从零开始实现一个基于RISC-V的流水线处理器 (2) :浅谈处理器的流水线设计
目录
- 处理器的流水线设计
- 流水线的概念
- 流水线设计中出现的问题
- 扩展:提高流水线效率的方法
- 乱序执行
- 超标量
- 多线程
- 我们的设计
- 总结
- 参考资料
处理器的流水线设计
流水线的概念
流水线技术是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理,以加速程序运行过程的技术。指令的每步有各自独立的电路来处理,每完成一步,就进到下一步,而前一步则处理后续指令。而这也是大部分微处理器架构改进的方面:提高程序的指令并行度(ILP)。
对于最简单的微处理器,我们可以将指令的执行分为四个阶段:
- 取指:将下一条指令从存储器中取出来。
- 译码:决定指令中所定义的操作类型。
- 执行:执行指令所定义的操作。
- 写回:指令操作结果被储存起来。
一个简单的串行执行微处理器如下图所示:

在这个处理器中,每个指令阶段需要一个时钟周期,而且仅当当前的指令执行完毕后,下一条指令才会开始执行。
由于指令的每个阶段都有相互独立的模块进行执行,因此我们发现使用流水线可以提高处理器的性能。通过增加一些控制逻辑,处理器中可以有处于不同阶段的多个指令同时执行。
下图展示了流水线设计的处理器执行指令的过程。简单的串行处理器每4个时钟周期完成一条指令,而一个理想的流水线处理器每个时钟周期都可以完成一条指令。
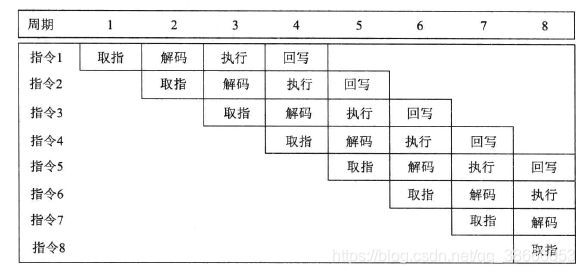
流水线设计中出现的问题
无论如何,一个流水线的设计不可能是完全理想的。理想流水线只有在每条指令可以在相同的时钟周期完成并且在指令之间没有任何依赖的条件下才能达到。
然而,一些指令实际上比别的指令更复杂并需要更多的时钟周期才能得到结果。一条除法指令比一条加法指令需要更多的时钟周期来完成计算。一条Load指令在缓存中如果产生未命中,相对于在缓存中 hit 的操作而言,则需要更多的时钟周期。尽管在执行过程中有这些因素的影响,但是如果没有指令之间的依赖性,流水线还是有可能达到理想性能的。
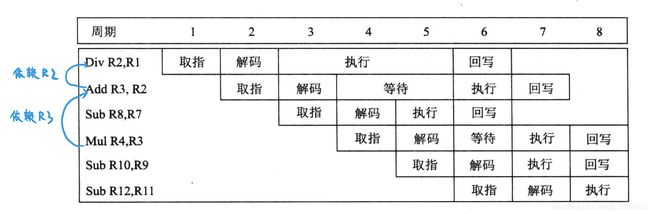
假设第一条指令是除法指令,这条指令需要往寄存器2存放计算结果,而第二条指令是一条加法指令,这条指令恰恰需要读取寄存器2的数据作为输入。那么,这条加法指令就必须等到除法指令的执行阶段完成后才能进入执行阶段。如下图所示,这就引起了流水线中断。

引起流水线中断的原因有:数据依赖、控制依赖、资源冲突。
在上文中我们提到了数据依赖的情形。由于第一条指令和第二条指令之间的数据依赖,使得接下来的指令都需要延迟。由于一些时钟周期是在等待依赖关系的解决,流水线不再每一个周期完成一条指令。
除了数据以来以外,还存在控制依赖。分支指令和无条件跳转指令的功能是决定接下来哪一条指令可以进入流水线,因此在执行这些类型的指令时需要中断原本下一条指令 (pc + 4) 的取指和执行阶段,如下图所示。

