第三天:Flink的State、CheckPoint、Window窗口
5. Flink State管理跟恢复
Flink 是一个默认就有状态的分析引擎,前面的 WordCount 案例可以做到单词的数量的累加,其实是因为在内存中保证了每个单词的出现的次数,这些数据其实就是状态数据。但是如果一个 Task 在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义(At -least-once 和 Exactly-once)上来说,Flink 引入了 State 和CheckPoint。
State一般指一个具体的 Task/Operator 的状态(Task Slot/ 转换算子),State 数据默认保存在 Java 的堆内存中。- CheckPoint(可以理解为
CheckPoint是把State数据持久化存储了)则表示了一个 Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有Task/Operator的状态。

1. 常用 State
Flink 有两种常见的 State 类型,分别是:
Keyed State(键控状态)Operator State(算子状态)
1. Keyed State(键控状态)
Keyed State:顾名思义就是基于 KeyedStream上的状态,这个状态是跟特定的 Key 绑定的。KeyedStream 流上的每一个 Key,都对应一个 State。Flink 针对 Keyed State 提供了 以下可以保存 State 的数据结构:
ValueState:
保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行检索。ListState:
保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上 进行检索。可以通过 add(T) 或者 addAll(List) 进行添加元素,通过 Iterableget()获得整个列表。还可以通过update(List) 覆盖当前的列表。ReducingState:
保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。AggregatingState:
保留一个单值,表示添加到状态的所有值的聚合。和 ReducingState 相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与 ListState 类似,但使用 add(IN) 添加的元素会用指定的 AggregateFunction 进行聚 合。FoldingState:
保留一个单值,表示添加到状态的所有值的聚合。 与 ReducingState 相反,聚合类型可能与添加到状态的元素类型不同。接口与 ListState 类似,但使用 add(T)添加的元素会用指定的 FoldFunction 折叠成聚合值。MapState:
维护了一个映射列表。 你可以添加键值对到状态中,也可以获得 反映当前所有映射的迭代器。使用 put(UK,UV) 或者 putAll(Map) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、 键和值的可迭代视图。
2. Operator State(算子状态)
Operator State 与 Key 无关,而是与Operator绑定,整个 Operator 只对应一个 State。 比如:Flink 中的 Kafka Connector 就使用了 Operator State,它会在每个 Connector 实例 中,保存该实例消费 Topic 的所有(partition, offset)映射。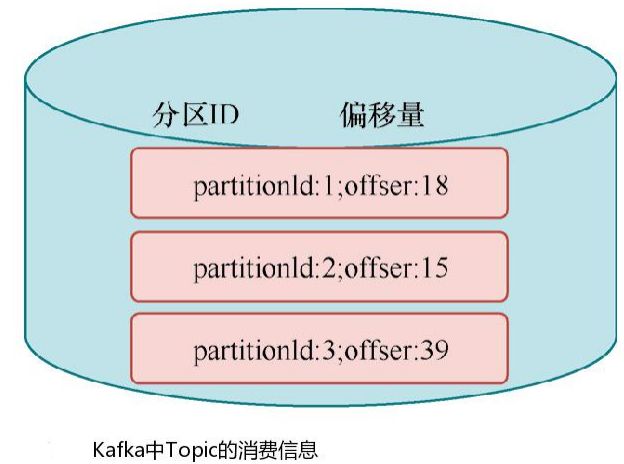
3. Keyed State 案例
demo1:监控每一个手机号码,如果这个号码在5秒内,所有呼叫它的日志都是失败的,
demo2 需求:计算每个手机的呼叫间隔时间,单位是毫秒。
package com.sowhat.flink.state
import java.net.{URL, URLDecoder}
import com.sowhat.flink.BatchWordCount.getClass
import com.sowhat.flink.source.StationLog
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
/**
* 基站日志
* @param sid 基站的id
* @param callOut 主叫号码
* @param callInt 被叫号码
* @param callType 呼叫类型
* @param callTime 呼叫时间 (毫秒)
* @param duration 通话时长 (秒)
*/
case class StationLog(sid: String, var callOut: String, var callInt: String, callType: String, callTime: Long, duration: Long)
/**
* 第一种方法的实现
* 统计每个手机的呼叫时间间隔,单位是毫秒
*/
object TestKeyedState1 {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
val filePath: URL = getClass.getResource("/station.log") //使用相对路径来得到完整的文件路径
val packagePath: String = filePath.getPath().replaceAll("%20", ""); //解决路径中含有空格的情况
val str:String = URLDecoder.decode(packagePath, "utf-8"); //解决路径包含中文的情况
val stream: DataStream[StationLog] = streamEnv.readTextFile(str)
.map(line => {
val arr:Array[String] = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
