消除了源自这些感性损失。实验验证表明,我们的方法优于当前最先进的方法,并且对多种降级具有鲁棒性。 |
| CSSegNet: Fine-Grained Cardiac Structures Segmentation Using Dilated Pyramid Pooling in U-net Authors Fei Feng, Jiajia Luo 心脏结构分割在医学分析程序中起着重要作用。图像模糊边界问题总是限制分割性能。为了解决这个难题,我们提出了一种新颖的网络结构,它在网络编码和解码阶段之间的跳过连接中嵌入了扩展的金字塔池。扩张的金字塔汇集块由具有不同视野范围的卷积和汇集操作组成。配备这种模块的模型,可以赋予多尺度视觉能力。结合其他技术,它包括多尺度初始特征提取和多分辨率预测聚合模块。对于骨干特征提取网络,我们提到了受益于可分离卷积的Xception网络的基本思想。根据2017年MICCAI ACDC挑战阶段数据评估,我们提出的模型可以实现左心室LVC腔和右心室腔RVC分割任务的最新技术性能。结果表明,我们的方法在几何Dice系数,Hausdorff距离和临床评价弹射分数,体积方面都有优势,它们分别代表更接近的边界和更具统计学意义。 |
| Training Auto-encoder-based Optimizers for Terahertz Image Reconstruction Authors Tak Ming Wong, Matthias Kahl, Peter Haring Bol var, Andreas Kolb, Michael M ller 太赫兹THz传感是一种很有前景的成像技术,适用于各种不同的应用。然而,为这些应用提取可解释的和物理上有意义的参数需要解决反问题,其中由这些参数确定的模型函数需要适合于测量数据。由于潜在的优化问题是非凸的并且解决成本非常高,我们建议直接从测量数据中学习合适参数的预测。更准确地说,我们开发了一种基于模型的自动编码器,其中编码器网络预测合适的参数,并且解码器固定为物理上有意义的模型函数,使得我们可以以无人监督的方式训练编码网络。我们用数字方式说明,得到的网络比经典优化技术快140倍,同时只用稍高的目标值进行预测。使用这种预测作为局部优化技术的起点使我们能够收敛到更好的局部最小值,大约是优化的两倍,而无需基于网络的初始化。 |
| Multi-scale GANs for Memory-efficient Generation of High Resolution Medical Images Authors Hristina Uzunova, Fabian Jacob, Alex Frydrychowicz, Heinz Handels, Jan Ehrhardt 目前,生成对抗性网络GAN由于其大量计算需求而很少应用于大尺寸的医学图像,尤其是3D体积。我们提出了一种新的基于多尺度贴片的GAN方法来生成大的高分辨率2D和3D图像。我们的主要想法是首先学习低分辨率版本的图像,然后生成以先前尺度为条件的连续增长分辨率的补丁。在域转换用例场景中,生成尺寸为512x512x512的3D胸部CT和尺寸为2048x2048的胸部X射线,并且我们显示,由于我们的方法的恒定GPU存储器需求,可以生成任意大的高分辨率图像。此外,与基于常见补丁的方法相比,我们的多分辨率方案可实现更好的图像质量并防止补丁伪影。 |
| Pathologist-Level Grading of Prostate Biopsies with Artificial Intelligence Authors Peter Str m 1 , Kimmo Kartasalo 2 , Henrik Olsson 1 , Leslie Solorzano 3 , Brett Delahunt 4 , Daniel M. Berney 5 , David G. Bostwick 6 , Andrew J. Evans 7 , David J. Grignon 8 , Peter A. Humphrey 9 , Kenneth A. Iczkowski 10 , James G. Kench 11 , Glen Kristiansen 12 , Theodorus H. van der Kwast 7 , Katia R.M. Leite 13 , Jesse K. McKenney 14 , Jon Oxley 15 , Chin Chen Pan 16 , Hemamali Samaratunga 17 , John R. Srigley 18 , Hiroyuki Takahashi 19 , Toyonori Tsuzuki 20 , Murali Varma 21 , Ming Zhou 22 , Johan Lindberg 1 , Cecilia Bergstr m 23 , Pekka Ruusuvuori 2 , Carolina W hlby 3 and 24 , Henrik Gr nberg 1 and 25 , Mattias Rantalainen 1 , Lars Egevad 26 , Martin Eklund 1 1 Department of Medical Epidemiology and Biostatistics, Karolinska Institutet, Stockholm, Sweden, 2 Faculty of Medicine and Health Technology, Tampere University, Tampere, Finland, 3 Centre for Image Analysis, Department of Information Technology, Uppsala University, Uppsala, Sweden, 4 Department of Pathology and Molecular Medicine, Wellington School of Medicine and Health Sciences, University of Otago, Wellington, New