对于第3条指令的Branch指令,译码器在译码阶段译码出该指令的类型后就立即中断后续指令的执行,并在当前指令执行阶段结束之后,即pc地址跳转完成之后再开始下一条指令的取指阶段。
第三种会导致流水线中断的因素是资源冲突。示例处理器的微处理器结构可能只有一个除法单元,如果有两条除法指令需要执行,即使没有任何数据依赖和控制依赖,后来的除法指令也必须等待直到上一条除法指令完成,因为上一条除法指令占着除法单元。流水线中断限制了流水线可以达到的性能提高。
扩展:提高流水线效率的方法
乱序执行
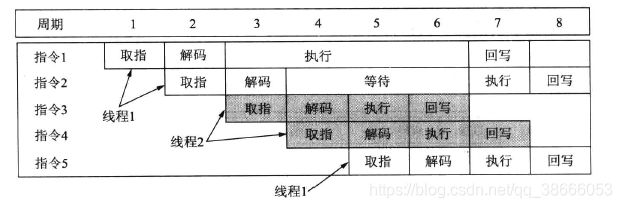
下图说明了一种乱序执行流水线,第二条指令为采用除法结果作为输入的加法指令,第四条指令为采用加法结果作为输入的乘法指令。由于这些指令之间存在着数据依赖,所以就要求这些指令按顺序执行。然而,其他指令如减法指令,和其他指令的数据无关。这些指令中每一条都和别的指令没有共享的寄存器。这就使得第三条的减法指令可以在第四条的加法指令之前执行,即使在指令序列中减法指令在加法指令之后。
超标量
通过增加硬件资源可使在同一时刻流水线的同一级执行多条指令,超标量 (superscalar) 处理器可以提升IPC,如下图所示。

一个单发射乱序执行流水线最多可以达到的IPC是1,也就是说每个时钟周期可以完成一条指令。而一个超标量处理器可以达到大于1的IPC。超标量设计通常由处理器发射宽度来描述,发射宽度是指可以同时进入流水线的最多指令的条数。越来越多的MOS管使2发射、3发射甚至更多发射的超标量微处理器架构变成现实。但是太大的发射宽度会使处理器达到理论最大性能的难度变得很大。
越来越大的发射宽度和越来越深的流水线意味着序列器需要发现越来越多的相互独立的指令以保持流水线满负荷运转。由于大量的流水线中断,一个有能力达到IPC为3的处理器实际上可能达到的IPC小于1。
多线程
多线程架构扩展允许程序分成很多独立的线程来简化序列器的工作。通过把存在数据依赖的指令划分到一个线程里,则任意两个线程的数据都是正交的。这样序列器就可以在一个线程指令引起流水线中断时在流水线中填充另一个线程的指令。
乱序发射和超标量发射都是微处理器架构方面的技术,可以在不需要改进软件的基础上提高处理器性能。多线程是处理器架构和微处理器架构共同作用的一个示例,需要改变软件编程的代码从而提升更多的处理器性能。
我们的设计
在本次的微处理器设计中,我们将一条指令的执行划分为五个阶段:取指、译码、执行、访存、写回。下面笔者将对每个阶段的具体功能进行说明。
- 取指:更新 pc 的地址,根据 pc 的地址从 rom 取指令,并把指令送入decoder.
- 译码:decoder 接收指令,译码出指令中的rs1 / rs2 / rd / imm,发送到ALU;并根据指令的opcode / funct确定指令的具体类型,由此产生控制信号,并把控制信号发送到后面几级。
- 执行:指令的具体执行。对于ADD / SUB / SLL等逻辑操作,就是在 ALU 中完成加/减/移位,并把执行完毕的结果送到写回级;对于Load/Store操作,则是计算出目标地址。
- 访存:当且仅当指令类型为Load / Store时,ram 的read / write权限打开,接收ALU送出的地址,对内存进行读写。
- 写回:执行阶段或访存阶段完毕后,把最终的数据传输到寄存器组的输入端,并最终写入目标寄存器。
在RV32I为指令集的微处理器中只有Load / Store指令拥有访问内存的权限,也就是说,对于Load / Store指令,其执行过程为:
取指 -> 译码 -> 执行 -> 访存 -> 写回(当为Load指令时)
这一过程涉及到了寄存器与内存之间的数据交换。
对于其他指令,执行过程为:
取指 -> 译码 -> 执行 -> 访存(什么也不做)- > 写回
这一过程只涉及到寄存器与寄存器之间的数据交换,与内存无关。由于绝大多数指令都在寄存器与寄存器之间完成,在非必要条件下不对内存进行访问,处理器的功耗也就降低了。
为了保证在执行过程中不出现逻辑问题,我们采用寄存器寄存的方式来处理译码器产生的控制信号:在每一级都插入控制信号对应的译码器,保证控制信号始终与同一指令中的数据处于同一阶段。这样当不访存的指令进入到访存阶段后,也只是将控制信号通过寄存器的作用延迟一个时钟周期,不进行读写操作,保证了逻辑的正确性。
总结
本文完成了对处理器流水线结构的说明,并确定了我们设计的微处理器的具体流水线结构。在下一章中,我们先不考虑可能导致流水线中断的因素,直接实现微处理器的顶层模块,在之后再回过头来为微处理器添加数据冲突检测模块。
参考资料
本文大部分选自Grant McFarland 著,管虎 译《微处理器设计——从设计规划到工艺制造》,这是一本微处理器设计方面的参考书(看名字就知道)。虽然未提供具体代码,但是对处理器的内部结构、指令执行过程、处理器架构、处理器工艺等多方面都进行了讲解,是一份非常好的参考资料。