stream.keyBy(_.callOut) //分组
.flatMap(new CallIntervalFunction)
.print()
streamEnv.execute()
}
//输出的是一个二元组(手机号码,时间间隔)
class CallIntervalFunction extends RichFlatMapFunction[StationLog, (String, Long)] {
//定义一个状态,用于保存前一次呼叫的时间
private var preCallTimeState: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
preCallTimeState = getRuntimeContext.getState(new ValueStateDescriptor[Long]("pre", classOf[Long]))
}
override def flatMap(value: StationLog, out: Collector[(String, Long)]): Unit = {
//从状态中取得前一次呼叫的时间
val preCallTime:Long = preCallTimeState.value()
if (preCallTime == null || preCallTime == 0) { //状态中没有,肯定是第一次呼叫
preCallTimeState.update(value.callTime)
} else { //状态中有数据,则要计算时间间隔
val interval:Long = Math.abs(value.callTime - preCallTime)
out.collect((value.callOut, interval))
}
}
}
}
结果:
4> (18600003532,7000)
2> (18600003713,0)
1> (18600003502,9000)
1> (18600003502,0)
1> (18600003502,9000)
1> (18600007699,0)
1> (18600000005,150000)
stationlog.txt文件信息如下:
station_1,18600000005,18900007729,fail,1577080453123,0
station_1,18600000005,18900007729,success,1577080603123,349
station_8,18600007461,18900006987,barring,1577080453123,0
station_5,18600009356,18900006066,busy,1577080455129,0
station_4,18600001941,18900003949,busy,1577080455129,0
...自己造数据即可
还有第二种简单的方法:调用flatMapWithState 算子
package com.sowhat.flink.state
import java.net.{URL, URLDecoder}
import com.sowhat.flink.source.StationLog
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 第二种方法的实现
* 统计每个手机的呼叫时间间隔,单位是毫秒
*/
object TestKeyedState2 {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
val filePath: URL = getClass.getResource("/station.log") //使用相对路径来得到完整的文件路径
val packagePath: String = filePath.getPath().replaceAll("%20", ""); //解决路径中含有空格的情况
val str: String = URLDecoder.decode(packagePath, "utf-8"); //解决路径包含中文的情况
val stream: DataStream[StationLog] = streamEnv.readTextFile(str)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
stream.keyBy(_.callOut) //分组
//有两种情况1、状态中有上一次的通话时间,2、没有。采用scala中的模式匹配
.mapWithState[(String, Long), StationLog] {
case (in: StationLog, None) => ((in.callOut, 0), Some(in)) //状态中没有值 是第一次呼叫
case (in: StationLog, pre: Some[StationLog]) => { //状态中有值,是第二次呼叫
var interval:Long = Math.abs(in.callTime - pre.get.callTime)
((in.callOut, interval), Some(in))
}
}.filter(_._2 != 0)
.print()
streamEnv.execute()
}
}
2. CheckPoint
当程序出现问题需要恢复State 数据的时候,只有程序提供支持才可以实现State 的容错。State 的容错需要依靠 CheckPoint机制,这样才可以保证 Exactly-once 这种语义,但是注意,它只能保证 Flink 系统内的 Exactly-once,比如 Flink 内置支持的算子。针对 Source 和 Sink 组件,如果想要保证 Exactly-once 的话,则这些组件本身应支持这种语义。
1. CheckPoint 原理
Flink 中基于异步轻量级的分布式快照技术提供了 Checkpoints容错机制,分布式快照可以将同一时间点 Task/Operator 的状态数据全局统一快照处理,包括前面提到的 Keyed State和 Operator State。Flink 会在输入的数据集上间隔性地生成 checkpoint barrier, 通过栅栏(barrier)将间隔时间段内的数据划分到相应的 checkpoint 中。如下图:
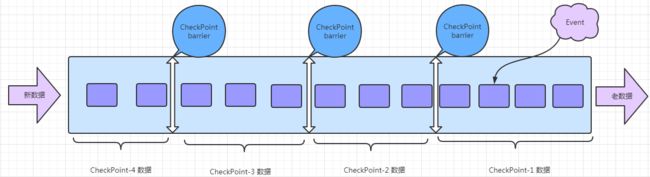