Zealand, 5 Barts Cancer Institute, Queen Mary University of London, London, UK, 6 Bostwick Laboratories, Orlando, FL, USA, 7 Laboratory Medicine Program, University Health Network, Toronto General Hospital, Toronto, ON, Canada, 8 Department of Pathology and Laboratory Medicine, Indiana University School of Medicine, Indianapolis, IN, USA, 9 Department of Pathology, Yale University School of Medicine, New Haven, CT, USA, 10 Department of Pathology, Medical College of Wisconsin, Milwaukee, WI, USA, 11 Department of Tissue Pathology and Diagnostic Oncology, Royal Prince Alfred Hospital and Central Clinical School, University of Sydney, Sydney, NSW, Australia, 12 Institute of Pathology, University Hospital Bonn, Bonn, Germany, 13 Department of Urology, Laboratory of Medical Research, University of S o Paulo Medical School, S o Paulo, Brazil, 14 Pathology and Laboratory Medicine Institute, Cleveland Clinic, Cleveland, OH, USA, 15 Department of Cellular Pathology, Southmead Hospital, Bristol, UK, 16 Department of Pathology, Taipei Veterans General Hospital, Taipei, Taiwan, 17 Aquesta Uropathology and University of Queensland, Brisbane, Qld, Australia, 18 Department of Laboratory Medicine and Pathobiology, University of Toronto, Toronto, ON, Canada, 19 Department of Pathology, Jikei University School of Medicine, Tokyo, Japan, 20 Department of Surgical Pathology, School of Medicine, Aichi Medical University, Nagoya, Japan, 21 Department of Cellular Pathology, University Hospital of Wales, Cardiff, UK, 22 Department of Pathology, UT Southwestern Medical Center, Dallas, TX, USA, 23 Department of Immunology, Genetics and Pathology, Uppsala University, Uppsala, Sweden, 24 BioImage Informatics Facility of SciLifeLab, Uppsala, Sweden, 25 Department of Oncology, S t G ran Hospital, Stockholm, Sweden, 26 Department of Oncology and Pathology, Karolinska Institutet, Stockholm, Sweden 背景技术越来越多的前列腺活组织检查和全球尿路病理学家的短缺给病理科带来了压力。另外,分级内和观察者之间的高度可变性可导致前列腺癌的过度和不足。人工智能AI方法可以通过帮助病理学家减少工作量和协调分级来缓解这些问题。 |
| FastDVDnet: Towards Real-Time Video Denoising Without Explicit Motion Estimation Authors Matias Tassano, Julie Delon, Thomas Veit 在本文中,我们提出了一种基于卷积神经网络架构的最先进的视频去噪算法。直到最近,使用神经网络的视频去噪已经在很大程度上被探索的领域,并且现有方法不能与基于最佳补丁的方法的性能竞争。我们在本文中介绍的方法称为FastDVDnet,与其他最先进的竞争对手相比,显示出相似或更好的性能,计算时间明显更短。与其他现有的神经网络降噪器相比,我们的算法具有多种理想的特性,例如快速运行时间,以及使用单一网络模型处理各种噪声水平的能力。其架构的特性使得可以避免使用昂贵的运动补偿阶段,同时实现卓越的性能。它的去噪性能和较低的计算负荷之间的结合使得该算法对于实际的去噪应用具有吸引力。我们将我们的方法与不同的现有算法进行比较,包括视觉和客观质量指标。 |
