Hadoop集群安装搭建Hbase和Zookeeper
Hbase简单说明
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
Zookeeper简单说明
Zookeeper HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及
集群配置的维护等工作。具体工作如下:
通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争
机制产生新的 master 提供服务
通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回
调的形式通知 Master RegionServer 上下线的信息
通过 Zoopkeeper 存储元数据的统一入口地址
Hbase访问接口
-
Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
-
HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
-
Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
-
REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
-
Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
-
Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
Hbase与Zookeeper安装配置

左图描述了Hadoop EcoSystem中的各层系统
其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
因此安装Hbase前hadoop集群必须配置完成既有HDFS,没有配置的看我前边的博客:在Centos7上搭建Hadoop集群(二)
我这里使用的Hbase是hbase-1.3.1-bin.tar.gz 、zookeeper-3.4.14.tar.gz、 hadoop版本为2.7.3
-
首先将hbase-1.3.1-bin.tar.gz 、zookeeper-3.4.14.tar.gz上传到hadoop安装的同级目录
如我的hadoop2.7.3解压后在: /user/local/hadoop目录下 (运行hadoop需要进入/user/local/hadoop/hadoop2.7.3/ )
那么我hbase、zookeeper就上传到/user/local/hadoop 即可
-
使用 tar -zxvf hbase-1.3.1-bin.tar.gz进行解压

tar -zxvf zookeeper-3.4.14.tar.gz
进行解压
-
添加hbase,和zookeeper环境变量
配置HBase环境变量,让hbase命令在所有目录下均可使用
参考操作,使用vi命令编辑/etc/profile,在文件最后 增加如下4行:
export ZK_HOME=/usr/local/hadoop/zookeeper-3.4.14
export PATH=$PATH:$ZK_HOME/bin
export HBASE_HOME=/usr/local/hadoop/hbase-1.3.1
export PATH=$PATH:$HBASE_HOME/bin
查看是否配置好。参考命令:
hbase version

-
配置zookeeper的相关配置
1,配置 conf目录下的zoo_sample.cfg,先重命名为 zoo.cfg
后进行相关配置
修改默认的dataDir = /usr/local/hadoop/zkdata
添加
server.1 = Master:2888:3888
server.2=hadoop1:2888:3888
server.3=hadoop2:2888:3888
保存退出

2,分别在三台服务器/usr/local/hadoop/ 下制作目录 zkdata
并在目录下创建文件 myid 文件内容为 1 第二台为 2 三台为 3

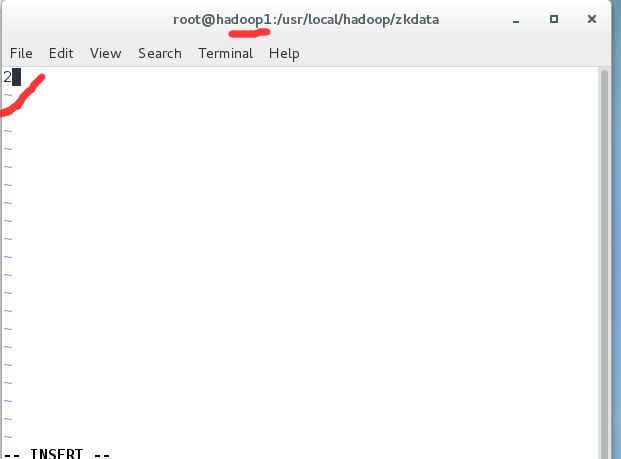
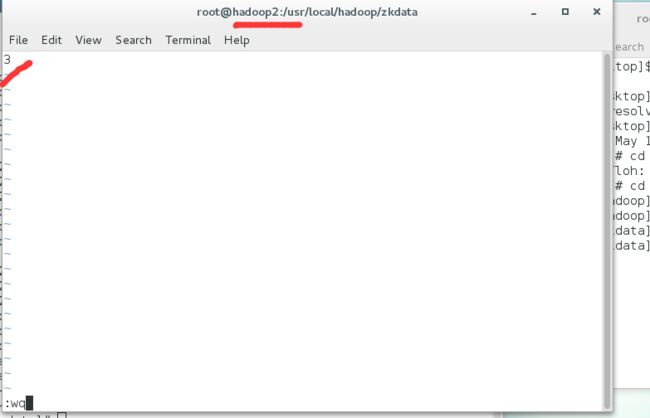
3使用 名令将 zookeeper的整个安装目录拷贝到其他几台的服务器中
参考命令如下(hadoop1,hadoop2请换为自己的分配到的从服务器名称):
scp -r /usr/local/hadoop/zookeeper-3.4.14 root@hadoop1:/usr/local/hadoop/
scp -r /usr/local/hadoop/zookeeper-3.4.14 root@hadoop2:/usr/local/hadoop/
拷贝后,按c步骤的方法在其余几台服务器配置zookeeper的环境变量
配置完成就可以通过zkServer.sh start 启动 zkServer.sh stop 进行停止 zkServer.sh status 查看运行状态(会有一个leader 两个follow)
注意:需要手动在三台服务器上进行启动
启动成功后通过jps可以看到