比如序列偶数求和跟奇数求和:

2. CheckPoint 参数和设置
默认情况下 Flink 不开启检查点的,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数:
-
Checkpoint 开启和时间间隔指定: 开启检查点并且指定检查点时间间隔为 1000ms,根据实际情况自行选择,如果状态比较大,则建议适当增加该值。
streamEnv.enableCheckpointing(1000) -
exactly-ance和at-least-once语义选择:
选择 exactly-once 语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink 的性能也相对较弱,而 at-least-once 语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。 如下通过setCheckpointingMode()方法来设 定语义模式, 默认情况 使用的是 exactly-once 模式。
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACT LY_ONCE);
//或者
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LE AST_ONCE)
- Checkpoint 超时时间:
超时时间指定了每次 Checkpoint 执行过程中的上限时间范围,一旦 Checkpoint 执行时 间超过该阈值,Flink 将会中断 Checkpoint 过程,并按照超时处理。该指标可以通过setCheckpointTimeout方法设定,默认为10分钟。streamEnv.getCheckpointConfig.setCheckpointTimeout(50000) - 检查点之间最小时间间隔:
该参数主要目的是设定两个 Checkpoint 之间的最小时间间隔,防止出现例如状态数据过大而导致 Checkpoint 执行时间过长,从而导致 Checkpoint 积压过多,最终 Flink 应用密集地触发 Checkpoint 操作,会占用了大量计算资源而影响到整个应用的性能。
streamEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
- 最大并行执行的检查点数量:
通过setMaxConcurrentCheckpoints()方法设定能够最大同时执行的 Checkpoint 数量。 在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个 Checkpoint,进而提升 Checkpoint 整体的效率。
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
- 是否删除 Checkpoint 中保存的数据:
设置为RETAIN_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会保留 CheckPoint 数据,以便根据实际需要恢复到指定的 CheckPoint。 设置为DELETE_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会删除 CheckPoint 数据,只有 Job 执行失败的时候才会保存 CheckPoint。
//删除
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp ointCleanup.DELETE_ON_CANCELLATION)
//保留
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp ointCleanup.RETAIN_ON_CANCELLATION)
- TolerableCheckpointFailureNumber:
设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务。
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
3. 保存机制 StateBackend(状态后端)
默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint会存储在 JobManager的内存中。State和 CheckPoint的存储位置取决于StateBackend的配置。Flink 一共提供 了 3 种 StateBackend。包括基于内存的 MemoryStateBackend、基于文件系统的FsStateBackend,以及基于 RockDB 作为存储介质的 RocksDBState-Backend。
1. MemoryStateBackend
基于内存的状态管理具有非常快速和高效的特点,但也具有非常多的限制,最主要的就 是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个 应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法 恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用 MemoryStateBackend。
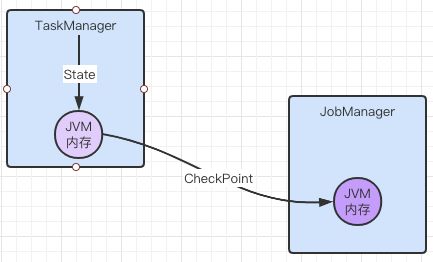
// 设定存储空间为10G
streamEnv.setStateBackend(new MemoryStateBackend(10*1024*1024))
2. FsStateBackend
和 MemoryStateBackend有所不同,FsStateBackend 是基于文件系统的一种状态管理器, 这里的文件系统可以是本地文件系统,也可以是 HDFS 分布式文件系统。FsStateBackend 更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或 Key/value State 状态数据量非常大的场景。
TaskManager仍然使用内存保存数据,但是进行CheckPoint的时候是将数据保存到FS中。
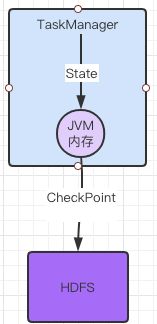