| The Ethical Dilemma when (not) Setting up Cost-based Decision Rules in Semantic Segmentation Authors Robin Chan, Matthias Rottmann, Radin Dardashti, Fabian H ger, Peter Schlicht, Hanno Gottschalk 用于语义分割的神经网络可以被视为统计模型,其为一个图像的每个像素提供预定义类别上的概率分布。然后通常通过最大后验概率MAP获得预测类,其在决策理论中被称为贝叶斯规则。从决策理论我们也知道贝叶斯规则对于简单对称代价函数是最优的。因此,它同等地对两个不同类别之间的每种类型的混淆进行加权,例如,给定城市街道场景的图像,如果网络将人与街道或建筑物与树混淆,则在成本函数中没有区别。直观地说,可能存在比其他类更重要的类混淆。在这项工作中,我们希望提高对明确界定混淆成本和相关道德困难的可能性的认识,如果它归结为提供数字。我们从不同的极端视角定义了两个成本函数,即利己主义和利他主义,并展示了在MAP,利己主义和利他决策规则之间进行插值时,安全相关数量如精确回忆和分段明显的假阳性负利率变化。 |
| +++Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer Authors Katrin Lasinger, Ren Ranftl, Konrad Schindler, Vladlen Koltun 单眼深度估计的成功依赖于大量且多样化的训练集。由于在不同环境中大规模获取密集地面实况深度所带来的挑战,出现了许多具有不同特征和偏差的数据集。我们开发的工具可以在训练期间混合多个数据集,即使它们的注释不兼容。特别是,我们提出了一个培训目标,该目标对于深度范围和规模的变化是不变的。有了这个目标,我们将探索丰富的3D电影培训数据来源。我们证明,尽管存在普遍的不准确性,3D电影构成了与现有训练集互补的有用数据源。我们评估所提出的各种数据集方法,重点关注零射击交叉数据集传输,通过在训练期间未见到的数据集上对其进行评估来测试学习模型的一般性。实验证实,混合来自互补源的数据可以改善深度估计,特别是在以前看不见的数据集上。一些结果显示在补充视频中 |
| Unsupervised Deformable Image Registration Using Cycle-Consistent CNN Authors Boah Kim, Jieun Kim, June Goo Lee, Dong Hwan Kim, Seong Ho Park, Jong Chul Ye 医学图像配准是生物医学图像分析(如癌症诊断)的关键处理步骤之一。最近,基于深度学习的监督和非监督图像配准方法由于其优异的性能而被广泛研究,尽管与传统方法相比具有超快的计算时间。在本文中,我们提出了一种新的无监督医学图像配准方法,该方法使用循环一致性来训练深度神经网络以用于3D体积的可变形配准。由于循环一致性,所提出的深度神经网络可以采用具有严重变形的各种图像数据以进行精确配准。使用多相肝脏CT图像的实验结果表明,我们的方法在几秒钟内提供非常精确的3D图像配准,从而导致更准确的癌症大小估计。 |
| Brno Mobile OCR Dataset Authors Martin Ki , Michal Hradi , Old ich Kodym 我们从手持移动设备捕获的低质量图像中引入用于文档光学字符识别的Brno Mobile OCR数据集B MOD。虽然高质量扫描文档的OCR是一个成熟的领域,其中有许多商业工具可用,并且存在大量的文本数据集,但是没有现有的数据集可用于开发和测试对非均匀照明,图像模糊有效的文档OCR方法,强大的噪音,内置去噪,锐化,压缩和其他工件,存在于移动设备的许多照片中。 |
| An Integrated Image Filter for Enhancing Change Detection Results Authors Dawei Li, Siyuan Yan, Xin Cai, Yan Cao, Sifan Wang 变化检测是计算机视觉中的基本任务。尽管取得了显着进步,但由于普遍存在的噪声和干扰,大多数变化检测方法在挑战性场景中都不能很好地工作。如今,后处理方法,例如旨在增强二元变化检测结果的MRF和CRF仍然不符合对于特殊场景的普遍性的要求,对不同类型的检测方法的适用性,准确性和实时性能。受图像滤波性质的启发,图像滤波将噪声与像素观测分开并恢复斑块的真实结构,我们考虑利用图像滤波器来增强检测掩模。在本文中,我们提出了一个集成滤波器,它包括一个加权局部引导图像滤波器和一个加权时空树滤波器。时空树滤波器利用相邻视频帧的全局时空信息,同时导引滤波器对像素进行局部窗滤波,以增强粗变检测掩模。主要贡献是三个,所提出的滤波器可以充分利用连续帧中相同对象的信息,通过在时空最小生成树上的计算来改善其当前检测掩模.i集成滤波器具有局部滤波和全局滤波的优点它不仅具有良好的边缘保持特性,而且还可以处理纹理丰富且色彩丰富的前景区域。iii与一些常用的增强方法MRF和CRF不同,MRF和CRF需要先验背景概率或每个像素的后验前景概率来改善粗略检测掩模我们的方法是一种通用的增强滤波器,可以在许多不同类型的变化检测方法之后应用,特别适用于视频序列。 |
| Dynamic Face Video Segmentation via Reinforcement Learning Authors Yujiang Wang, Jie Shen, Mingzhi Dong, Yang Wu, Shiyang Cheng, Maja Pantic 对于实时语义视频分段,最近的工作利用具有密钥调度器的动态框架来进行在线密钥非密钥决策。一些工作使用固定密钥调度策略,而其他工作则提出基于启发式策略的自适应密钥调度方法,这两种方法都可能导致不理想的全局性能。为了克服这一局限性,我们建议将动态视频分割中的在线关键决策过程建模为深层强化学习问题,并从关于决策历史的专家信息和最大化全球回报的过程中学习有效和有效的调度策略。此外,我们研究了动态视频分割在面部视频中的应用,这是一个以前没有被研究过的领域。通过对300VW数据集的评估,我们证明了我们的强化密钥调度器的性能优于各种基线方法的性能,并且我们的方法也可以实现实时处理速度。据我们所知,这是在动态视频分割中使用强化学习进行在线关键帧决策的第一项工作,也是在面部视频上应用的第一项工作。 |
