Enriching Pre-trained Language Model with Entity Information for Relation Classification 论文研读
论文地址:https://arxiv.org/pdf/1905.08284.pdf
摘要
关系分类是一项重要的自然语言处理任务用以抽取两实体的关系,最先进的关系分类方法主要是基于卷积网络(CNN)或者循环网络(RNN)。最近,预训练模型BERT成功应用于诸多NLP领域的分类和序列标注问题。关系分类与以上问题的不同之处在于它依赖句子和两个实体的信息。在此论文中,提出了一种既用BERT预训练语言模型又结合了目标实体信息的方法来解决关系分类任务。我们定位目标实体并通过预训练的体系结构来编码两个实体。在数据集SemEval-2010-task8上取得了明显的提高。
1.介绍
关系分类的任务是预测句子中两个实体的关系,给定一个文本句子 和一对实体
和一对实体![]() ,来确定两个实体的关系。它是一项重要的NLP任务常用总各NLP应用的中间步骤。举例来说:“The [kitchen]
,来确定两个实体的关系。它是一项重要的NLP任务常用总各NLP应用的中间步骤。举例来说:“The [kitchen] is the last renovated part of the [house]
is the last renovated part of the [house]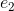 ”,句子中的 [kitchen]和 [house]就是Component-Whole(组件-整体)的关系。
”,句子中的 [kitchen]和 [house]就是Component-Whole(组件-整体)的关系。
深度神经网络(DNN)应用于关系分类中,这类方法一般是在词汇资源Word-net或者NLP工具像依赖解析器和命名实体识别下抽取一些特征,进行关系分类。
预训练语言模型使很多NLP任务在效率上有很大提高,BERT预训练模型尤其产生了深远的影响。BERT应用到多项NLP任务并且刷榜11项NLP任务,BERT通常应用在分类问题和序列标注问题。在问答系统中,它用在寻找答案的起点和终点问题。
众所周知,BERT预训练模型不能应用到关系分类问题中,原因是这类问题不仅依赖整个句子信息,而且依赖于特定的目标实体信息。这篇论文里,我们将BERT预训练模型应用到关系分类问题中,我们在BERT进行微调之前在目标实体前后插入特殊标记,为了标识两个目标实体的定位并且转换信息到BERT模型中,然后在BERT模型输出的词嵌入中定位两实个目标实体中的位置,我们将他们的词嵌入和句子编码(在BERT设置中第一个特殊标记的词嵌入)作为多层神经网络的输入进行分类。通过这种方法来捕获句子的语义和两个目标实体最恰当的关系分类任务。我们的贡献如下:
- 提出结合实体级信息到预训练模型的先进创新方法解决关系分类问题。
- 产生了关系分类任务的新纪录。
2相关工作
这里有很多的方法用在关系分类问题中总结如下:
- Socher在2012年提出MVRNN模型来解决关系分类问题。

图中表示的就是MVRNN算法,分配了一个矩阵向量表示解析树中的每一个节点,自下而上计算句子的表示结构
- Zeng在2014年引入卷积网络(CNN)经典模型来解决关系分类问题。

这篇文章第一次引入深度学习内容中卷积神经网络(CNN),文章中首先利用现有的Word embedding进行数据表示,将两个目标实体的位置信息作为lexical level feature(词汇级特征),利用CNN抽取sentence level feature(句子即特征),再将两组特征合并,送入softmax分类其中,实现关系分类任务。
- Yu在2014年提出FCM(Factor-based Compositional Model 基于因子模型),通过解析树和命名实体来构造句子级和子级的embedding。
- Santos在2015年提出CR-CNN模型,它的损失函数是基于成对排序的。
- Shen和Huang在2016年,利用CNN编码器与句子表示结合,对目标实体和句子中的单词按注意力加权来表示关系分类。
- Wang在2016年提出一种两层注意力的卷积网咯,来捕获异构环境中的模式来进行关系分类。
- Lee在2019年提出了端到端的递归神经网络模型,结合一种基于实体类型的实体感知注意力机制。
- Mintz_2009、Hoffmann_2011、Lin_2016、Ji_2017、Wu_2019等提出的基于远距离监督方法解决关系分类问题。
在关系分类问题中,正常的数据和远距离监督数据的不同就在于后者有大量的噪声标签。这篇论文中,我们所关注的是规律的正常的数据,是没有噪声标签的。
3.方法
3.1BERT预训练模型
BERT预训练模型是一个多层双向的transformer encoder(编码器),BERT的输入表示设计是为了在一个被标记句子中同时表示一个简单的文本句子和一对文本句子。每一个被标记的输入表示由对应的标记,分段和位置词嵌入来表示。
CLS被追加到每一个句子的首位,作为第一个句子标记,从第一个标记句子的transformer 输出得到的最终隐藏层状态作为分类任务的句子表示。若任务中有两个句子,用[SEP]来分割,结尾也用[SEP]来标记。
BERT通过使用预训练目标:屏蔽语言模型(MLM)来预训练模型参数,该模型随机地从输入中屏蔽一些标记,一般讲值设置为-INF,并设置优化目标来根据其上下文预测被屏蔽词的原始词汇id,与从左到右的语言模型预训练不同,MLM目标可以帮助状态输出利用左和右上下文,这允许应用深度双向Transformer预训练系统。 除了掩蔽语言模型外,BERT还训练了一个“下一句预测”任务共同预训练文本对表示。
3.2模型结构
下图展示了论文中方法的结构:

对于具有两个实体![]() 的句子,为了让BERT获取两个实体的位置信息,我们在第一个实体的开头和结尾都插入一个特殊的符号‘$’,在第二个实体的开头和结尾插入特殊符号‘#’,在每个句子的开头加上‘[CLS]’。下面是改变之后的例子:
的句子,为了让BERT获取两个实体的位置信息,我们在第一个实体的开头和结尾都插入一个特殊的符号‘$’,在第二个实体的开头和结尾插入特殊符号‘#’,在每个句子的开头加上‘[CLS]’。下面是改变之后的例子:
[CLS] The $ kitchen $ is the last renovated part of the # house #
给定一个带有实体![]() 的句子,假定它们最终从BERT输出的隐藏状态为
的句子,假定它们最终从BERT输出的隐藏状态为 。假设向量
。假设向量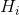 到
到![]() 是的BERT隐藏层状态,
是的BERT隐藏层状态,![]() 到
到![]() 是的隐藏层状态,我们用均值操作获得每一个单词的向量表示,接下来通过激活函数(例如tanH)接入全连接层,分贝输出
是的隐藏层状态,我们用均值操作获得每一个单词的向量表示,接下来通过激活函数(例如tanH)接入全连接层,分贝输出![]() 。这个过程可以在数学公式上划等表示。
。这个过程可以在数学公式上划等表示。
![H_{1}^{'} = W_{1}[tanh(\frac{1}{j-i+1}\sum_{t=i}^{j}H_{t})] + b_{1}](http://img.e-com-net.com/image/info8/8a02db24219248d69804f54f7883a2f5.gif)
![H_{2}^{'} = W_{2}[tanh(\frac{1}{m-k+1}\sum_{t=i}^{j}H_{t})] + b_{2}](http://img.e-com-net.com/image/info8/03f18abee3dd45a4947fd082e4c3fc34.gif)
我们使![]() 参数共享,也就是说
参数共享,也就是说![]() 。对于首标记[CLS]的最终隐藏层变量我们也添加一个激活函数和全连接层,公式表达为:
。对于首标记[CLS]的最终隐藏层变量我们也添加一个激活函数和全连接层,公式表达为:
![]()
来自BERT最终隐藏层矩阵![]() 有相同的纬度,
有相同的纬度,![]() ,
,![]() ,
,![]() 。
。
我们将![]() 串联在一起,之后添加全连接层和softmax层,数学表达式如下:
串联在一起,之后添加全连接层和softmax层,数学表达式如下:
![]()
![]()
其中![]() ,
, 是分类的个数,p为可能的输出。等式中
是分类的个数,p为可能的输出。等式中![]() 是偏值向量。
是偏值向量。
我们使用交叉熵作为损失函数。 在训练期间,我们在每个完全连接的层之前应用dropout。 称这样方法为R-BERT。
4.实验
4.1数据集和评价机制
试验中使用 SemEval-2010 Task 8数据集,数据集包括9种语义关系和1中人工定义的关系Other,这就意味着Other不属于9中关系中的任何一种,9中关系包括:Cause-Effect,Component-Whole, Content-Container, Entity-Destination, Entity-Origin, Instrument-Agency,Member-Collection, Message-Topic and Product-Producer。数据集中包含10717个句子,分别包含两个实体和一种关系。注意关系是有方向的例如Component-Whole(e1,e2)与Component-Whole(e2,e1)是不同的。数据包括8000个训练句和2717个测试句。我们用SemEval-2010 Task 8官方脚本来评估结果。计算9个关系宏观平均值F1值,并且包括方向性。
4.2参数设置
参数设置如下表所示:

在每一个添加层前我们都使用dropout,对于BERT预训练模型,使用不加约束的基础模型,BERT预训练模型的参数请参考 (Devlin et al., 2018)论文。
4.3模型对比
模型之间的比较,参考下表:

此论文中使用的R-BERT模型,达到最好的效果,F1=89.25
4.4简化测试研究
在实验中,加入了[sep],它既是间隔符,又是结束符。所以将简化测试分为4中情况:R-BERT-NO-SEP-NO-ENT、R-BERT-NO-SEP、R-BERT-NO-ENT 、R-BERT。经过实验后,都没有R-BERT实验效果好,实验结果如下表:

5总结
在本文中,我们提出了一种利用实体信息丰富预先训练好的BERT模型来进行关系分类的方法。 我们添加特殊的将标记分离到每个目标实体对,并利用句子向量以及目标实体表示进行分类。 我们在SemEval-2010基准数据集上进行了实验,并且结果明显优于现有的方法。 扩展该模型以适用于远程监管可能是未来的一个方向。
以上是对论文原文的解读,对于原文的理解和代码的解读和复现,后序会更新在博客中。 ---------2020.02.08