pandas中的数据运算与算数运算
pandas中的数据运算与算数运算
一,DataFrame中的算数运算
对于DataFrame,对其会同时发生在行和列上,两个DataFrame对象相加后,其索引行和列会取并集,当一个对象中某轴标签在另一个对象上找不到时,会返回NaN.可使用add方法传入特殊值.add(加法),sub(减法),div(除法),mul(乘法)
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
from numpy import nan#导入相应模块
#插入数据
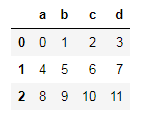
df1 = DataFrame(np.arange(12).reshape((3,4)),columns=list("abcd"))
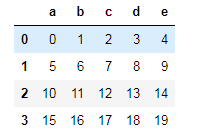
df2 = DataFrame(np.arange(20).reshape((4,5)),columns=list("abcde"))
df1
df2
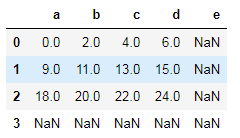
df1+df2#df1.add(df2)
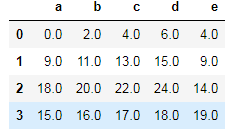
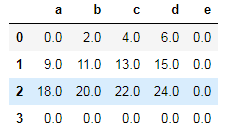
df1.add(df2,fill_value=0)# 为df1添加第3行和e这一列,并将其填充为0
df1.add(df2).fillna(0)# 按照正常方式将df1和df2相加,然后将NaN值填充为0结果如下:
二,DataFrame与Series之间的运算
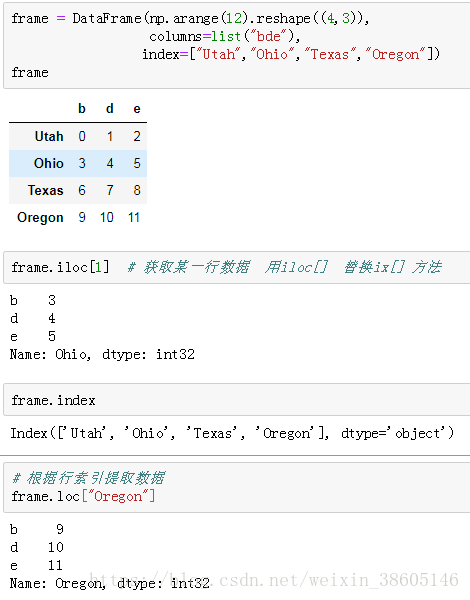
frame = DataFrame(np.arange(12).reshape((4,3)),columns=list("bde"),
index=["Utah","Ohio","Texas","Oregon"])
frame
frame.iloc[1] # 获取某一行数据 用iloc[] 替换ix[] 方法
frame.index#获取索引
frame.loc["Oregon"]# 根据行索引提取数据
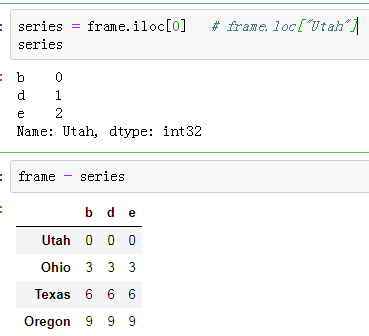
series = frame.iloc[0]
series
frame - series结果:
三,函数的应用和映射
1,用apply将一个规则应用到DataFrame的行或者列上
f = lambda x : x.max() - x.min() # 匿名函数
#def getMax(x):#创建函数的方法
#return x.max() - x.min()
# getMax(arr)
frame.apply(f) #apply 默认第二个参数 axis=0,作用于列方向上,axis=1 作用于行方向上
frame.apply(f,axis=1)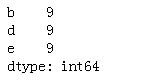