| Lane Detection and Classification using Cascaded CNNs Authors Fabio Pizzati, Marco Allodi, Alejandro Barrera, Fernando Garc a 车道检测对于自动驾驶车辆非常重要。出于这个原因,许多方法使用车道边界信息来定位街道内的车辆,或者集成基于GPS的定位。与许多其他基于计算机视觉的任务一样,卷积神经网络CNN代表了识别车道边界的现有技术。但是,车道边界的位置是w.r.t.车辆可能不足以进行可靠的定位,因为也可能需要路径规划或关于车道类型的定位信息。在这项工作中,我们提出了一个基于两个级联神经网络的实时运行的车道边界识别,聚类和分类的端到端系统。为了构建系统,使用8个不同的类标记了用于车道检测的TuSimple数据集的14336个车道边界实例。我们的数据集和推理代码可在线获取。 |
| Semi-Bagging Based Deep Neural Architecture to Extract Text from High Entropy Images Authors Pranay Dugar, Anirban Chatterjee, Rajesh Shreedhar Bhat, Saswata Sahoo 从包含多个对象的图像中提取各种大小和形状的文本是许多情况下的重要问题,尤其是与电子商务,自然场景中的增强现实辅助系统等相关的。仅基于CNN的现有作品通常在最佳时执行次优。图像包含具有多个对象的高熵区域。本文提出了一种端到端文本检测策略,该策略结合了分割算法和不同类型的多个文本检测器的集合,以独立地检测每个单独图像片段中的文本。所提出的策略涉及基于超像素的图像分割器,其将图像分成多个区域。开发了一种卷积深度神经结构,它可以在每个分段上工作,并检测多种形状,大小和结构的文本。它在检测图像中的文本的覆盖范围方面优于竞争方法,尤其是在不同类型和大小的文本与各种其他对象一起在小区域中被压缩的方法。此外,所提出的文本检测方法连同文本识别器在从高熵图像中提取文本方面优于现有技术方法。我们在电子商务网站上的产品图像数据集上验证结果。 |
| An Analysis of Deep Neural Networks with Attention for Action Recognition from a Neurophysiological Perspective Authors Swathikiran Sudhakaran, Oswald Lanz 我们回顾了最近基于深度学习的三种动作识别方法,并从神经生理学的角度对这些方法进行了简要的比较分析。我们假设在三种呈现的基于深度学习的方法和一些关于人类大脑功能的现有假设之间存在一些类比。 |
| Improving the generalizability of convolutional neural network-based segmentation on CMR images Authors Chen Chen, Wenjia Bai, Rhodri H. Davies, Anish N. Bhuva, Charlotte Manisty, James C. Moon, Nay Aung, Aaron M. Lee, Mihir M. Sanghvi, Kenneth Fung, Jose Miguel Paiva, Steffen E. Petersen, Elena Lukaschuk, Stefan K. Piechnik, Stefan Neubauer, Daniel Rueckert 卷积神经网络基于CNN的分割方法为临床医生评估心脏MR图像中心脏的结构和功能提供了一种有效且自动化的方式。虽然当训练和测试图像来自同一域时,CNN通常可以高精度地执行分割任务,例如,相同的扫描仪或站点,它们的性能通常会在来自不同扫描仪或临床站点的图像上显着降低。我们提出了一种简单而有效的方法,通过精心设计数据规范化和增强策略来提高网络泛化能力,以适应多站点,多扫描仪临床成像数据集中的常见场景。我们证明,在英国生物银行的单一站点单扫描仪数据集上训练的神经网络可以成功应用于跨不同站点和不同扫描仪分割心脏MR图像,而不会显着降低精度。具体而言,该方法在来自英国生物银行的大量3,975名受试者中进行了训练。然后在来自英国生物银行的600个不同受试者上进行域内测试,另外两个用于交叉域测试ACDC数据集100个受试者,1个站点,2个扫描仪和BSCMR AS数据集599个受试者,6个站点,9个扫描仪。所提出的方法在UK Biobank测试集上产生有希望的分割结果,其与文献中先前报道的值相当,同时在跨域测试集上也表现良好,实现左心室的平均Dice度量为0.90,心肌为0.81。 ACDC数据集上的右心室为0.82,左心室为0.89,BSCMR AS数据集上的心肌为0.83。所提出的方法提供了一种潜在的解决方案,以改善基于CNN的模型对于交叉扫描仪和跨站点心脏MR图像分割任务的概括性。 |
| TedEval: A Fair Evaluation Metric for Scene Text Detectors Authors Chae Young Lee, Youngmin Baek, Hwalsuk Lee 尽管最近成功的场景文本检测方法,但是共同的评估度量未能在检测器之间提供公平和可靠的比较。它们在反映文本检测任务的固有特征方面具有明显的缺点,无法解决诸如粒度,多线和字符不完整之类的问题。在本文中,我们提出了一种名为TedEval Text detector Evaluation的新型评估协议,它通过实例级别匹配和字符级别评分来评估文本检测。基于可以成功识别的坚定标准奖励行为,TedEval可以作为比较和量化所有难度级别的检测质量的可靠标准。在这方面,我们相信TedEval可以在开发最先进的场景文本检测器中发挥关键作用。该代码可在以下网站公开获取 |
