Pytorch 学习笔记:迁移学习使用VGG16进行kaggle 猫狗分类
kaggle上猫狗分类网址: https://www.kaggle.com/c/dogs-vs-cats
1.数据部分
分类工作的第一步是准确数据,从kaggle上面下载的dogs-vs-cats数据包含3个文件train.zip,test.zip和sample_submission.csv
train.zip里面共25000张图片,猫狗各12500张,名称格式为:XXX.YYYYY.jpg。其中XXX为cat或者dog,YYYYY为0到12499;示例如下:cat.0.jpg。
test.zip里面共12500张图片,名称格式为:YYYYY.jpg。里面既有猫又有狗,顺序是乱的。
sample_submission.csv是往kaggle网站上提交结果用的文件示例,文件包含两栏:id和label。
2.模型部分
把train.zip解压得到的图片分为两部分放到两个文件夹中,train分配20000张(猫狗各10000张),val分配5000张(猫狗各2500张),dog和cat图片也分别放到不同文件夹中方便会面使用Pytorch的API。
文件路径如下:

把数据分成两部分的代码
import os
# print(os.popen("dir").read())
for i in range(10000,12500,1):
str1 = r"D:\datasets\dogs-vs-cats-redux-kernels-edition\202005\train\dog"
str2 = r"D:\datasets\dogs-vs-cats-redux-kernels-edition\202005\valid\dog"
command_tmp = "move {}\dog.{}.jpg {}\dog.{}.jpg".format(str1, i, str2, i)
print(os.system(command_tmp))
for i in range(10000,12500,1):
str1 = r"D:\datasets\dogs-vs-cats-redux-kernels-edition\202005\train\cat"
str2 = r"D:\datasets\dogs-vs-cats-redux-kernels-edition\202005\valid\cat"
command_tmp = "move {}\cat.{}.jpg {}\cat.{}.jpg".format(str1, i, str2, i)
print(os.system(command_tmp))训练代码
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch import optim
import matplotlib.pyplot as plt
import time
import os
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomAffine(degrees=15, scale=(0.8,1.5)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
trainset = torchvision.datasets.ImageFolder(root='D:/datasets/dogs-vs-cats-redux-kernels-edition/202005/train/', transform=train_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=8, shuffle=True, num_workers=6)
valset = torchvision.datasets.ImageFolder(root='D:/datasets/dogs-vs-cats-redux-kernels-edition/202005/valid/', transform=val_transform)
valloader = torch.utils.data.DataLoader(valset, batch_size=8, shuffle=True, num_workers=6)
print(len(trainloader))
print(len(valloader))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = torchvision.models.vgg16(pretrained=True).cuda()
print(model)
for param in model.features.parameters(): param.requires_grad = False
model.classifier[6].out_features = 2
print(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.classifier.parameters(), lr=0.0001, momentum=0.5)
# train_losses, train_accuracy = [], []
# val_losses, val_accuracy = [], []
#保存每个epoch后的Accuracy Loss Val_Accuracy
Accuracy = []
Loss = []
Val_Accuracy = []
BEST_VAL_ACC = 0.
#训练
since = time.time()
for epoch in range(10):
train_loss = 0.
train_accuracy = 0.
run_accuracy = 0.
run_loss = 0.
total = 0.
model.train()
for i, (images, labels) in enumerate(trainloader, 0):
images = images.to(device)
labels = labels.to(device)
# 经典4步
optimizer.zero_grad()
outs = model(images)
loss = criterion(outs, labels)
loss.backward()
optimizer.step()
# 输出状态
total += labels.size(0)
run_loss += loss.item()
_,prediction = torch.max(outs,1)
run_accuracy += (prediction == labels).sum().item()
if i % 20 == 19:
print('epoch {}, iter{},train accuracy:{:4f}% loss: {:.4f}'.format(epoch, i+1, 100*run_accuracy/(labels.size(0)*20), run_loss/20))
train_accuracy += run_accuracy
train_loss += run_loss
run_accuracy, run_loss = 0., 0.
