Tensorflow(五)使用CNN对MNIST数据集进行分类
在tensorflow(二)中对MNIST数据集进行分类使用单层神经网络,梯度下降法以0.2的学习因子迭代了100次取得了92%的准确率,这个网络很简单,使用较大的学习因子也不会出现梯度爆炸或者梯度消失的情况,但是在复杂些的网络,比如这里用到的三层CNN网络使用0.2的学习因子就过大了。
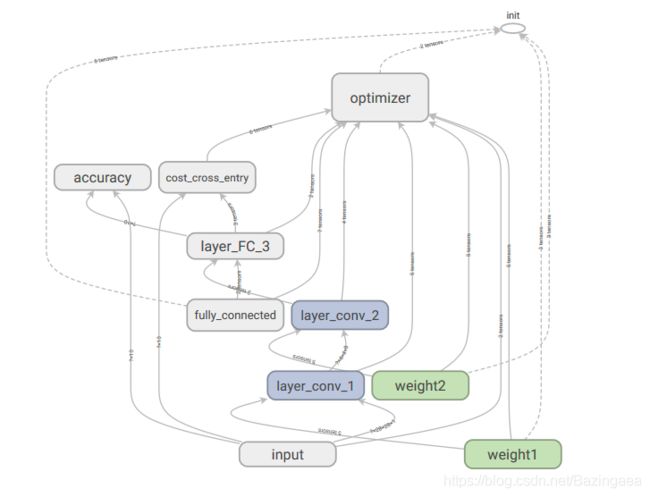
本文结合了tensorfow(三)中的卷积神经网络模型以及tensorflow(四)中的tensorboard查看方法,神经网共有三层,两个卷积层,一个全连接层,一般情况下对特征图进行卷积操作后也会进行池化操作,所以讲池化层也包含在卷积层当中,当然代码实现是分开的,只是计算神经网络的层次时将他们划分在一起,并且统称为一个卷积层。
具体的内容在前面两节中都有总结,这里就直接贴代码了,需要说明的地方会注释:
#导包
import numpy as np
import h5py
import tensorflow as tf
#MNIST数据
#需要注意的一点是,数据格式与单层神经网络不同,CNN不需要把数据整合为(m*n)的格式
#也就是CNN不需要将所有特征值都合并在一起
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data',one_hot = True)
train_x = mnist.train.images
train_y = mnist.train.labels
test_x = mnist.test.images
test_y = mnist.test.labels #(55000, 10)
train_x = train_x.reshape([-1,28,28,1]) #(55000, 28, 28, 1)
test_x = test_x.reshape([-1,28,28,1]) # (10000, 28, 28, 1)
#定义一个 变量所有summary的整合
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
#新建占位符
def create_placeholders(n_H0,n_W0,n_C0,n_y):
with tf.name_scope('input'):
X = tf.placeholder(shape=[None,n_H0,n_W0,n_C0],dtype = tf.float32,name='x_input')
Y = tf.placeholder(shape=[None,n_y],dtype = tf.float32,name='y_input')
return X,Y
#向前传播
def forward_propagation(X):
tf.set_random_seed(1)
#第一个卷积层 conv-relu-pooling
with tf.name_scope('layer_conv_1'):
with tf.name_scope('weight1'):
W1 = tf.get_variable('weight1',[4,4,1,8],initializer = tf.contrib.layers.xavier_initializer(seed = 0))
variable_summaries(W1)
with tf.name_scope('conv1'):
Z1 = tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding='SAME')
with tf.name_scope('activation_relu'):
A1 = tf.nn.relu(Z1)
with tf.name_scope('pooling1'):
P1 = tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding='SAME')
#第二个卷积层 conv-relu-pooling
with tf.name_scope('layer_conv_2'):
with tf.name_scope('weight2'):
W2 = tf.get_variable('weight2',[2,2,8,16],initializer = tf.contrib.layers.xavier_initializer(seed = 0))
variable_summaries(W2)
with tf.name_scope('conv2'):
Z2 = tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding='SAME')
with tf.name_scope('activation_relu'):
A2 = tf.nn.relu(Z2)
with tf.name_scope('pooling2'):
P2 = tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding='SAME')
#第三个全连接层 flat-fc
with tf.name_scope('layer_FC_3'):
with tf.name_scope('pooling2_flat'):
P2 = tf.contrib.layers.flatten(P2)
with tf.name_scope('FC3'):
Z3 = tf.contrib.layers.fully_connected(P2,num_outputs=10,activation_fn=None)
return Z3
#计算代价函数
def compute_cost(Z3,Y):
with tf.name_scope('cost_cross_entry'):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y))
tf.summary.scalar('cost_cross_entry',cost)
return cost
#生成随机的数据
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[0] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation,:,:,:]
shuffled_Y = Y[permutation,:]
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:,:,:]
mini_batch_Y = shuffled_Y[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size : m,:,:,:]
mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size : m,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