| Proposal, Tracking and Segmentation (PTS): A Cascaded Network for Video Object Segmentation Authors Qiang Zhou, Zilong Huang, Xinggang Wang, Yongchao Gong, Han Shen, Lichao Huang, Chang Huang, Wenyu Liu 视频对象分割VOS旨在仅在给定第一帧中的注释的情况下进行像素级对象跟踪。由于视频中物体的视觉变化很大,而且缺乏训练样本,尽管深度学习的发展正在蓬勃发展,但仍然是一项艰巨的任务。为了解决VOS问题,我们通过提议的统一框架引入了几个新的见解,该框架由对象提议,跟踪和分段组件组成。对象提议网络将对象性信息作为通用知识传送到VOS中,跟踪网络从提议中识别目标对象,并且基于跟踪结果利用新颖的基于动态参考的模型自适应方案来执行分割网络。在DAVIS 17数据集和YouTube VOS数据集上进行了大量实验,我们的方法在几个视频对象分割基准上实现了最先进的性能。我们公开提供代码 |
| Inverse Attention Guided Deep Crowd Counting Network Authors Vishwanath A. Sindagi, Vishal M. Patel 在本文中,我们解决了拥挤场景中人群计数的挑战性问题。具体而言,我们提出反向注意引导深度人群计数网络IA DCCN,其通过反向关注机制有效地将分段信息注入到计数网络中,从而导致显着的改进。所提出的方法基于VGG 16,是一步训练框架,易于实施。分段信息的使用导致最小的计算开销,并且不需要任何额外的注释。我们通过详细的分析和消融研究证明了分割引导反向注意的重要性。此外,所提出的方法在三个具有挑战性的人群计数数据集上进行评估,并且显示出对几种最近的方法实现了显着的改进 |
| Generative Guiding Block: Synthesizing Realistic Looking Variants Capable of Even Large Change Demands Authors Minho Park, Hak Gu Kim, Yong Man Ro 逼真的图像合成是生成在感知上与实际图像无法区分的图像。然而,生成具有大变化的实际外观图像(例如,大的空间变形和大的姿势变化)是非常具有挑战性的。在逼真的图像生成中需要考虑处理大的变化以及保留外观。在本文中,我们提出了一种新颖的逼真的图像合成方法,特别是在大的变化需求。为此,我们设计了生成性指导块。所提出的生成引导块包括逼真的外观保持鉴别器和自然变化转换鉴别器。通过将所提出的生成引导块纳入生成模型,增强了生成模型层的潜在特征,以合成逼真的目标和目标变异图像。通过实验中的定性和定量评估,我们证明了与现有技术相比,所提出的生成引导块的有效性。 |
| Multi-Cue Vehicle Detection for Semantic Video Compression In Georegistered Aerial Videos Authors Noor Al Shakarji, Filiz Bunyak, Hadi Aliakbarpour, Guna Seetharaman, Kannappan Palaniappan 从机载相机获取的视频中检测诸如车辆之类的移动物体对于视频分析应用非常有用。使用用于车载移动物体检测的快速低功率算法还将为场景内容识别图像压缩提供基于感兴趣区域的语义信息。这将在低带宽机载云计算网络中实现更有效和灵活的通信链路利用。尽管最近在无人机或无人机平台和成像传感器技术方面取得了进展,但由于物体尺寸小,平台运动和相机抖动,遮挡,场景复杂性和成像条件恶化,航拍视频的车辆检测仍然具有挑战性。本文提出了一种高效的移动车辆检测管道,它利用深度学习结合通量张量空间时间滤波,以互补的方式协同融合外观和基于运动的检测。我们提出的多线索管道能够通过智能融合检测高精度和回忆的移动车辆,同时滤除诸如停放车辆等误报。实验结果表明,结合移动车辆的上下文信息可以实现超过100 1的高语义压缩比和高图像保真度,以更好地利用有限带宽空中对地网络链路。 |
| Procedure Planning in Instructional Videos Authors Chien Yi Chang, De An Huang, Danfei Xu, Ehsan Adeli, Li Fei Fei, Juan Carlos Niebles 我们在教学视频中提出了一个新的具有挑战性的任务程序。与现有的规划问题不同,状态和动作空间都被很好地定义,教学视频中规划的关键挑战是状态和动作空间都是开放的词汇。我们通过潜在的空间规划来解决这一挑战,我们建议明确利用状态和行动在学习的可计划潜在空间中的共轭关系所施加的约束。我们评估大规模现实世界教学视频的程序规划和演练计划。我们的实验表明,我们能够在没有明确监督的情况下学习可计划的语义表示。这使得能够对现实世界视频进行顺序推理,并且与现有规划方法和神经网络策略相比,可以实现更强的泛化。 |
| Multi-scale Template Matching with Scalable Diversity Similarity in an Unconstrained Environment Authors Yi Zhang, Chao Zhang, Takuya Akashi 我们提出了一种新颖的多尺度模板匹配方法,该方法对于无约束环境中的缩放和旋转都是鲁棒的。背后的关键组成部分是称为可扩展多样性相似性SDS的相似性度量。具体而言,SDS利用两组点之间的最近邻NN匹配的双向多样性。为了解决相似性度量的尺度稳健性,将局部外观和等级信息联合用于NN搜索。此外,通过在比例变化上引入惩罚项,并将极半径项引入相似性度量,SDS显示出对整体尺寸和旋转变化以及非刚性几何变形,背景杂波和遮挡的良好性能相似性度量。 。 SDS的性质在统计学上是合理的,并且对合成和现实世界数据的实验表明SDS可以明显优于现有技术方法。 |