Loss.append(train_loss/total)
Accuracy.append(100*train_accuracy/total)
#可视化训练过程
fig1, ax1 = plt.subplots(figsize=(11, 8))
ax1.plot(range(0, epoch+1, 1), Accuracy)
ax1.set_title("Average trainset accuracy vs epochs")
ax1.set_xlabel("Epoch")
ax1.set_ylabel("Avg. train. accuracy")
plt.savefig('Train_accuracy_vs_epochs.png')
plt.clf()
plt.close()
fig2, ax2 = plt.subplots(figsize=(11,8))
ax2.plot(range(epoch+1), Loss)
ax2.set_title("Average trainset loss vs epochs")
ax2.set_xlabel("Epoch")
ax2.set_ylabel("Current loss")
plt.savefig('loss_vs_epochs.png')
plt.clf()
plt.close()
# 验证
acc = 0.
model.eval()
print('waitting for val...')
with torch.no_grad():
accuracy = 0.
total = 0
for (images,labels) in valloader:
images = images.to(device)
labels = labels.to(device)
out = model(images)
_, prediction = torch.max(out,1)
total += labels.size(0)
accuracy += (prediction == labels).sum().item()
acc = 100.*accuracy/total
print('epoch {} The ValSet accuracy is {:.4f}% \n'.format(epoch, acc))
Val_Accuracy.append(acc)
if acc > BEST_VAL_ACC:
print('Find Better Model and Saving it...')
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(model.state_dict(), './checkpoint/VGG19_Cats_Dogs_hc.pth')
BEST_VAL_ACC = acc
print('Saved!')
fig3, ax3 = plt.subplots(figsize=(11, 8))
ax3.plot(range(epoch+1),Val_Accuracy )
ax3.set_title("Average Val accuracy vs epochs")
ax3.set_xlabel("Epoch")
ax3.set_ylabel("Current Val accuracy")
plt.savefig('val_accuracy_vs_epoch.png')
plt.close()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed%60))
print('Now the best val Acc is {:.4f}%'.format(BEST_VAL_ACC))
生成测试结果代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision
import numpy as np
from tqdm import tqdm_notebook as tqdm
from PIL import Image
import os
import pandas as pd
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载模型
model = torchvision.models.vgg16(pretrained=False)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model.to(device)
model.load_state_dict(torch.load('./checkpoint/VGG19_Cats_Dogs_hc.pth'))
# 测试
id_list = []
pred_list = []
test_path = 'D:/datasets/dogs-vs-cats-redux-kernels-edition/202005/test/'
test_files = os.listdir(test_path)
model.eval()
with torch.no_grad():
for file in tqdm(test_files):
img = Image.open(test_path+file)
_id = int(file.split('.')[0])
img = transform(img)
img = img.unsqueeze(0)
img = img.to(device)
out = model(img)
# print(out)
prediction = F.softmax(out, dim=1)[:,1].tolist()
_predict = np.array(prediction)
# _predict = np.where(_predict>0.5, 1, 0)
# print(_id, _predict[0])
id_list.append(_id)
pred_list.append(_predict.item())
res = pd.DataFrame({
'id':id_list,
'label':pred_list
})
res.sort_values(by='id', inplace=True)
res.reset_index(drop=True, inplace=True)
res.to_csv('submission.csv', index=False)
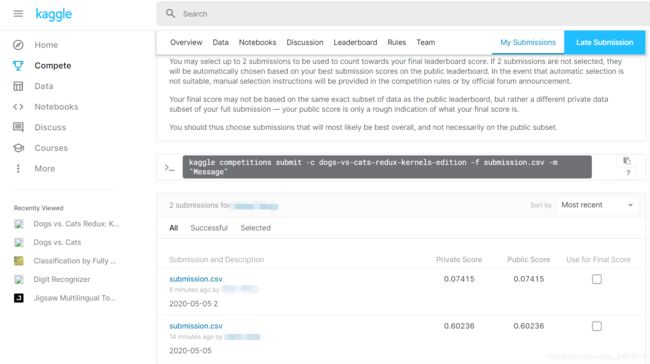
在kaggle上面提交了两次结果
测试结果提交地址:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/submit
参考文献:
https://blog.csdn.net/qq_36560894/article/details/104923543