2,applymap 将一个规则应用到DataFrame中的每一个元素
frame = DataFrame(np.random.randn(12).reshape((4,3)),
columns=list("bde"),
index=["Utah","Ohio","Texas","Oregon"])
frame
# 定义一个函数,保留浮点数的两位小数
#def twoFixed(num):
#return "%.2f"%num
# 将该方法转化成匿名函数
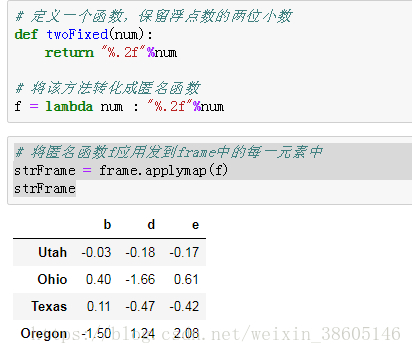
f = lambda num : "%.2f"%num
# 将匿名函数f应用到frame中的每一元素中
strFrame = frame.applymap(f)
strFrame
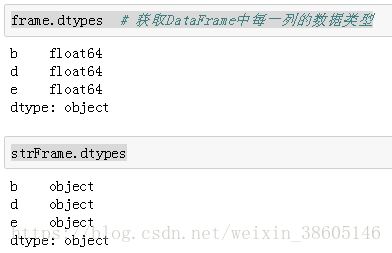
frame.dtypes # 获取DataFrame中每一列的数据类型
strFrame.dtypes
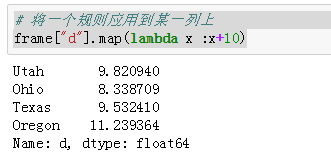
# 将一个规则应用到某一列上
frame["d"].map(lambda x :x+10)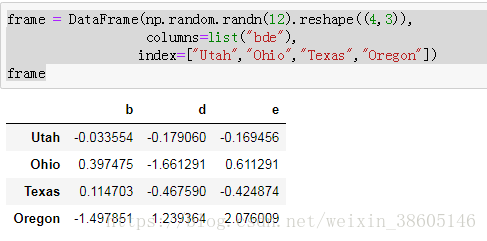
四,排序和索引
1,Series和DataFrame的排序
series = Series(range(4),
index=list("dabc"))
series
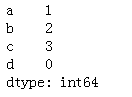
series.sort_index()#索引按字母顺序排序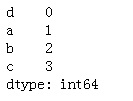
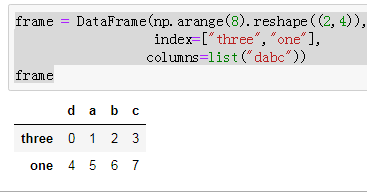
frame = DataFrame(np.arange(8).reshape((2,4)),
index=["three","one"],
columns=list("dabc"))
frame
frame.sort_index()
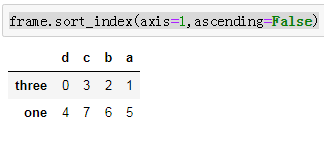
frame.sort_index(axis=1,ascending=False)
#DataFrame.sort_index(axis,ascending,by)
#axis = 0 按照行索引排序 index
#axis = 1 按照列索引排序 columns
#ascending = False 降序
#ascending = True 升序
#by 指定列名进行排序,不推荐使用

2,按照DataFrame中某一列的值进行排序
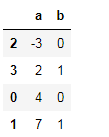
df = DataFrame({"a":[4,7,-3,2],
"b":[0,1,0,1]})
df
# 按照b这一列的数据值进行排序
df.sort_values(by="a") # 建议使用df.sort_values(by) 替换 sort_index(by) 用法
3,处理Series的重复索引
series = Series(range(5),index=list("aabbc"))
series
#结果
a 0
a 1
b 2
b 3
c 4
dtype: int64
# 判断Series的索引是否出现重复
series.index.is_unique # False 有重复的索引 True 没有重复索引
#结果
False
series["a"]
#结果
a 0
a 1
dtype: int64五,汇总计算描述统计
df = DataFrame([[1.4,nan],[7.1,-4.5],
[nan,nan],[0.75,-1.3]],
index=list("abcd"),
columns=["one","two"])
df
df.sum()
df.sum(axis=1)
'''df.sum(axis)
axis=0 按列方向求和(默认)
axis=1 按行方向求和
'''
df.mean() # 默认按照列方向求平均 axis = 0 按列 axis=1 按行
df.mean(axis=1,skipna=False) # skipna 是否省略nan值,False :不省略 True: 省略
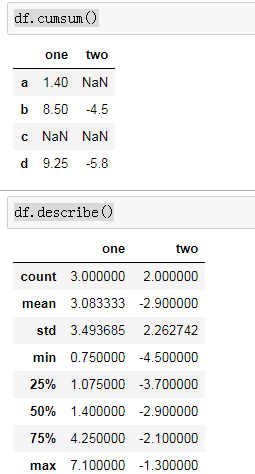
df.cumsum()
df.describe()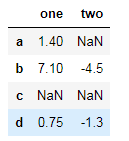