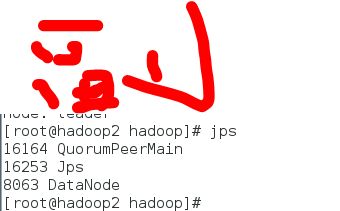
通过 zkServer.sh status 查看运行状态



可以看到一个leader,两个follow,表示主从关系。
如果在查看jsp的时候,三台服务器均有QuorumPeerMain服务,但是查看状态status的时候报错,说没有运行,这说明你服务器与其他服务器
部分端口是不通的,查看是否在 /etc/profile中添加了映射关系,如果添加了,一般就是防火墙没有关闭 ,我在这个地方卡了好久在网上搜的解决方法,去查看关闭防火墙。查看防火墙名令: systemctl status firewalld.service
如果看到activity 有绿色亮点说明防火墙没有关闭,关闭防火墙即可
systemctl stop firewalld.service命令,进行关闭防火墙
输入名令:systemctl disable firewalld.service 即可永久关闭防火墙,放置重启后再打开。至此zookeeper安装部署完毕。
-
修改hbase-env.sh
修改hbase-1.2.4/conf目录下的hbase-env.sh文件,参考命令:
vi /usr/local/hadoop/hbase-1.3.1/conf/hbase-env.sh
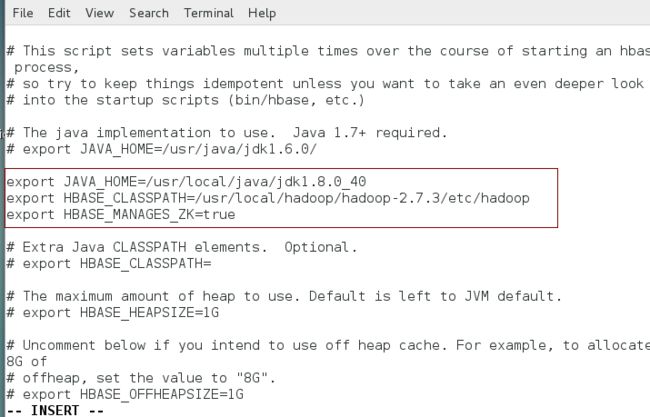
增加如下配置(jdk路径和hadoop目录请根据实际情况配置):
export JAVA_HOME=/usr/local/java/jdk1.8.0_40
export HBASE_CLASSPATH=/usr/local/hadoop/hadoop-2.7.3/etc/hadoop
export HBASE_MANAGES_ZK=true
-
修改hbase-site.xml
修改hbase-1.2.4/conf目录下的hbase-site.xml文件,
vi /usr/local/hadoop/hbase-1.3.1/conf/hbase-site.xml
增加如下配置(2处Master请修改自己的主机名称):
-
hbase.rootdir hdfs://master:9000/hbase hbase.cluster.distributed true hbase.zookeeper.quorummaster