| +++Disentangled Makeup Transfer with Generative Adversarial Network Authors Honglun Zhang, Wenqing Chen, Hao He, Yaohui Jin 面部化妆转移是一种广泛使用的技术,旨在将化妆风格从参考面部图像转移到非化妆面部。现有文献利用对抗性损失,使得生成的面具有高质量和真实的面貌,但只能产生固定的输出。受到解缠表现的最新进展的启发,在本文中,我们提出了DMT解缠化妆转移,一种统一的生成对抗网络,以实现不同的化妆转移场景。我们的模型包含一个身份编码器和一个化妆编码器,可以解开任意面部图像的个人身份和化妆风格。基于两个编码器的输出,采用解码器来重建原始面部。我们还应用鉴别器来区分真实面孔和假面孔。因此,我们的模型不仅可以将化妆风格从一个或多个参考面部图像转移到具有可控强度的非化妆面部,而且还可以生成具有从先前分布采样的样式的各种输出。大量实验表明,我们的模型优于现有文献,通过为不同的化妆品转移场景生成高质量的结果。 |
| High-speed Railway Fastener Detection and Localization System Authors Qing Song, Yao Guo, Lu Yang, Jianan Jiang, Chun Liu, Mengjie Hu 铁路运输是中国国民经济的动脉,在当今社会的发展中起着重要作用。由于中国铁路安全检查技术起步较晚,目前的铁路安全检查任务主要依靠人工检查,但人工检查效率低,需要大量的人力物力。在本文中,我们建立了钢轨紧固件检测图像数据集,其中包含4种类型的4,000个轨道紧固件图片。我们使用区域建议网络来生成感兴趣的区域,使用卷积神经网络提取特征,并将分类器融合到检测网络中。通过在线硬样本挖掘来提高模型的准确性,我们通过减少感兴趣区域的数量来优化更快的RCNN检测框架。最后,在TITAN X GPU的部署环境中,模型精度达到99,速度达到35FPS。 |
| Learnable Gated Temporal Shift Module for Deep Video Inpainting Authors Ya Liang Chang, Zhe Yu Liu, Kuan Ying Lee, Winston Hsu 如何有效地利用时态信息以一致的方式恢复视频是视频修复问题的主要问题。传统的2D CNN在图像修复方面取得了良好的性能,但往往导致时间上不一致的结果,当应用于视频时帧会闪烁 |
| Language2Pose: Natural Language Grounded Pose Forecasting Authors Chaitanya Ahuja, Louis Philippe Morency 从自然语言句子生成动画可以在许多领域中应用,例如电影脚本可视化,虚拟人体动画和机器人运动规划。这些句子可以描述这些动作的不同类型的动作,速度和方向,并且可能描述目标目的地。这种语言构成应用的核心建模挑战是如何将语言概念映射到运动动画。 |
| Nature Inspired Dimensional Reduction Technique for Fast and Invariant Visual Feature Extraction Authors Ravimal Bandara, Lochandaka Ranathunga, Nor Aniza Abdullah 在某些计算机视觉应用中,快速且不变的特征提取是至关重要的,其中计算时间在分类器的训练和测试阶段受到限制。在本文中,我们提出了一种自然启发的降维技术,用于快速和不变的视觉特征提取。人脑可以交换空间和光谱分辨率以重建视觉感知中的缺失颜色。该现象在印刷工业中被广泛用于通过称为颜色抖动的技术来减少用于印刷的颜色的数量。在这项工作中,我们采用快速误差扩散颜色抖动算法,通过采用新的Hessian矩阵分析技术降低光谱分辨率并提取显着特征,然后由空间色彩直方图描述。与几种不同的手工制作和深度学习特征相比,在对象的方向,视角和光照的极大变化下评估所提出特征的计算时间,描述符维度和分类性能。在桌面PC和Raspberry Pi设备上进行的两个公开可用的对象数据集,线圈100和ALOI的广泛实验显示了使用所提出的方法的多个优点,例如较低的计算时间,高鲁棒性和在弱监督下的可比分类精度环境。此外,它显示了仅利用一小部分可用硬件资源在传统SoC器件内部工作的能力。 |
| +++Multiview Aggregation for Learning Category-Specific Shape Reconstruction Authors Srinath Sridhar, Davis Rempe, Julien Valentin, Sofien Bouaziz, Leonidas J. Guibas 我们研究了从先前未观察到的对象实例的可变数量的RGB视图中学习类别特定的3D表面形状重建的问题。用于多视图形状重建的大多数方法在稀疏形状表示上操作,或者假设固定数量的视图。我们提出了一种方法,可以估计密集的3D形状,并在多个和不同数量的输入视图中聚合形状。给定对象实例的单个输入视图,我们提出了一种表示,其编码可见对象表面部分的密集形状以及视线后面的表面并被可见表面遮挡。当多个输入视图可用时,形状表示被设计为使用非常小的并集操作聚合成单个3D形状。我们训练2D CNN以学习从可变数量的视图1或更多视图预测该表示。我们通过使用在特征级别促进顺序不可知视图信息交换的排列等变层来进一步聚合多视图信息。实验表明,我们的方法能够生成对象的密集重建,并且能够在添加更多视图时产生更好的结果。 |
| DeepTEGINN: Deep Learning Based Tools to Extract Graphs from Images of Neural Networks Authors Gustavo Borges Moreno e Mello, Vibeke Devold Valderhaug, Sidney Pontes Filho, Evi Zouganeli, Ioanna Sandvig, Stefano Nichele 在大脑中,神经元网络的结构定义了这些神经元如何实现作为思想基础的计算以及动物和人类的行为。如果我们可以将神经元网络描述为图形,我们可以使用图论的方法来研究其结构或使用细胞自动机来数学评估其功能。虽然,用于分析图形和细胞自动机的软件可广泛使用。从脑细胞网络图像中提取图形仍然很困难。神经组织是异质的,解剖学上的差异可能反映了功能的相关差异。在这里,我们介绍一个基于深度学习的工具箱,从脑组织的图像中提取图形。该工具箱提供了一个易于使用的框架,允许系统神经科学家通过结合图像处理,深度学习和图论的方法,基于脑组织图像生成图形。目标是简化计算机视觉深度学习方法的培训和使用,并促进其集成到图形提取管道中。通过这种方式,工具箱提供了所需的繁重的跟踪,排序和分类手动过程的替代方案。我们期望将机器学习方法民主化到计算机视觉专家之外的更广泛的用户群体,并提高从大脑图像数据集中提取图形的时间效率,这可以导致对人类思维的进一步理解。 |
| Associative Embedding for Game-Agnostic Team Discrimination Authors Maxime Istasse, Julien Moreau, Christophe De Vleeschouwer 在没有事先知道每个团队的视觉外观时,为体育比赛中的球员分配球队标签并不是一项微不足道的任务。我们的工作建立在卷积神经网络CNN上以学习描述符,即像素智能嵌入向量,对于描绘来自同一团队的玩家的像素类似,并且当像素对应于不同的团队时不同。这个想法的优点是不需要每场比赛学习,一旦比赛开始就允许有效的球队歧视。原则上,该方法遵循引入的关联嵌入框架 |
| Learning to aggregate feature representations Authors Guy Gaziv 阿尔戈英雄的挑战需要构建一个多目标图像编码器到大脑活动信号。已知训练用于图像分类的诸如ResNet 50和AlexNet的深度网络沿其中间阶段产生特征表示,其近似地模仿视觉层级。然而,Algonauts项目中引入的挑战,包括组合来自多个主题的数据,依赖极少的相似性数据点,求解各种ROI以及多模态,需要设计一个可以有效适应这一点的灵活框架。这里,我们建立在最近的现有技术分类网络SE ResNeXt 50上,并构建其中间表示的自适应组合。虽然预训练网络是我们模型的支柱,但我们还是学习如何在网络的五个阶段聚合特征表示。在学习过程中,我们的构造能够调整和筛选网络中每个阶段的输出,并由优化的目标控制。我们将我们的方法应用于Algonauts2019 fMRI和MEG挑战。使用组合的fMRI和MEG数据,我们的方法被评为两项挑战的前五名。令人惊讶的是,我们发现对于低阶和高阶区域EVC和IT,自适应聚合有利于在网络后期产生的特征。 |
| Diminishing the Effect of Adversarial Perturbations via Refining Feature Representation Authors Nader Asadi, AmirMohammad Sarfi, Sahba Tahsini, Mahdi Eftekhari 深度神经网络极易受到对抗性示例的影响,这对这些最先进的模型带来了严重的安全问题。已经提出了许多防御方法来缓解这个问题。但是,他们中的很多人依赖于对目标模型的修改或额外培训。在这项工作中,我们分析研究非扰动和扰动图像的每一层表示,并显示扰动对这些表示中的每一个的影响。因此,提出了一种基于白化着色变换的方法,以减少由对手引起的任何期望层的误表示。我们的方法可以应用于任意模型的任何层,无需任何修改或额外的培训。由于层表示的完全白化不容易区分,我们提出的方法对于白盒攻击具有极强的鲁棒性。此外,我们展示了我们的方法对一些最先进的黑盒攻击的强度,如Carlini Wagner L2攻击,我们表明我们的方法能够抵御一些非约束攻击。 |
| Symmetry Detection and Classification in Drawings of Graphs Authors Felice De Luca, Md Iqbal Hossain, Stephen Kobourov 对称性是自然界中从花朵和叶子,蝴蝶和鸟类以及从绘画和雕塑到制造物品和建筑设计的人造物体中观察到的关键特征。旋转,平移,尤其是反射对称,在图的绘图中也很重要。在旨在创建对称图形绘图的算法中,检测和分类对称性非常有用,在本文中,我们为这些任务提供了机器学习方法。具体来说,我们表明深度神经网络可用于检测92精度的反射对称性。我们还构建了一个多类分类器,以区分反射水平,反射垂直,旋转和平移对称。最后,我们提供了具有特定对称特征的图形图像集合,这些图形可以在机器学习系统中用于培训,测试和验证目的。我们的数据集,训练有素的ML模型,源代码可在线获取。 |
| Method of diagnosing heart disease based on deep learning ECG signal Authors Jie Zhang, Bohao Li, Kexin Xiang, Xuegang Shi 心电信号诊断心脏病的传统方法是人工观察。一些人试图将专业知识和信号处理结合起来,按心脏病类型对心电信号进行分类。但是,货币不足以在医疗应用中使用。我们开发了一种算法,它结合了信号处理和深度学习,将心电信号分类为普通AF其他节律和噪声,这有助于我们解决这个问题。通过小波变换证明我们可以获得心电信号的时频图,并利用DNN对时频图进行分类,找出信号采集器可能具有的心脏病。总体而言,验证集的准确率达到94%。根据2017年心脏病学CinC的PhysioNet Computing评估标准,该方法的F1得分为0.957,高于2017年的第一名。 |
| Speaker-independent classification of phonetic segments from raw ultrasound in child speech Authors Manuel Sam Ribeiro, Aciel Eshky, Korin Richmond, Steve Renals 超声舌头成像UTI提供了在语音产生期间可视化声道的便利方式。 UTI越来越多地用于语言治疗,因此开发自动方法以帮助当前由语言治疗师执行的各种耗时的手动任务变得很重要。一个关键的挑战是将超声舌象的自动处理推广到以前看不见的扬声器。在这项工作中,我们研究了在原始超声波记录下的语音片段舌形的分类,在几种训练场景下依赖于说话者,多个说话者,说话者独立和说话者适应。我们观察到模型在应用于训练时未见的扬声器数据时表现不佳。然而,当提供最小的附加扬声器信息(例如平均超声帧)时,模型更好地概括为看不见的扬声器。 |