#模型整合
from tensorflow.python.framework import ops
def model(train_x,train_y,test_x,test_y,learning_rate = 0.001,iteration=51,batch_size=100,print_cost=True):
# 返回模型无需重写参数
ops.reset_default_graph()
tf.set_random_seed(1)
costs = []
seed = 3
m,n_H0,n_W0,n_C0 = train_x.shape
n_y = train_y.shape[1]
X,Y = create_placeholders(n_H0,n_W0,n_C0,n_y)
Z3 = forward_propagation(X)
cost = compute_cost(Z3,Y)
#定义optimizer
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
#定义准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(Z3,1),tf.argmax(Y,1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction,'float'))
tf.summary.scalar('accuracy',accuracy)
#合并所有的summary
merge = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
train_writer = tf.summary.FileWriter('D:/jupyproject/tensorflow/logs',sess.graph)
for epoch in range(iteration):
seed = seed+1
batches = random_mini_batches(train_x,train_y,batch_size,seed)
for batch in batches:
(mini_x,mini_y)=batch
summary,_ ,train_acc= sess.run([merge,optimizer,accuracy],feed_dict={X:mini_x,Y:mini_y})
train_writer.add_summary(summary,epoch)
if print_cost == True and epoch % 5 == 0:
test_acc = sess.run(accuracy,feed_dict={X:test_x,Y:test_y})
print('acc after epoch %i : %f %f' %(epoch,train_acc,test_acc))
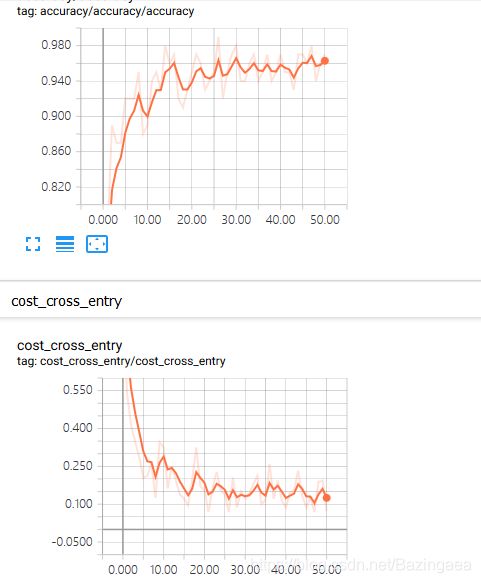
训练一个模型,测试精确度,因为训练时间较长,所以只迭代了51次:
model(train_x,train_y,test_x,test_y)
#结果: 有过拟合现象
acc after epoch 0 : 0.690000 0.716000
acc after epoch 5 : 0.920000 0.914400
acc after epoch 10 : 0.890000 0.934400
acc after epoch 15 : 0.960000 0.942600
acc after epoch 20 : 0.950000 0.949100
acc after epoch 25 : 0.950000 0.949400
acc after epoch 30 : 0.980000 0.952300
acc after epoch 35 : 0.940000 0.950500
acc after epoch 40 : 0.970000 0.954300
acc after epoch 45 : 0.970000 0.956100
acc after epoch 50 : 0.970000 0.956500
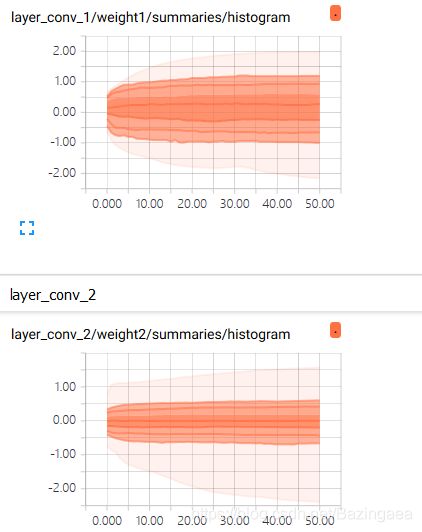
再来看看tensorboard:
针对过拟合的问题,试试加上dropout 看会不会有所改善
#定义一个dropout占位符
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32,name='dropout')
tf.summary.scalar('dropout_keep_probability', keep_prob)
#在forward中选择要drop的那一层,因为只有一个全连接层,就对第二个卷积层池化后的结果进行drop
with tf.name_scope('layer_FC_3'):
with tf.name_scope('pooling2_flat'):
P2 = tf.contrib.layers.flatten(P2)
P2_dropped = tf.nn.dropout(P2, keep_prob)
with tf.name_scope('FC3'):
Z3 = tf.contrib.layers.fully_connected(P2_dropped,num_outputs=10,activation_fn=None)
结果:
acc after epoch 0 : 0.680000 0.732400
acc after epoch 5 : 0.830000 0.901900
acc after epoch 10 : 0.930000 0.927500
acc after epoch 15 : 0.890000 0.934100
acc after epoch 20 : 0.940000 0.935800
acc after epoch 25 : 0.860000 0.938500
acc after epoch 30 : 0.890000 0.940900
acc after epoch 35 : 0.910000 0.943300
acc after epoch 40 : 0.920000 0.943700
acc after epoch 45 : 0.920000 0.943500
acc after epoch 50 : 0.940000 0.945800
可以看出确实改善了过拟合的问题,但是训练的精确也降低了,一般情况会有多个全连接层,然后再使用drop,增加迭代的次数会有更好的结果,我的电脑训练实在太慢了,就留着以后装GPU版本了再试试吧。
我也试过在前两个卷积层进行drop,发现对卷积层进行drop对网络性能的伤害力度要比在全连接层drop大,在卷积层drop完test集精度只能达到92%,当然这是针对我这个模型的,可能再大一点的模型在卷积层drop也不会对网络性能造成很大的损伤。