streamEnv.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/checkpoint/cp1"))
3. RocksDBStateBackend
RocksDBStateBackend 是 Flink 中内置的第三方状态管理器,和前面的状态管理器不同,RocksDBStateBackend 需要单独引入相关的依赖包到工程中。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_2.11artifactId>
<version>1.9.1version>
dependency>
RocksDBStateBackend 采用异步的方式进行状态数据的 Snapshot,任务中的状态数据首先被写入本地 RockDB 中,这样在 RockDB 仅会存储正在进行计算的热数据,而需要进行 CheckPoint 的时候,会把本地的数据直接复制到远端的 FileSystem 中。
与 FsStateBackend 相比,RocksDBStateBackend 在性能上要比 FsStateBackend 高一些,主要是因为借助于 RocksDB 在本地存储了最新热数据,然后通过异步的方式再同步到文件系 统中,但 RocksDBStateBackend和 MemoryStateBackend相比性能就会较弱一些。RocksDB 克服了 State 受内存限制的缺点,同时又能够持久化到远端文件系统中,推荐在生产中使用。
streamEnv.setStateBackend(new RocksDBStateBackend ("hdfs://hadoop101:9000/checkpoint/cp2"))

4. 全局配置 StateBackend
以上的代码都是单 job 配置状态后端,也可以全局配置状态后端,需要修改 flink-conf.yaml 配置文件:
state.backend: filesystem
filesystem 表示使用 FsStateBackend,
jobmanager 表示使用 MemoryStateBackend
rocksdb 表示使用 RocksDBStateBackend。
---
flink-conf.yaml 配置文件中
state.checkpoints.dir: hdfs://hadoop101:9000/checkpoints
默认情况下,如果设置了 CheckPoint 选项,则 Flink 只保留最近成功生成的 1 个 CheckPoint,而当 Flink 程序失败时,可以通过最近的 CheckPoint 来进行恢复。但是,如果希望保留多个CheckPoint,并能够根据实际需要选择其中一个进行恢复,就会更加灵活。 添加如下配置,指定最多可以保存的 CheckPoint 的个数。
state.checkpoints.num-retained: 2
4. Checkpoint案例
案例:设置 HDFS 文件系统的状态后端,取消 Job 之后再次恢复 Job。
使用WordCount案例来测试一下HDFS的状态后端,先运行一段时间Job,然后cancel,在重新启动,看看状态是否是连续的
package com.sowhat.flink.state
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestCheckPointByHDFS {
//使用WordCount案例来测试一下HDFS的状态后端,先运行一段时间Job,然后cancel,在重新启动,看看状态是否是连续的
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//开启CheckPoint并且设置一些参数
streamEnv.enableCheckpointing(5000) //每隔5秒开启一次CheckPoint
streamEnv.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/checkpoint/cp1")) //存放检查点数据
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
streamEnv.getCheckpointConfig.setCheckpointTimeout(5000)
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) //终止job保留检查的数据
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
//3、读取数据,读取sock流中的数据
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101", 8888) //DataStream ==> spark 中Dstream
//4、转换和处理数据
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" "))
.map((_, 1)).setParallelism(2)
.keyBy(0) //分组算子 : 0 或者 1 代表下标。前面的DataStream[二元组] , 0代表单词 ,1代表单词出现的次数
.sum(1).setParallelism(2) //聚会累加算子
//5、打印结果
result.print("结果").setParallelism(1)
//6、启动流计算程序
streamEnv.execute("wordcount")
}
}
打包上传到WebUI:
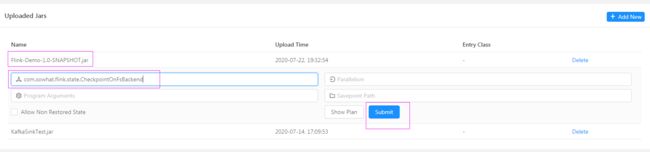
在nc -lk 8888 输入若干单词。然后查找 WebUI 的输出。然后通过WebUI将任务取消。最后尝试将任务重启。
./flink run -d -s hdfs://hadoop101:9000/checkpoint/cp1/精确到跟meta数据同级目录 -c com.sowhat.flink.state.CheckpointOnFsBackend /home/Flink-Demo-1.0-SNAPSHOT.jar
也可以通过WebUI 重启,指定 MainClass跟 CheckPoint即可。此处关键在于CheckPoint路径要写对!
5. SavePoint
Savepoints 是检查点的一种特殊实现,底层实现其实也是使用 Checkpoints 的机制。 Savepoints 是用户以手工命令的方式触发 Checkpoint,并将结果持久化到指定的存储路径 中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现从端到端的 Excatly-Once 语义保证。
配置 Savepoints 的存储路径
在 flink-conf.yaml 中配置 SavePoint 存储的位置,设置后,如果要创建指定 Job 的 SavePoint,可以不用在手动执行命令时指定 SavePoint 的位置。
state.savepoints.dir: hdfs:/hadoop101:9000/savepoints
在代码中设置算子 ID
为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐程序员 通过手动给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子 指定 ID,则会由 Flink 自动给每个算子生成一个 ID。而这些自动生成的 ID 依赖于程序的结 构,并且对代码的更改是很敏感的。因此,强烈建议用户手动设置 ID。
package com.sowhat.flink.state
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object TestSavePoints {
def main(args: Array[String]): Unit = {
//1、初始化Flink流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改并行度
streamEnv.setParallelism(1) //默认所有算子的并行度为1
//2、导入隐式转换
import org.apache.flink.streaming.api.scala._
//3、读取数据,读取sock流中的数据
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101",8888) //DataStream ==> spark 中Dstream
.uid("socket001")
//4、转换和处理数据
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" ")).uid("flatmap001")
.map((_, 1)).setParallelism(2).uid("map001")
.keyBy(0)//分组算子 : 0 或者 1 代表下标。前面的DataStream[二元组] , 0代表单词 ,1代表单词出现的次数
.sum(1).uid("sum001")
//5、打印结果
result.print("结果").setParallelism(1)
//6、启动流计算程序
streamEnv.execute("wordcount")
}
}
触发 SavePoint
//先启动Job
[root@hadoop101 bin]# ./flink run -c com.bjsxt.flink.state.TestSavepoints -d /home/Flink-Demo-1.0-SNAPSHOT.jar
[root@hadoop101 bin]# ./flink list 获取 job 对应ID
//再取消Job
[root@hadoop101 bin]# ./flink savepoint 6ecb8cfda5a5200016ca6b01260b94ce
// 触发SavePoint
[root@hadoop101 bin]# ./flink cancel 6ecb8cfda5a5200016ca6b01260b94ce
从 SavePoint 启动 Job
大致方法跟上面的CheckPoint启动Job类似。
6. 总结
若干个常用的状态算子大致如何存储的要了解。
CheckPoint的原理主要是图示,理解如何保证精准一致性的。
CheckPoint一般有基于内存的,基于HDFS的跟基于DB的,整体来说基于DB的把数据存储早DB中跟HDFS中是最好的。
SavePoint是手动触发的CheckPoint,一般方便线上迁移的功能等,并且尽量给每一个算子自定义一个UID,
6. Window 窗口
无界数据变为若干个有界数据。Windows 计算是流式计算中非常常用的数据计算方式之一,通过按照固定时间或长度将数据流切分成不同的窗口,然后对数据进行相应的聚合运算,从而得到一定时间范围内的统计结果。例如统计最近 5 分钟内某基站的呼叫数,此时基站的数据在不断地产生,但是通过 5 分钟的窗口将数据限定在固定时间范围内,就可以对该范围内的有界数据执行聚合处理, 得出最近 5 分钟的基站的呼叫数量。
1. Window分类
1. Global Window 和 Keyed Window
在运用窗口计算时,Flink根据上游数据集是否为KeyedStream类型,对应的Windows 也 会有所不同。
- Keyed Window: 上游数据集如果是 KeyedStream 类型,则调用 DataStream API 的
window()方法,数据会根据 Key 在不同的 Task 实例中并行分别计算,最后得出针对每个 Key 统计的结果。 - Global Window:如果是 Non-Keyed 类型,则调用
WindowsAll()方法,所有的数据都会在窗口算子中由到一个 Task 中计算,并得到全局统计结果。
//读取文件数据
val data = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
.map(line=>{
var arr =line.split(",") new
StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to Long)
})
//Global Window
data.windowAll(自定义的WindowAssigner)
//Keyed Window
data.keyBy(_.sid).window(自定义的WindowAssigner)
2. Time Window 和 Count Window
基于业务数据的方面考虑,Flink 又支持两种类型的窗口,一种是基于时间的窗口叫Time Window。还有一种基于输入数据数量的窗口叫 Count Window
3. Time Window(时间窗口)
根据不同的业务场景,Time Window 也可以分为三种类型,分别是滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)
- 滚动窗口(Tumbling Window)
滚动窗口是根据固定时间进行切分,且窗口和窗口之间的元素互不重叠。这种类型的窗 口的最大特点是比较简单。只需要指定一个窗口长度(window size)。
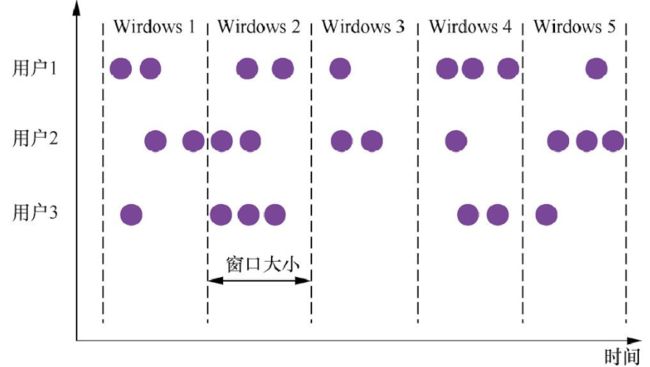
//每隔5秒统计每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
//.window(TumblingEventTimeWindows.of(Time.seconds(5))) 跟上面同样功能
.sum(1) //聚合
其中时间间隔可以是 Time.milliseconds(x)、Time.seconds(x)或 Time.minutes(x)。
- 滑动窗口(Sliding Window)
滑动窗口也是一种比较常见的窗口类型,其特点是在滚动窗口基础之上增加了窗口滑动时间(Slide Time),且允许窗口数据发生重叠。当 Windows size 固定之后,窗口并不像 滚动窗口按照 Windows Size 向前移动,而是根据设定的 Slide Time 向前滑动。窗口之间的 数据重叠大小根据 Windows size 和 Slide time 决定,当 Slide time 小于 Windows size 便会发生窗口重叠,Slide size 大于 Windows size 就会出现窗口不连续,数据可能不能在 任何一个窗口内计算,Slide size 和 Windows size 相等时,Sliding Windows 其实就是 Tumbling Windows。

//每隔3秒计算最近5秒内,每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5),Time.seconds(3)) //.window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(3)))
.sum(1)
- 会话窗口(Session Window)
会话窗口(Session Windows)主要是将某段时间内活跃度较高的数据聚合成一个窗口 进行计算,窗口的触发的条件是Session Gap,是指在规定的时间内如果没有数据活跃接入, 则认为窗口结束,然后触发窗口计算结果。需要注意的是如果数据一直不间断地进入窗口, 也会导致窗口始终不触发的情况。与滑动窗口、滚动窗口不同的是,Session Windows 不需 要有固定 windows size 和 slide time,只需要定义 session gap,来规定不活跃数据的时 间上限即可。
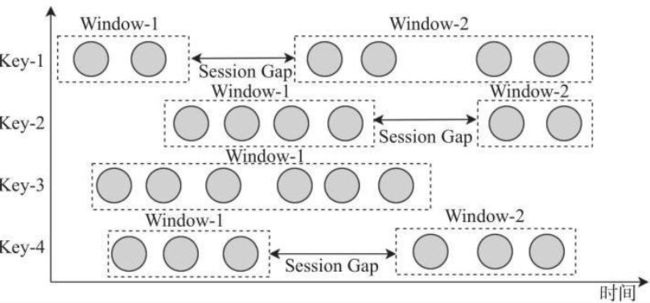
//3秒内如果没有数据进入,则计算每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1).window(EventTimeSessionWindows.withGap(Time.seconds(3))).sum(1)
4. Count Window(数量窗口)
Count Window 也有滚动窗口、滑动窗口等。由于使用比较少TODO,比如五条数据算一批次这样的统计。
2. Window的API
在以后的实际案例中 Keyed Window使用最多,所以我们需要掌握 Keyed Window 的算子, 在每个窗口算子中包含了 Windows Assigner、Windows Trigger(窗口触发器)、Evictor (数据剔除器)、Lateness(时延设定)、Output Tag(输出标签)以及 Windows Funciton 等组成部分,其中 Windows Assigner 和 Windows Funciton 是所有窗口算子必须指定的属性, 其余的属性都是根据实际情况选择指定。
stream.keyBy(...) // 是Keyed类型数据集
.window(...) //指定窗口分配器类型
[.trigger(...)] //指定触发器类型(可选)
[.evictor(...)] //指定evictor或者不指定(可选)
[.allowedLateness(...)] //指定是否延迟处理数据(可选)
[.sideOutputLateData(...)] //指定Output Lag(可选)
.reduce/aggregate/fold/apply() //指定窗口计算函数
[.getSideOutput(...)] //根据Tag输出数据(可选)
- Windows Assigner: 指定窗口的类型,定义如何将数据流分配到一个或多个窗口。
- Windows Trigger: 指定窗口触发的时机,定义窗口满足什么样的条件触发计算。
- Evictor: 用于数据剔除。
- allowedLateness: 标记是否处理迟到数据,当迟到数据到达窗口中是否触发计算。
- Output Tag: 标记输出标签,然后在通过 getSideOutput 将窗口中的数据根据标签输出。
- Windows Funciton: 定义窗口上数据处理的逻辑,例如对数据进行 sum 操作。
3. 窗口聚合函数
如果定义了 Window Assigner 之后,下一步就可以定义窗口内数据的计算逻辑,这也就是 Window Function 的定义。Flink 中提供了四种类型的 Window Function,分别为 ReduceFunction、AggregateFunction 以及 ProcessWindowFunction,(sum 和 max)等。 前三种类型的 Window Fucntion 按照计算原理的不同可以分为两大类:
- 一类是增量聚合函数:对应有
ReduceFunction、AggregateFunction; - 另一类是全量窗口函数,对应有
ProcessWindowFunction(还有WindowFunction)。
增量聚合函数计算性能较高,占用存储空间少,主要因为基于中间状态的计算结果,窗口中只维护中间结果状态值,不需要缓存原始数据。而全量窗口函数使用的代价相对较高, 性能比较弱,主要因为此时算子需要对所有属于该窗口的接入数据进行缓存,然后等到窗口触发的时候,对所有的原始数据进行汇总计算。
1. ReduceFunction
Reduce要求输入跟输出类型要一样!这点切记。
需求:每隔5秒统计每个基站的日志数量
object TestReduceFunctionByWindow {
//每隔5秒统计每个基站的日志数量
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("hadoop101", 8888)
.map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//开窗
stream.map(log => ((log.sid, 1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5)) //开窗
.reduce((t1, t2) => (t1._1, t1._2 + t2._2))
.print()
streamEnv.execute()
}
}
2. AggregateFunction
和 ReduceFunction 相似,AggregateFunction 也是基于中间状态计算结果的增量计算 函数,但 AggregateFunction 在窗口计算上更加通用。AggregateFunction 接口相对 ReduceFunction 更加灵活,输入跟输出类型不要求完全一致,实现复杂度也相对较高。AggregateFunction 接口中定义了三个 需要复写的方法,其中 add()定义数据的添加逻辑,getResult 定义了根据 accumulator 计 算结果的逻辑,merge 方法定义合并 accumulator 的逻辑。初始化,分区内如何处理,分区间如何处理,最终如何输出。
需求:每隔3秒计算最近5秒内,每个基站的日志数量
object TestAggregatFunctionByWindow {
//每隔3秒计算最近5秒内,每个基站的日志数量
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("hadoop101", 8888)
.map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//开窗
val value: DataStream[(String, Long)] = stream.map(log => ((log.sid, 1)))
.keyBy(_._1)
.window(SlidingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(3))) //开窗,滑动窗口
.aggregate(new MyAggregateFunction, new MyWindowFunction) // 到底是数字对应哪个基站
// aggregate(增量函数,全量函数)
value.print()
streamEnv.execute()
}
/**
* 里面的add方法,是来一条数据执行一次,getResult在窗口结束的时候执行一次
* in,累加器acc,out
* https://blog.csdn.net/chilimei8516/article/details/100796930
*/
class MyAggregateFunction extends AggregateFunction[(String, Int), Long, Long] {
override def createAccumulator(): Long = 0 //初始化一个累加器 acc,开始的时候为0
// 分区内操作
override def add(value: (String, Int), accumulator: Long): Long = accumulator + value._2
// 结果返回
override def getResult(accumulator: Long): Long = accumulator
// 分区间操作
override def merge(a: Long, b: Long): Long = a + b
}
// WindowFunction 输入数据来自于AggregateFunction ,
// 在窗口结束的时候先执行AggregateFunction对象的getResult,然后再执行apply
// in,out,key,window
class MyWindowFunction extends WindowFunction[Long, (String, Long), String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[(String, Long)]): Unit = {
out.collect((key, input.iterator.next())) //next得到第一个值,迭代器中只有一个值
}
}
}
3. ProcessWindowFunction
前面提到的ReduceFunction和 AggregateFunction 都是基于中间状态实现增量计算的 窗口函数,虽然已经满足绝大多数场景,但在某些情况下,统计更复杂的指标可能需要依赖于窗口中所有的数据元素,或需要操作窗口中的状态数据和窗口元数据,这时就需要使用到 ProcessWindowsFunction,ProcessWindowsFunction能够更加灵活地支持基于窗口全部数据元素的结果计算 , 例如对整个窗口 数 据排序取TopN, 这样的需要就必须使用ProcessWindowFunction。
需求:每隔5秒统计每个基站的日志数量
object TestProcessWindowFunctionByWindow {
//每隔5秒统计每个基站的日志数量
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
streamEnv.setParallelism(1)
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("hadoop101", 8888)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//开窗
stream.map(log => ((log.sid, 1)))
.keyBy(_._1) // .timeWindow(Time.seconds(5))//开窗
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction[(String, Int), (String, Long), String, TimeWindow] {
//一个窗口结束的时候调用一次(一个分组执行一次) in,out,key,windows
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Long)]): Unit = {
println("------------")
//注意:整个窗口的数据保存到Iterable,里面有很多行数据。Iterable的size就是日志的总条数
out.collect((key, elements.size))
}
}).print()
streamEnv.execute()
}
}
需求:窗口函数读数据然后将数据写入到neo4j,感觉其实应该用 自定的Sink 更合适一些。
object DealDataFromKafka {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
val properties: Properties = new Properties()
properties.setProperty("bootstrap.servers", "IP1:9092,IP2:9092")
properties.setProperty("group.id", "timer")
// 从最新数据开始读
properties.setProperty("auto.offset.reset", "latest")
//val dataStream: DataStream[String] = environment.addSource(new FlinkKafkaConsumer011[String]("sowhat", new SimpleStringSchema(), properties))
val dataStream: DataStream[String] = environment.socketTextStream("IP", 8889)
val winData: AllWindowedStream[String, TimeWindow] = dataStream.timeWindowAll(Time.seconds(4))
var pre: Int = 0
var tmp: Int = 0
val timeWithHashCode: DataStream[(Int, String)] = winData.process(new ProcessAllWindowFunction[String, (Int, String), TimeWindow]() {
override def process(context: Context, elements: Iterable[String], out: Collector[(Int, String)]): Unit = {
val driver: Driver = GraphDatabase.driver("bolt://IP:9314", AuthTokens.basic("neo4j", "neo4j0fcredithc"))
val session: Session = driver.session()
elements.foreach(value => {
tmp += 1
var now: Int = value.hashCode
now = tmp
session.run(s"CREATE (a:Test {id:${now}, time:'${value}'})")
if (pre != 0) {
session.run(s"MATCH (begin:Test{id:${pre}}) ,(end:Test{id:${now}}) MERGE (begin)-[like:Time_Link]->(end)")
}
out.collect((tmp, s" MATCH (begin:Test{id:${pre}}) ,(end:Test{id:${now}}) MERGE (begin)-[like:Time_Link]->(end)"))
pre = now
}
)
// session.close()
// driver.close()
}
})
timeWithHashCode.print("HashCode With time:")
environment.execute("getData")
}
}
End
窗口的分类从不同的维度来说,
- 上游是否为KeyedStream,不同数据集调用不同方法。
- 根据上游数据是时间窗口(滚动窗口、滑动窗口、会话窗口)还是数据量窗口。
- 窗口若干API调用方法,窗口的聚合函数(reduceFunction、AggregateFunction、ProcessWindowFunction、WindowFunction)。