Tensorflow实现cifar10识别
首先要准备的是cifa10数据集,下载地址:http://www.cs.toronto.edu/~kriz/cifar.html下载binary版。cifar-10分类数据集为60000张32 * 32的彩色图片,总共有10个类别,其中50000张训练集,10000张测试集。
之后从https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10下载cifar10.py和cifar10_input.py。将这两个文件放在工程目录下即可。
- 载入需要的库
import tensorflow as tf
import numpy as np
import cifar10
import cifar10_input
import time2. 初始化权重函数
def variable_with_weight_loss(shape,std,w1):
var = tf.Variable(tf.truncated_normal(shape,stddev=std),dtype=tf.float32)
#使用tf.truncated_normal截断的正态分布,加上L2的loss,相当于做了一个L2的正则化处理
#w1:控制L2 loss的大小,tf.nn.l2_loss函数计算weight的L2 loss
if w1 is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(var),w1,name="weight_loss")
tf.add_to_collection("losses",weight_loss)#加入losses列表
return var3. 计算softmax和loss
def loss_func(logits,labels):
labels = tf.cast(labels,tf.int32)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels,name="cross_entropy_per_example")
#softmax和cross entropy loss的计算合在一起
cross_entropy_mean = tf.reduce_mean(tf.reduce_sum(cross_entropy))
#计算cross entropy 均值
tf.add_to_collection("losses",cross_entropy_mean)
#把交叉熵均值加入到losses中
return tf.add_n(tf.get_collection("losses"),name="total_loss")
#将整体losses的collection中的全部loss求和,即最终的loss,有cross entropy loss,两个全连接层 中weight的L2 loss4. 定义参数,处理数据,载入数据
#设置最大迭代次数
max_steps = 10000
#设置每次训练的数据大小
batch_size = 128
# 设置数据的存放目录
cifar10_dir = "C:\\Users\\zlj\\Downloads\\cifar-10-batches-bin"
#训练集
#distored_inputs函数产生训练需要使用的数据,包括特征和其对应的label,返回已经封装好的tensor,每次执行都会生成一个batch_size的数量的样本
images_train,labels_train = cifar10_input.distorted_inputs(cifar10_dir,batch_size)
#测试集
images_test,labels_test = cifar10_input.inputs(eval_data=True,data_dir=cifar10_dir
,batch_size=batch_size)
#载入数据
image_holder = tf.placeholder(dtype=tf.float32,shape=[batch_size,24,24,3])
#裁剪后尺寸为24×24,彩色图像通道数为3
label_holder = tf.placeholder(dtype=tf.int32,shape=[batch_size])5. 设计卷积层
第一层:
weight1 = variable_with_weight_loss(shape=[5,5,3,64],std=5e-2,w1=0)
#使用variable_with_weight_loss函数创建卷积核的参数并进行初始化。5×5的卷积和,3个通道,64个滤波器。weight1初始化函数的标准差为0.05,不进行正则wl(weight loss)设为0
kernel1 = tf.nn.conv2d(image_holder,weight1,[1,1,1,1],padding="SAME")
#tf.nn.conv2d函数对输入进行卷积
bais1 = tf.Variable(tf.constant(0.0,dtype=tf.float32,shape=[64]))
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1,bais1))
#最大池化层尺寸为3x3,步长为2x2
pool1 = tf.nn.max_pool(conv1,[1,3,3,1],[1,2,2,1],padding="SAME")
#LRN层模仿生物神经系统的侧抑制机制
norm1 = tf.nn.lrn(pool1,4,bias=1.0,alpha=0.001 / 9,beta=0.75)第二层:
weight2 = variable_with_weight_loss(shape=[5,5,64,64],std=5e-2,w1=0)
#5×5的卷积和,第一个卷积层输出64个通道,64个滤波器
kernel2 = tf.nn.conv2d(norm1,weight2,[1,1,1,1],padding="SAME")
bais2 = tf.Variable(tf.constant(0.1,dtype=tf.float32,shape=[64]))
#初始化为0.1
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2,bais2))
norm2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.01 / 9,beta=0.75)
pool2 = tf.nn.max_pool(norm2,[1,3,3,1],[1,2,2,1],padding="SAME")6. 设计全连接层
第一层:
reshape = tf.reshape(pool2,[batch_size,-1])#将数据变为1D数据
dim = reshape.get_shape()[1].value#获取维度
weight3 = variable_with_weight_loss([dim,384],std=0.04,w1=0.004)
bais3 = tf.Variable(tf.constant(0.1,shape=[384],dtype=tf.float32))
local3 = tf.nn.relu(tf.matmul(reshape,weight3)+bais3)第二层和第三层:
weight4 = variable_with_weight_loss([384,192],std=0.04,w1=0.004)
bais4 = tf.Variable(tf.constant(0.1,shape=[192],dtype=tf.float32))
local4 = tf.nn.relu(tf.matmul(local3,weight4)+bais4)
weight5 = variable_with_weight_loss([192,10],std=1/192.0,w1=0)
bais5 = tf.Variable(tf.constant(0.0,shape=[10],dtype=tf.float32))
logits = tf.add(tf.matmul(local4,weight5),bais5)7.数据准备
#获取损失函数
loss = loss_func(logits,label_holder)
#设置优化算法使得成本最小
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss)
#获取最高类的分类准确率,取top1作为衡量标准
top_k_op = tf.nn.in_top_k(logits,label_holder,1)
#创建会话
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
#动线程,在图像数据增强队列例使用了16个线程进行加速。
tf.train.start_queue_runners()8. 训练过程
for step in range(max_steps):
start_time = time.time()
#获得一个batch的训练数据
images_batch,labels_batch = sess.run([images_train,labels_train])
#将batch的数据传入train_op和loss的计算
_,loss_value = sess.run([train_step,loss],feed_dict={image_holder:images_batch,
label_holder:labels_batch})
#获取计算时间
duration = time.time() - start_time
if step % 1000 == 0:
#计算每秒处理多少张图片
per_images_second = batch_size / duration
#获取计算一个batch需要的时间
sec_per_batch = float(duration)
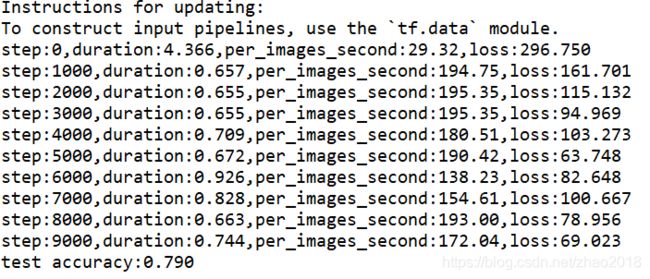
print("step:%d,duration:%.3f,per_images_second:%.2f,loss:%.3f"%(step,duration
,per_images_second,loss_value))9.计算准确率
num_examples = 10000
import math
num_iter = int(math.ceil(num_examples / batch_size))
true_count = 0
total_sample_count = num_iter * batch_size
step = 0
while step < num_iter:
images_batch,labels_batch = sess.run([images_test,labels_test])
pred = sess.run([top_k_op],feed_dict={image_holder:images_batch,label_holder:labels_batch})
true_count += np.sum(pred)
step += 1
#计算测试集的准确率
precision = true_count / total_sample_count
print("test accuracy:%.3f"%precision)结果如下: