R语言数据合并
用向量创建数据框

id<-c("1","2","3","4")
name<-c("谈天","轻衣","晓光","余白")
is.vector(name)
data00=data.frame(id,name)
str(data00)
head(data00)
创建第二个数据框
id<-c("5","6","7","8")
name<-c("青梅","王五","不二","七杀")
is.vector(name)
data11=data.frame(id,name)
str(data11)
head(data11)

纵向合并数据框data00和data11
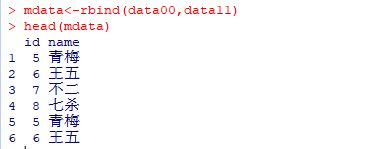
mdata<-rbind(data00,data11)
head(mdata)
其它纵向数据框合并
使用dplyr包中的bind_rows()函数进行合并
library(dplyr)
dplyr::bind_rows(data00,data11)
字段连接横向合并(id和name合并成新字段)
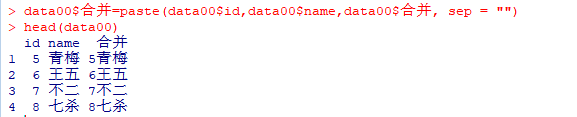
data00$合并=paste(data00$id,data00$name,data00$合并, sep = "")
head(data00)
数据字段框的横向合并(通过相同的元素,横向合并)
字段数数据框的横向id关联合并data11和data33合并,有相同的id,进行合并


方法一:merge函数
merge(x, y, by = intersect(names(x), names(y)),
by.x = by, by.y = by, all = FALSE,
all.x = all, all.y = all,
sort = TRUE, suffixes = c(".x",".y"),
incomparables = NULL, ...)
参数说明:
x,y:用于合并的两个数据框
by,by.x,by.y:指定依据哪些行合并数据框,默认值为相同列名的列.
all,all.x,all.y:指定x和y的行是否应该全在输出文件.
sort:by指定的列是否要排序.
suffixes:指定除by外相同列名的后缀.
incomparables:指定by中哪些单元不进行合并.
例如:
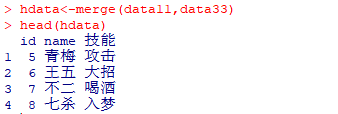
hdata<-merge(data11,data33,by=id)
head(hdata)
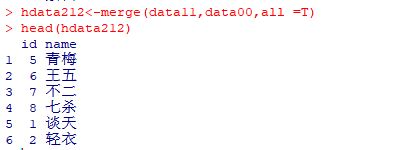
hdata212<-merge(data11,data00,all =T)
head(hdata212)
方法二:cbind函数
hdata2<-cbind(data11,data33)
head(hdata2)

数据终极合并:SQL的使用
library(sqldf)
data=sqldf("select * from data1 t1,data2 t2 where t1.id=t2.id")