| Bayesian Optimization on Large Graphs via a Graph Convolutional Generative Model: Application in Cardiac Model Personalization Authors Jwala Dhamala, Sandesh Ghimire, John L. Sapp, B. Milan Horacek, Linwei Wang 心脏模型的个性化涉及器官组织特性的优化,其在心脏的非欧几里德几何模型上在空间上变化。为了表示组织特性的高维HD未知,大多数现有工作依赖于几何模型的低维LD分区。虽然这会利用心脏的几何形状,但它具有有限的表现力,允许分区足够小以进行有效优化。最近,变分自动编码器VAE被用作更具表现力的生成模型,以将HD优化嵌入到LD潜在空间中。然而,它的欧几里德性质忽略了内心丰富的几何信息。在本文中,我们提出了一种新的图卷积VAE,允许非欧几里德数据的生成建模,并利用它将大图的贝叶斯优化嵌入到一个小的潜在空间。这种方法通过引入表达生成模型来弥补先前作品的差距,该模型能够结合基础几何的空间接近度和层次组成性的知识。它还允许跨不同几何形状传递学习特征,这对于常规VAE是不可能的。我们在心脏电生理模型中估计组织兴奋性的合成和实际数据实验中证明了所提出方法的这些益处。 |
| Dual Network Architecture for Few-view CT --Trained on ImageNet Data and Transferred for Medical Imaging Authors Huidong Xie, Hongming Shan, Wenxiang Cong, Xiaohua Zhang, Shaohua Liu, Ruola Ning, Ge Wang X射线计算机断层扫描CT从投影数据重建横截面图像。然而,与CT扫描相关的电离X射线辐射可能诱发癌症和遗传损伤并引起公众关注,并且辐射剂量的减少引起了人们的极大关注。很少有人观察CT图像重建是减少辐射剂量的重要课题。最近,数据驱动算法已经显示出解决少数视图CT问题的巨大潜力。在本文中,我们开发了一种双网络架构DNA,用于直接从正弦图重建图像。在所提出的DNA方法中,基于点的完全连接层学习反投影处理,其请求比现有技术显着更少的存储器并且使用O C N N c参数,其中N和N c分别表示重建图像的维度和投影数量。 C是一个可调节的参数,可以设置为低至1.我们的实验结果表明,DNA比其他最先进的方法产生了竞争性。有趣的是,当真实患者图像的数量有限时,自然图像可用于预训练DNA以避免过度拟合。 |
| Kite: Automatic speech recognition for unmanned aerial vehicles Authors Dan Oneata, Horia Cucu 本文讨论了构建适应无人机无人机控制的语音识别系统的问题。尽管无人机正在普及,但为他们创建语音接口的任务基本上没有得到解决。为此,我们为无人机控制引入了多模态评估数据集,包括口头命令和相关图像,它们代表了飞行员发出命令时无人机所看到的视觉背景。我们提供了基线结果并解决了两个研究方向:语言模型的稳健程度,在列车时间给出一个不完整的命令列表,如何将视觉信息纳入语言模型。我们发现循环神经网络RNN是两个任务的解决方案,它们可以使用少量命令成功调整,并且可以扩展为使用视觉线索。我们的结果表明,即使命令图像训练关联是自动生成的并且固有地不完美,基于图像的RNN也优于其仅文本对应物。数据集和我们的代码可在以下位置获得 |
| Robust Tensor Completion Using Transformed Tensor SVD Authors Guangjing Song, Michael K. Ng, Xiongjun Zhang 在本文中,我们使用变换张量奇异值分解SVD研究鲁棒张量完成,它采用酉变换矩阵代替传统张量SVD中使用的离散傅立叶变换矩阵。主要动机是通过使用其他酉变换矩阵可以获得比使用离散傅立叶变换矩阵更低的输入等级张量。这对于稳健的张量完成更有效。高光谱,视频和人脸数据集的实验结果表明,使用变换张量SVD的鲁棒张量完成问题的恢复性能在PSNR中比使用傅里叶变换和其他鲁棒张量完成方法更好。 |
| Accurate, reliable and fast robustness evaluation Authors Wieland Brendel, Jonas Rauber, Matthias K mmerer, Ivan Ustyuzhaninov, Matthias Bethge 在过去五年中,神经网络对最小对抗性扰动的敏感性已从一种特殊现象转变为深度学习中的核心问题。然而,尽管受到很多关注,但由于难以评估神经网络模型的稳健性,因此对更强大模型的进展显着受损。今天的方法是基于快速但脆弱的梯度攻击,或者它们相当可靠但是得分和基于决策的攻击速度慢。我们在这里开发了一套新的基于梯度的对抗性攻击,在面对梯度掩蔽时比其他基于梯度的攻击更可靠,b表现更好,并且比现有的基于梯度的攻击更具查询效率,c可以灵活适应各种各样的敌对标准,d几乎不需要超参数调整。这些研究结果经过多种六种不同模型的精心验证,在有针对性和无目标情景下都能保持L2和L无穷大。实施将在所有主要工具箱Foolbox,CleverHans和ART中提供。此外,我们将很快添加其他内容和实验,包括我们攻击的L0和L1版本,以及与其他L2和L无限攻击的其他比较。我们希望这类攻击能够使稳健性评估更容易,更可靠,从而在寻找更强大的机器学习模型时提供更多信号。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
makeup
pic from pexels.com