-
修改regionservers文件
修改hbase-1.2.4/conf目录下的regionservers文件 ,
vi /usr/local/hadoop/hbase-1.3.1/conf/regionservers
删除里面的localhost,并将其他要作为regionserver的服务器加入其中即两个从服务器的名.参考配置如下:
hadoop1
hadoop2
至此主服务器上的hbase配置完毕,我们需要将hbase的安装目录分别拷贝到其他两台从服务器
参考命令如下(hadoop1,hadoop2请换为自己的分配到的从服务器名称):
scp -r /usr/local/hadoop/hbase-1.3.1 root@hadoop1:/usr/local/hadoop/
scp -r /usr/local/hadoop/hbase-1.3.1 root@hadoop2:/usr/local/hadoop/
至此安装配置hbase结束。
测试Hbase是否安装成功
-
启动hadoop集群,进入/usr/local/hadoop/hadoop2.7.3目录运行
sbin/./start-all.sh
启动hbase
cd /usr/local/hadoop/hbase-1.3.1
bin/./start-hbase.sh
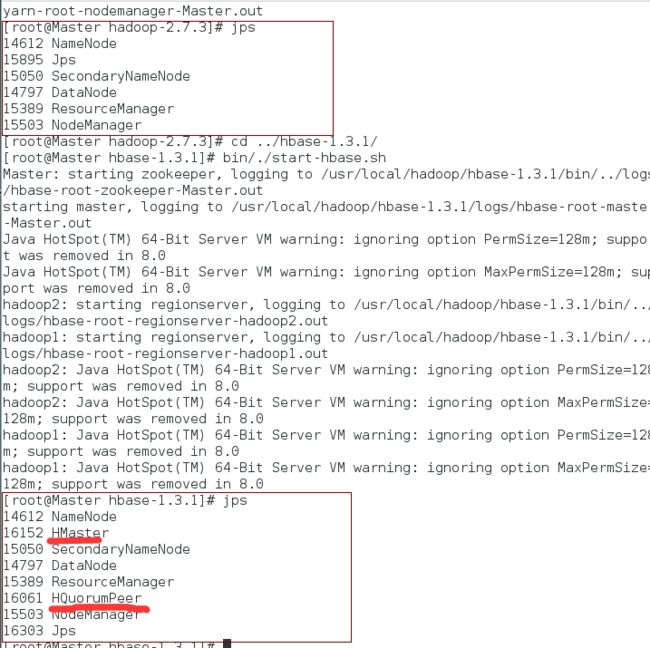
可以看到启动前后明显多了HQuorumPeer和HMaster服务
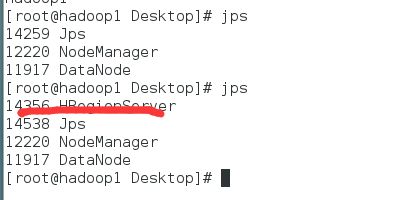
从服务器多了HRegionServer 服务 说明启动成功:

使用HBase shell命令管理表数据
进入hbase shell命令行
在master服务器上输入命令hbase shell即可进入到hbase shell命令行
尝试用hbase创建一个表
create 命令创建create命令创建表名为Employee,包含一个列族cf的表。
参考命令:
create 'Employee','cf'
使用put命令向表中添加记录
将向表Employee中添加一名雇员的信息,EmpId为:1001,EmpName为:Henry,Address为:'Bangalore'。参考命令:
put 'Employee','Record1','cf:EmpId','1001'
put 'Employee','Record1','cf:EmpName','Henry'
put 'Employee','Record1','cf:Address','Bangalore'

可以看到成功创建,并且数据成功插入
(1) 列出HBase所有的表的相关信息,例如表名;
名令: list

可以看到我们刚刚创建的Employee表
如果无法创建表和无法插入表,请查看三台服务器的时间是否一样不一样则用
ntpdate 1.cn.pool.ntp.org 进行时区同步然后将hbase服务重启进行解决
(2) 在终端打印出指定的表的所有记录数据;
使用名令 scan 'Employee' 查看 Employee表中的数据

(3) 向已经创建好的表添加和删除指定的列族或列;
删除Employee表中行键为Record1的 EmpName列记录。
再删除行键为:Record1 的所有记录。参考命令:
delete 'Employee','Record1','cf:EmpName'

可以看到删除成功后变成两列
deleteall 'Employee','Record1'

可以看到删除完了,因为我们只有一条数据,所以证明成功
我们再次插入两行数据
put 'Employee','Record1','cf:EmpId','1001'
put 'Employee','Record1','cf:EmpName','Henry'
put 'Employee','Record1','cf:Address','Bangalore'
put 'Employee','Record1','cf:EmpId','1001'
后再插入一列
put 'Employee','Record2','cf:Address','fei'

(4) 统计表的行数。
使用 count,名令:

看到有两行
(5) 清空指定的表的所有记录数据;
truncate 'Employee'

清空为0了
转载自:一只飞翔的章鱼