六,唯一值,值计数与成员资格
series = Series(list("aabc")*4)
series
# 获取series中去重之后的结果
series.unique()
# 统计Series中每个元素出现的次数
series.value_counts()
# 在pandas对象上也有功能相同的value_counts()方法
pd.value_counts(series.values,sort=False)结果:


mask = series.isin(["b","c"])#检验Series中的元素是否在指定集合
series[mask] # 通过花式索引筛选数据
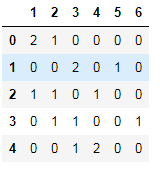
data=DataFrame({"qu1":[1,3,4,3,4],
"qu2":[2,3,1,2,3],
"qu3":[1,5,2,6,4]})
data
#统计DataFrame每一列中每个元素出现次数
data.apply(pd.value_counts,axis=1).fillna(0).astype("int")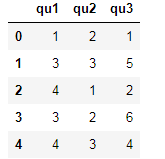
七,缺失值处理
series = Series(["a","b",nan,"c"])
series
mask = series.isnull()#判断某个序列中的元素是否为null
~mask # 取反
# 判断Series元素是否不为null
series.notnull()
# 去除序列中的缺失值
series.dropna() 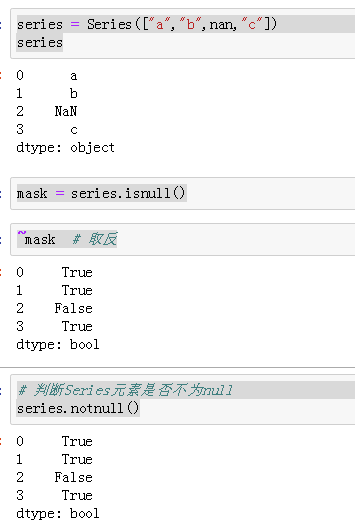

# DataFrame中的缺失值处理
data = DataFrame([[1,6.5,3,4,nan],
[1,nan,nan,5,nan],
[nan,nan,nan,6,nan],
[nan,6.5,3,7,nan]])
data
'''
DataFrame.dropna(axis,how)
axis=0
只要在一行有任意一列的值为nan,则该行被删除
axis =1
只要在一列中任意一行的值为nan,则该列被删除
how = all,。。。。
如果axis=0 只删除全为nan的行
如果axis=1 只删除全为nan的列
'''
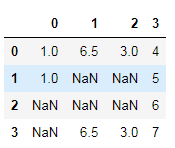
cleaned = data.dropna(axis=1)
data.dropna(axis=1,how="all")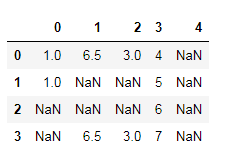

八,缺失数据填充
1,通过一个常数调用fillna会将缺失值替换为那个常数值
2,通过一个字典调用fillna,可以实现对不同列填充不同的值
3,fillna默认会返回新对象,但也可以实现对原对象的修改
#省略导包代码
df = DataFrame([[1,2,nan],
[4,nan,6],
[nan,8,9]],
index=["one","two","three"],
columns=list("abc"))
df运行结果:

# 将DataFrame中的NaN值替换为指定的值
df.fillna(0)
# 按照列的索引名称,对不同的列中的nan值填充不同的值
df.fillna({"a":0,"c":"M"})
# 替换NaN并修改原来的DataFrame
df.fillna(0,inplace=True)#为False则不改变原数据
df