大数据各组件理论性总结---spark和hadoop(将持续更新)
Hadoop和spark的起源
Hadoop起源
1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司
无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene
Lucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(代码公开),非常受程序员们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源软件网站)。后来,2001年底,Lucene成为Apache软件基金会jakarta项目的一个子项目。
2004年,Doug Cutting再接再励,在Lucene的基础上,和Apache开源伙伴Mike Cafarella合作,开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch
Nutch是一个建立在Lucene核心之上的网页搜索应用程序,可以下载下来直接使用。它在Lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业界的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。
尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。
在这个过程中,Google也确实找到了不少好办法,并且无私地分享了出来。
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)
还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。
这里要补充说明一下雅虎招安Doug的背景:2004年之前,作为互联网开拓者的雅虎,是使用Google搜索引擎作为自家搜索服务的。在2004年开始,雅虎放弃了Google,开始自己研发搜索引擎。所以。。。
加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。而Doug Cutting,则被人们称为Hadoop之父
Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。
所以我们看到的hadoop的图标是

包括后面的一些组件,如hive的黄蜂,HBASE的海豚等等,都是动物,因此我们在私下戏称动物园的管理员、搬运工、饲养员等
我们继续往下说。
还是2006年,Google又发论文了。
这次,它们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase

好吧,反正就是紧跟Google时代步伐,你出什么,我学什么。所以,Hadoop的核心部分,基本上都有Google的影子。
所以,Hadoop的核心部分,基本上都有Google的影子。

2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目。
同年2月,Yahoo宣布建成了一个拥有1万个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面。
7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时209秒。
此后,Hadoop便进入了高速发展期,直至现在。
Hadoop的发展史
2002 年 10 月,Doug Cutting 和 Mike Cafarella 创建了开源网页爬虫项目 Nutch。
2003 年 10 月,Google 发表 Google File System 论文。
2004 年 7 月,Doug Cutting 和 Mike Cafarella 在 Nutch 中实现了类似 GFS 的功能,即后来 HDFS 的前身。
2004 年 10 月,Google 发表了 MapReduce 论文。
2005 年 2 月,Mike Cafarella 在 Nutch 中实现了 MapReduce 的最初版本。
2005 年 12 月,开源搜索项目 Nutch 移植到新框架,使用 MapReduce 和 NDFS(Nutch Distributed File System ) 来运行,在 20 个节点稳定运行。
2006 年 1 月,Doug Cutting 加入雅虎,Yahoo! 提供一个专门的团队和资源将 Hadoop 发展成一个可在网络上运行的系统。
2006年 2月,Apache Hadoop项目正式启动以支持 MapReduce和 HDFS**** 的独立发展。
2006 年 2 月,Yahoo! 的网格计算团队采用 Hadoop。
2006 年 3 月,Yahoo! 建设了第一个 Hadoop 集群用于开发。
2006 年 4 月,第一个 Apache Hadoop 发布。
2006 年 4 月,在 188 个节点上(每个节点 10GB)运行排序测试集需要 47.9 个小时。
2006 年 5 月,Yahoo! 建立了一个 300 个节点的 Hadoop 研究集群。
2006 年 5 月,在 500 个节点上运行排序测试集需要 42 个小时(硬件配置比 4 月的更好)。
2006 年 11 月,研究集群增加到 600 个节点。
2006 年 11 月,Google 发表了 Bigtable 论文,这最终激发了 HBase 的创建。
2006 年 12 月,排序测试集在 20 个节点上运行 1.8 个小时,100 个节点上运行 3.3 小时,500 个节点上运行 5.2 小时,900 个节点上运行 7.8 个小时。
2007 年 1 月,研究集群增加到 900 个节点。
2007 年 4 月,研究集群增加到两个 1000 个节点的集群。
2007年 10月,第一个 Hadoop**** 用户组会议召开,社区贡献开始急剧上升。
2007 年,百度开始使用 Hadoop 做离线处理。
2007 年,中国移动开始在“大云”研究中使用 Hadoop 技术。
2008 年,淘宝开始投入研究基于 Hadoop 的系统——云梯,并将其用于处理电子商务相关数据。
2008年 1月,Hadoop成为 Apache顶级项目。
2008 年 2 月,Yahoo! 运行了世界上最大的 Hadoop 应用,宣布其搜索引擎产品部署在一个拥有 1 万个内核的 Hadoop 集群上。
2008 年 4 月,在 900 个节点上运行 1TB 排序测试集仅需 209 秒,成为世界最快。
2008 年 6 月,Hadoop 的第一个 SQL 框架——Hive 成为了 Hadoop 的子项目。
2008 年 7 月,Hadoop 打破 1TB 数据排序基准测试记录。Yahoo! 的一个 Hadoop 集群用 209 秒完成 1TB 数据的排序 ,比上一年的纪录保持者保持的 297 秒快了将近 90 秒。
2008年 8月,第一个 Hadoop商业化公司 Cloudera成立。
2008 年 10 月,研究集群每天装载 10TB 的数据。
2008 年 11 月,Apache Pig 的最初版本发布。
2009 年 3 月,17 个集群总共 24000 台机器。
2009 年 3月,Cloudera推出世界上首个 Hadoop发行版——CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成。
2009 年 4 月,赢得每分钟排序,59 秒内排序 500GB(在 1400 个节点上)和 173 分钟内排序 100TB 数据(在 3400 个节点上)。
2009 年 5 月,Yahoo 的团队使用 Hadoop 对 1 TB 的数据进行排序只花了 62 秒时间。
2009 年 6 月,Cloudera 的工程师 Tom White 编写的《Hadoop 权威指南》初版出版,后被誉为 Hadoop 圣经。
2009 年 7 月 ,Hadoop Core 项目更名为 Hadoop Common;
2009 年 7 月 ,MapReduce 和 Hadoop Distributed File System (HDFS) 成为 Hadoop 项目的独立子项目。
2009 年 7 月 ,Avro 和 Chukwa 成为 Hadoop 新的子项目。
2009 年 8 月,Hadoop 创始人 Doug Cutting 加入 Cloudera 担任首席架构师。
2009 年 10 月,首届 Hadoop World 大会在纽约召开。
2010 年 5 月 ,Avro 脱离 Hadoop 项目,成为 Apache 顶级项目。
2010 年 5 月 ,HBase 脱离 Hadoop 项目,成为 Apache 顶级项目。
2010 年 5 月,IBM 提供了基于 Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2010 年 9 月,Hive( Facebook) 脱离 Hadoop,成为 Apache 顶级项目。
2010 年 9 月,Pig 脱离 Hadoop,成为 Apache 顶级项目。
2010年 -2011年,扩大的 Hadoop社区忙于建立大量的新组件(Crunch,Sqoop,Flume**,Oozie等)来扩展 Hadoop的使用场景和可用性。**
2011 年 1 月,ZooKeeper 脱离 Hadoop,成为 Apache 顶级项目。
2011 年 3 月,Apache Hadoop 获得 Media Guardian Innovation Awards 。
2011 年 3 月, Platform Computing 宣布在它的 Symphony 软件中支持 Hadoop MapReduce API。
2011年 5月,Mapr Technologies公司推出分布式文件系统和 MapReduce引擎——MapR Distribution for Apache Hadoop。
2011 年 5 月,HCatalog 1.0 发布。该项目由 Hortonworks 在 2010 年 3 月份提出,HCatalog 主要用于解决数据存储、元数据的问题,主要解决 HDFS 的瓶颈,它提供了一个地方来存储数据的状态信息,这使得 数据清理和归档工具可以很容易的进行处理。
2011 年 4 月,SGI(Silicon Graphics International)基于 SGI Rackable 和 CloudRack 服务器产品线提供 Hadoop 优化的解决方案。
2011 年 5 月,EMC 为客户推出一种新的基于开源 Hadoop 解决方案的数据中心设备——GreenPlum HD,以助其满足客户日益增长的数据分析需求并加快利用开源数据分析软件。Greenplum 是 EMC 在 2010 年 7 月收购的一家开源数据仓库公司。
2011 年 5 月,在收购了 Engenio 之后, NetApp 推出与 Hadoop 应用结合的产品 E5400 存储系统。
2011 年 6 月,Calxeda 公司发起了“开拓者行动”,一个由 10 家软件公司组成的团队将为基于 Calxeda 即将推出的 ARM 系统上芯片设计的服务器提供支持。并为 Hadoop 提供低功耗服务器技术。
2011 年 6 月,数据集成供应商 Informatica 发布了其旗舰产品,产品设计初衷是处理当今事务和社会媒体所产生的海量数据,同时支持 Hadoop。
2011年 7月,Yahoo!和硅谷风险投资公司 Benchmark Capital创建了 Hortonworks 公司,旨在让 Hadoop更加可靠,并让企业用户更容易安装、管理和使用 Hadoop。
2011 年 8 月,Cloudera 公布了一项有益于合作伙伴生态系统的计划——创建一个生态系统,以便硬件供应商、软件供应商以及系统集成商可以一起探索如何使用 Hadoop 更好的洞察数据。
2011 年 8 月,Dell 与 Cloudera 联合推出 Hadoop 解决方案——Cloudera Enterprise。Cloudera Enterprise 基于 Dell PowerEdge C2100 机架服务器以及 Dell PowerConnect 6248 以太网交换机。
2012 年 3 月,企业必须的重要功能 HDFS NameNode HA 被加入 Hadoop 主版本。
2012 年 8 月,另外一个重要的企业适用功能 YARN 成为 Hadoop 子项目。
2012 年 10 月,第一个 Hadoop 原生 MPP 查询引擎 Impala 加入到了 Hadoop 生态圈。
2014年 2月,Spark逐渐代替 MapReduce成为 Hadoop的缺省执行引擎,并成为 Apache基金会顶级项目。
2015 年 2 月,Hortonworks 和 Pivotal 抱团提出“Open Data Platform”的倡议,受到传统企业如 Microsoft、IBM 等企业支持,但其它两大 Hadoop 厂商 Cloudera 和 MapR 拒绝参与。
2015 年 10 月,Cloudera 公布继 HBase 以后的第一个 Hadoop 原生存储替代方案——Kudu。
2015 年 12 月,Cloudera 发起的 Impala 和 Kudu 项目加入 Apache 孵化器。
Spark的起源
Spark是在Matei Zaharia的博士论文《An Architecture for Fast and General Data Processing on Large Cluster》(大型集群上 的快速和通过数据处理架构)的基础上发展而来。
2009年,Spark起源于加州大学伯克利分校的 实验室(AMPLab)。
2010年,Spark成为开源项目。 2013年,Spark被捐赠给Apache软件基金会。 同年,Databricks公司成立。
2014年,Spark称为Apache的顶级项目。
Spark和Hadoop对比
先声明
1、Hadoop中含有三个模块:HDFS、Yarn以及MapReduce
2、Spark不会取代Hadoop,而是会取代MapReduce
所以spark和hadoop的对比,更多的指的是spark和MapReduce的对比
Spark和MapReduce的区别如下:
1、MapReduce是基于磁盘的,而Spark是基于内存的,但是并不是说Spark的shuffle不会写磁盘,Spark的Shuffle过程和MapReduce类似,仍然会写磁盘,只是Spark在使用内存方面比MapReduce用的更好点,特别是在迭代计算的应用中,Spark可以显示的将任何的RDD缓存在内存中,使得Spark的速度远远超过MapReduce
2、Spark的API比MapReduce丰富、灵活多了,所以Spark的应用比MapReduce更加的简洁
3、Spark的任务是线程级别的,而MapReduce默认情况下的Task是是JVM级别的,启动一个JVM肯定比启动一个线程要慢很多,这也是MapReduce慢的原因
4、MapReduce相对来说更加稳定点,对内存要求不高,如果你的的应用对时间要求不高,或者你的内存资源不够,这个时候可以使用MapReduce
Hadoop的核心组件

早在hadoop1.0时代,这些组件都还不是很成熟,也不是现在这个架构,在2.0的时候才是这个架构图
Hadoop1.0和2.0的最大区别就是:yarn的资源调度在1.0只是一个task,负责管理着整个集群的资源(CPU和内存),所以它很容易就会遇到瓶颈,在2.0的时候,就单独的把yarn给拿出来,作为一个单独的模块,也可以说成JobTracker和TaskTracker变成了RM(resourceManager)和NM(nodeManager)
Hdfs的架构
Hdfs的安装
参考:https://blog.csdn.net/weixin_42411818/article/details/95208939
NameNode(nn)
存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。PS:这个是非常重要的,一旦它挂掉,整个HDFS文件系统也就挂掉了,类似于hive,hbase等依赖于它的组件都会无法正常使用,所以一般我们在生产上都会采用高可用的方式(ZK+JNODE)详情见我的博客:https://blog.csdn.net/weixin_42411818/article/details/95619563
注意配置了高可用再使用hdfs接口的时候,就尽量不要写成:hdfs://master:9999/路径
而要写成hdfs://mycluster
生产上如何规划NameNode
1.NameNode维护这两层关系:第一层关系是HDFS文件系统的文件目录树,以及文件数据块的索引,即每一个文件对应的数据块列表;第二层关系是数据块与数据节点的关系,即某一数据块保存在哪些数据节点中
2.所以我们在规划的时候,就要预算一下我们的文件个数,详细的规划见:https://blog.csdn.net/weixin_42411818/article/details/105880422
DataNode(dn)
在本地文件系统存储文件块数据,以及块数据的校验
当datanode短期的挂掉是不会影响集群的运行的,可能会出现:有些job运行特别慢,这个可能就是机器的DataNode挂掉了,而任务刚好分配到了这个机器上,为了让任务继续运行,这个任务就会去其他机器拉取数据过来运行,可以参考spark的计算任务的本地性
挂掉之后也不用慌张,查看日志,分析原因,短期挂掉重启,长期挂掉,这个时候这个节点的数据肯定已经被重新备份了,所以需要删除这个节点下的磁盘数据,路径详见CDH上的配置,然后重启,使之变成一个新的DataNode,然后做数据平衡,参考:https://blog.csdn.net/weixin_42411818/article/details/103254751
,https://www.ibm.com/developerworks/cn/data/library/bd-1506-hdfsdatabalance/index.html
Secondary NameNode(2nn)
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
这个进程是为了协助NameNode管理元数据的,NameNode为了我们的元数据不丢失,会写Edits Log,使得这些元数据持久化到文件中,当Edits Log越来越大的时候,超过指定的配置大小的时候,需要合并Edits Log,在只有一个NameNode的情况下,这个合并Edits Log的任务就交给了Secondary NameNode了,最终Secondary NameNode会将Edits Log合并成FSimage文件。所以说Secondary NameNode并不是NameNode的备用NameNode,而是辅助NameNode合并Edits Log,帮助NameNode减负的节点。NameNode在启动的时候,会去加载合并之后的FSimage文件,将FSimage文件中的元数据加载进内存中
浅谈NameNode和DataNode之间的操作
1、register : 将自身的一些信息(hostname, version等)告诉name node,name node经过check后使其成为集群中的一员
2、block report :将block的信息汇报给name node,使得name node可以维护数据块和数据节点之间的映射关系
3、定期的send heartbeat :告诉name node我还活着,我的存储空间还有多少等信息以及执行name node通过heartbeat传过来的指令,比如删除数据块
Hdfs写数据的流程
文字的简单总结:
1、client端和namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client会先对文件进行切分,比如一个blok块128m,文件有300m就会被切分成3个块,一个128M、一个128M、一个44M请求第一个 block该传输到哪些datanode服务器上
4、namenode返回datanode的服务器
5、client请求一台datanode上传数据,第一个datanode收到请求会继续调用第二个datanode,然后第二个调用第三个datanode,将整个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(一个packet为64kb),当然在写入的时候datanode会进行数据校验,它并不是通过一个packet进行一次校验而是以chunk为单位进行校验(512byte),第一台datanode收到一个packet就会传给第二台,第二台传给第三台;第一台每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。

找到数据块存储离客户端最近的DataNode,可以通过网络拓扑结构节点之间的距离来计算

Hdfs读数据的流程
文字总结:
1、跟namenode通信查询元数据(block所在的datanode节点),找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,先在本地缓存,然后写入目标文件,后面的block块就相当于是append到前面的block块最后合成最终需要的文件

NameNode工作机制

DataNode工作机制

YARN架构
Yarn安装
参考:https://blog.csdn.net/weixin_42411818/article/details/95961033
Yarn架构
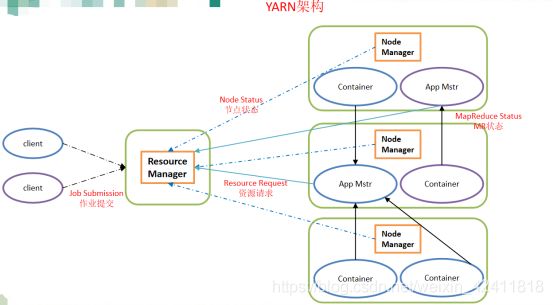
如图:一个yarn是以RM为核心,多个NM,其中的AM就是我们的应用,CT就是我们运行AM的容器,后面会讲解到
YARN工作机制

文字总结:
1、用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2、ResourceManager为该应用程序分配第一个Container(这里可以理解为一种资源比如内存),并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
3、ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7
4、ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
5、一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
6.NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7.各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
8.应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
Yarn调度机制
1.FIFO Scheduler:Job执行顺序先进先出方式,当前面的job占用了全部内存时,后面的job就只能等着,这是默认的调度机制,显然这种机制不适合在生产上使用
2.Capacity Scheduler :树状结构的分组形式,为每一组分配资源,我目前使用的就是此种模式
3.Fair Scheduler:公平调度机制,根据权重获得额外的空闲资源,一般也有很多人使用这种机制(CDH默认使用)
FIFO

容量调度器(我们现在用的)

公平调度器(CDH默认)

Yarn中container的分配规则
我们可以通过下面的命令向Yarn集群中提交一个应用:
hadoop fs -rm -r /user/hadoop-jrq/mr/count/output(不先删除会报错)
yarn jar mapreduce-study-1.0-SNAPSHOT.jar com.jrq.DistributedCount /user/hadoop-jrq/mr/count/input /user/hadoop-jrq/mr/count/output
当我们执行上面的命令后,然后查看Yarn的Web UI上可以发现,slave1和slave2上都给上面的MapReduce分配了一个Container来跑MRAppMaster和Map、Reduce Task,如下图:

那么什么是container呢?
Yarn给一个应用程序分配资源的时候的最小单位就是container,一个container中包含了一定大小的内存和一定数量的CPU核心数。
我们先看一个MapReduce在Yarn上跑的一个流程图:

1.Yarn集群启动的时候,NodeManager将自己管理的资源汇报给ResourceManager,这样ResourceManager就知道整个Yarn集群管理的资源情况了
2.在客户端机器上提交一个MapReduce程序,提交的程序先去ResourceManager申请资源
3.ResourceManager接收到客户端的资源申请,判断资源是否足够,如果足够的话则在资源足够的NodeManager上分配一个container用来运行MRAppMaster进程
4.MRAppMaster根据当前的MapReduce的输入文件和配置来决定要启动几个Map Task和几个Reduce Task。然后向ResourceManager申请跑Map Task和Reduce Task需要的资源
5.申请到的资源也是以container为单位进行分配,在资源足够的NodeManager上分配相应数量的container用来运行Map Task和Reduce Task进程
上图中,向Yarn集群提交了两个MapReduce程序,分别启动了两个container用于运行MRAppMaster进程,一个MRAppMaster启动一个container用于跑Map Task;另一个MRAppMaster启动了3个container,其中两个container用于运行Map Task,另一个container用于运行Reduce Task
既然Yarn给一个应用程序分配资源的时候的最小单位就是container,这个container资源大小的分配规则是怎样的呢?也就是说每次向ResourceManager申请到的container的内存多大以及CPU核心数多少呢?
container资源大小的分配规则
规则一:最小最大规则
首先我们要知道整个Yarn集群管理的内存和CPU核心数大小,看看上面安装中我的博客里写到的两个参数(PS:这些参数在CDH中都是统一进行管理的)

APACHE版本的配置:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1630</value>
<description>表示这个NodeManager管理的内存大小</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>表示这个NodeManager管理的虚拟核心个数</description>
</property>
从上可以看出,每一个NodeManager管理的内存大小是1630MB,每一个NodeManager管理的CPU核心数是2个。我们的Yarn集群中有两个NodeManager,所以整个Yarn集群管理的内存是1630MB * 2 约等于3.18GB,管理的CPU核心数是2个 * 2 = 4个。我们从Yarn的WEB UI上也可以看到:
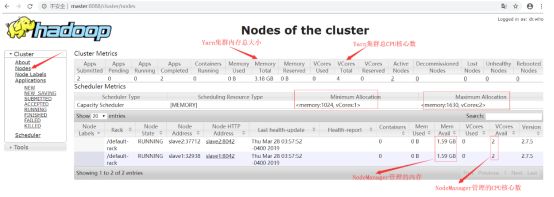
上图中的Minimum Allocation表示分配的container的最小资源,Maximum Allocation表示分配的container的最大资源。
也就说,每一次向ResourceManager申请资源的时候,最小会分配内存为1024MB、1个核心数的container资源,最大会分配内存为1630MB、2个核心数的container资源
container最小资源大小由如下配置决定:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
<description>向ResourceManager申请的container的最小内存大小,默认是1024MB</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>向ResourceManager申请的container的最小CPU核心数大小,默认是1个</description>
</property>
CDH中:


container最大资源大小由如下配置决定:
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
<description>向ResourceManager申请的container的最大内存大小,默认是8192MB</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>32</value>
<description>向ResourceManager申请的container的最大CPU核心数大小,默认是32个</description>
</property>
CDH的就不一一截图了,直接去搜这些配置信息,就能看到
注意:container最大的内存大小不能超过单个NodeManager管理的全部内存大小,最大的CPU核心数不能超过单个NodeManager管理的全部CPU核心数。所以我们的Yarn集群最大会分配内存为1630MB、2个核心数的container资源
所以说,container资源大小的分配规则一就是:Yarn集群会用配置规定最小最大container资源配置,如果向ResourceManager申请的资源如果大于container最大资源的话会报错的,所以我们有时候配置资源一旦超过32设置的值,就会报错,直接导致程序都无法调度
规则二:如果申请的资源大于最小资源的话,那么就按照最小资源的
整数倍分配
我们现在以MRAppMaster需要的资源为例,默认的资源大小是:1536MB,我们也可以再MR代码中去修改:
// 设置MRAppMaster需要的总内存大小为1000MB
job.getConfiguration().set("yarn.app.mapreduce.am.resource.mb", "1000");
// 设置MRAppMaster需要的堆内存大小为400MB
job.getConfiguration().set("yarn.app.mapreduce.am.command-opts", "-Xmx400m");
// 设置MRAppMaster需要的CPU核心数为1
job.getConfiguration().set("yarn.app.mapreduce.am.resource.cpu-vcores", "1");
然后,我们再在master机器上修改$HADOOP_HOME/et/hadoop/yarn-site.xml中的如下配置,修改container的最小内存大小为700MB:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>700</value>
<description>向ResourceManager申请的container的最小内存大小,默认是1024MB</description>
</property>
然后将修改后的$HADOOP_HOME/et/hadoop/yarn-site.xml同步到slave1和slave2上。然后重启Yarn集群
然后我们执行下面的命令,来提交一个MapReduce程序:
hadoop fs -rm -r /user/hadoop-jrq/mr/count/output
yarn jar mapreduce-study-1.0-SNAPSHOT.jar com.jrq.DistributedCount /user/hadoop-jrq/mr/count/input /user/hadoop-jrq/mr/count/output
程序启动后,MRAppMaster在slave2上运行,Map Task和Reduce Task在slave1上运行,如下图:
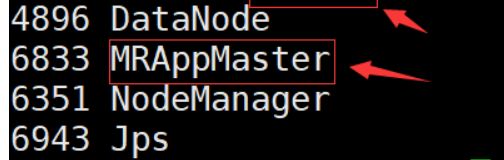

我们接下来看以下Yarn的WEB UI,可以看出slave1和slave2上分别启动了一个container:

从上图中,我们也可以看出container的最小分配内存大小是700MB了
slave2上启动的container是用来运行MRAppMaster的,slave1上启动的container是用来运行Map Task和Reduce Task的。那么为什么这两个container的内存大小都是1.37GB呢?
1.我们上面已经设置MRAppMaster进程需要的内存大小是1000MB,这个内存大于container的最小分配内存700MB,那么这个时候ResourceManager就分配最小内存整数倍且要大于1000MB,也就是700MB * 2 = 1400MB > 1000MB的内存的container用来运行MRAppMaster,而1400MB也是约等于1.37GB了
2.我们知道运行Map Task和Reduce Task的YarnChild进程默认需要的内存大小是1024MB,当向ResourceManager申请1024MB的内存的时候,因为大于最小分配内存700MB,那么这个时候ResourceManager就分配最小内存整数倍且要大于1000MB,也就是700MB * 2 = 1400MB > 1024MB的内存的container用来运行YarnChild,而1400MB也是约等于1.37GB了
所以说,container资源大小的分配规则二就是:如果申请的资源大于最小资源的话,那么就按照最小资源的整数倍分配
规则三:如果申请的资源超过NodeManager管理的总资源的话,则按照NodeManager的总资源分配
接下来设置MRAppMaster需要的内存大小为默认值的1536MB。但是我们通过如下的配置来修改Map Task和Reduce Task需要的内存大小为512MB:
// 修改Map Task需要的内存大小为512MB
job.getConfiguration().set("mapreduce.map.memory.mb", "512");
job.getConfiguration().set("mapreduce.map.java.opts", "-Xmx300m");
job.getConfiguration().set("mapreduce.map.cpu.vcores", "1");
// 修改Reduce Task需要的内存大小为512MB
job.getConfiguration().set("mapreduce.reduce.memory.mb", "512");
job.getConfiguration().set("mapreduce.reduce.java.opts", "-Xmx300m");
job.getConfiguration().set("mapreduce.reduce.cpu.vcores", "1");
然后,我们再在master机器上修改$HADOOP_HOME/et/hadoop/yarn-site.xml中的如下配置,修改container的最小内存大小为1024MB:
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
<description>向ResourceManager申请的container的最小内存大小,默认是1024MB</description>
</property>
然后将修改后的$HADOOP_HOME/et/hadoop/yarn-site.xml同步到slave1和slave2上。然后重启Yarn集群
然后我们执行下面的命令,来提交一个MapReduce程序:
hadoop fs -rm -r /user/hadoop-jrq/mr/count/output
yarn jar mapreduce-study-1.0-SNAPSHOT.jar com.jrq.DistributedCount /user/hadoop-jrq/mr/count/input /user/hadoop-jrq/mr/count/output
这次程序启动后,MRAppMaster在slave1上运行,Map Task和Reduce Task在slave2上运行,如下图:


我们接下来看以下Yarn的WEB UI,可以看出slave1和slave2上分别启动了一个container:

slave1上启动的container是用来运行MRAppMaster的,slave2上启动的container是用来运行Map Task和Reduce Task的。这里为什么slave1上的container的内存大小为1.59GB,而slave2上的container内存大小为1GB呢?
1.我们上面已经设置MRAppMaster进程需要的内存大小是1536MB,这个内存大于container的最小分配内存1024MB,那么这个时候ResourceManager就分配最小内存整数倍且要大于1536MB,也就是1024MB * 2 = 2048MB > 1536MB的内存的container用来运行MRAppMaster,但是2048MB大于NodeManager管理的内存大小1630MB,所以只能分配1630MB大小的内存了,也就是1.59GB
2.我们上面将Map Task和Reduce Task需要的内存都调成512M了,这个内存大小是小于最小分配内存1024MB的,所以这个时候ResourceManager分配的时候会以最小的分配内存进行分配,也就是1024MB,即1GB
从上面我们可以总结container分配的两个规律:
如果申请的资源超过NodeManager管理的总资源的话,则按照NodeManager的总资源分配
如果申请的资源小于最小分配资源的话,则按照最小资源进行分配
Spark核心组件
Spark core
RDD
RDD(Resilient Distributed Dataset)叫做弹性的分布数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:表示弹性的,那么为什么叫弹性的呢?这个是因为:
1、RDD中的数据既可以存储在内存也可以存储在磁盘中
2、RDD的分区是可以改变的(比如coalesce,repartition)
五大特性:
含有一个分区列表,每一个RDD都是由若干个分区数组组成,用于并行计算
定义了一个计算这个RDD每一个分区数据的函数
含有一个依赖列表,说白了就是当前这个RDD依赖哪些父亲RDD(在计算的时候可以通过这个依赖来容错)
包含一个或者零个Partitioner(分区器),其实就是这个RDD分区的方式
包含每一个分区数据存储的机器地址,用于实现计算任务的本地性
创建和保存
创建和保存的方式有很多,这里就不再一一描述了
RDD特点:
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系(比如:缓存,checkpoint)。
分区:
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。

只读:
如下图,RDD只读的,要想改变RDD中数据,只能在现有的基础上创建新的RDD

RDD算子:
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了。
RDD的操作算子包括两类,一类叫做transformations(map、filter、mapPartition、reduceByKey、groupByKey),它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions(foreach、collect、foreachPartition、count),它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。算子参考:https://blog.csdn.net/weixin_42411818/article/details/100102016,https://blog.csdn.net/weixin_42411818/article/details/104478497
依赖(血缘):
RDD中包含了一个依赖列表,所以说RDD会依赖一个或者多个父亲RDD,当然,RDD也可以不依赖任何的父亲RDD,比如我们从HDFS文件中创建的RDD就没有依赖的RDD。这个依赖更多的是用于计算容错的,当一个RDD计算失败的时候,Spark可以找到这个RDD的依赖的父亲RDD重新计算。
RDD的依赖分为窄依赖和宽依赖两种。
窄依赖: 父亲RDD的一个分区数据只能被子RDD的一个分区消费(OneToOneDependency和RangeDependency)
RDD中的map,filter等方法都会产生OneToOneDependency。而union方法会产生RangeDependency

宽依赖: 父亲RDD的一个分区的数据同时被子RDD多个分区消费(ShuffleDependency)
RDD中的reduceByKey,groupByKey等都会产生ShuffleDependency

Spark在针对不同的依赖处理的方式是不一样的。
对于窄依赖的处理有两个特点:第一、父子RDD的每一个分区的计算都是在同一台机器上完成,没有数据的网络传输,所以计算效率高;第二、子RDD的某个分区的计算不用等父亲RDD所有的分区计算完才开始,只要父亲RDD对应的分区计算完了,那么子RDD对应的分区的计算就可以开始
对于宽依赖的处理有两个特点:第一、因为宽依赖中子RDD的一个分区可能消费父亲RDD的所有分区计算后的结果数据,所以子RDD的计算必须要等父亲RDD的所有分区都计算完了才可以开始;第二、因为宽依赖中子RDD所依赖的父亲RDD的分区数据可能不是在同一台机器上,所以Spark需要将父亲RDD的计算后的分区结果数据通过网络传输传输至子RDD分区计算所在的机器上,所以宽依赖的计算效率比较低
缓存:
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。

CheckPoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
Partitioner:
HashPartitioner和RangePartitioner
HashPartitioner的规则是:key的hash值与指定的分区数进行取模得到这个key应该进入的分区
RangePartitioner的规则是:将可以排序的key分到几个大概相等的范围分区中的一个分区中
比如一个有10个分区的RDD[(Int, String)]需要按照RangePartitioner重分区为3个分区:
>=0且<=10 的key的数据放到分区一中
>10且<=30的key的数据放到分区二中
>30的key的数据放到分区三中
自定义:
// 自定义分区器
class MyPartitioner(partitions: Int) extends Partitioner {
override def numPartitions: Int = {
partitions
}
// 返回是多少,数据就放在哪个分区里去 所以这里需要根据我们的业务去写,可以去参考源码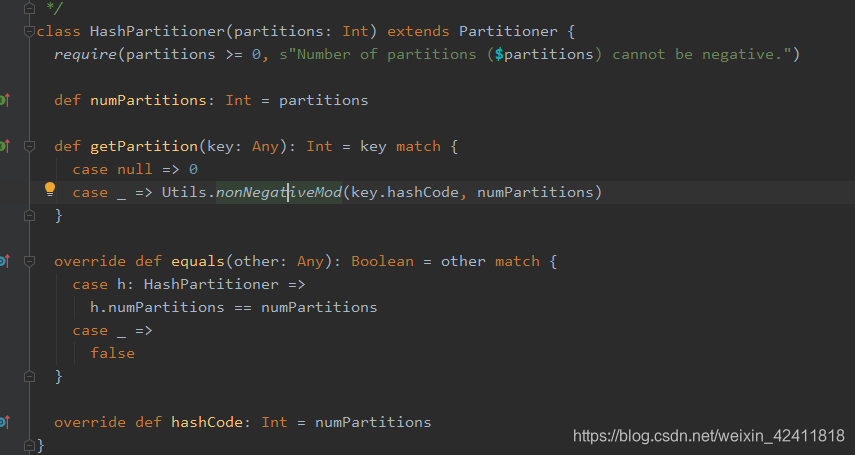
override def getPartition(key: Any): Int = {
1
}
}


一个job提交的流程
在使用spark-submit提交一个Spark应用之后,Driver程序会向集群申请一定的资源来启动东若干个Executors用来计算,当这些Executors启动后,它们会向Driver端的SchedulerBackend进行注册,告诉Driver端整个每一个Executor的资源情况。 那么在一个Spark Application中的一旦一个RDD触发了Action API后,就会触发一个job的提交,job的提交步骤如下:
1、DAGScheduler根据RDD的依赖来划分并创建Stage,划分Stage的原则是碰到宽依赖就进行Stage的划分,划分好的所有Stage之间也有父子关系。调度Stage的时候先调度没有父亲的Stage
2、将没有父亲的Stage转成Taskset提交给TaskScheduler进行调度,每一个Stage对应着一个Taskset,一个Taskset包含了若干个Task,如果RDD有几个分区,那么这个Taskset中就有几个Task
3、TaskScheduler接收到Taskset之后,先创建一个TasksetManager,用于调度和管理这个Taskset中所有Task,然后将这个TasksetManager放到TasksetManager Pool中(这个Pool的功能就是使得我们可以使用不同的策略来调度TasksetManager)。
4、这个时候TaskScheduler就向SchedulerBackend申请足够的资源来调度执行某一个TasksetManager中的Task了,如果SchedulerBackend资源充足的话,则将可以用的资源情况告诉TaskScheduler,TaskScheduler将资源情况告诉TasksetManager,然后TasksetManager根据资源情况来调度需要执行的Task(这里包含了延迟调度、Task黑名单机制等)
5、从TasksetManager中调度的Task直接发往相对应的Executor进行执行,这个时候SchedulerBackend的记录的集群的资源情况信息会被更新,因为有Task占用资源了
6、当Executor上执行的Task结束了后,会将Task的状态发往给SchedulerBackend,SchedulerBackend将Task的状态告诉TaskScheduler,TaskScheduler委托TaskResultGetter来解析返回的Task的状态,得到Task执行完之后的结果,然后将Task执行完的结果数据告诉TasksetManager,TasksetManager根据Task的执行结果来更新该Task的状态信息(比如Task是失败、成功还是重跑等),更新完TasksetManager中对应的Task的结果后,再去更新DAGScheduler中Task所在的Stage的状态,比如,如果Task是成功的,该Task所在的Stage的所有Task都跑完了,那么DAGScheduler就可以调度该Stage的子Stage了
_第31张图片](http://img.e-com-net.com/image/info8/25e9bf989741496097658be9c7e56ad7.jpg)
RDD是怎样利用依赖做到高效的计算容错的
其实计算容错就是指当某个Task执行失败了的话,可以重新计算这个Task,Spark默认是可以重新调度执行失败的Task四次,如果四次仍然失败的话,那么这个Task就真的失败了,也会导致整个Spark应用失败。那么Spark的计算容错是怎么实现的呢?
首先RDD能利用依赖做到计算容错是因为RDD的transformation都是懒计算,只有这些transformation是懒计算,才可以使得在真正提交Job前让RDD记住相对应的依赖关系,使得RDD保持Lineage血统
然后每一个Spark Job的提交运行,都会根据这个Job中的RDD的依赖来划分并且创建Stage,划分出来的Stage之间也是有父子关系的,每一个Stage有一个或者没有父亲Stage,每一个Stage中包含着若干个Task
那么Spark中的计算容错应该有两个层次的考虑:
第一、就是task层次上的重新计算,比如一个Stage对应的TasksetManager中的某个Task失败了,这个时候只需要TasksetManager将这个Task重新再提交到集群中运行就可以了
第二、就是Stage层次上的重新计算,如果某个Stage都失败了,那么需要重新调度运行这个Stage的父亲Stage(Stage的父子关系在Stage的划分的时候就已经确定了)
更多
参考:https://blog.csdn.net/weixin_42411818/article/details/98473879
spark sql
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源类型,例如Hive表、Parquet以及JSON等。Spark SQL不仅为Spark提供了一个SQL接口,还支持开发者将SQL语句融入到Spark应用程序开发过程中,无论是使用Python、Java还是Scala,用户可以在单个的应用中同时进行SQL查询和复杂的数据分析。由于能够与Spark所提供的丰富的计算环境紧密结合,Spark SQL得以从其他开源数据仓库工具中脱颖而出。Spark SQL在Spark l.0中被首次引入。在Spark SQL之前,美国加州大学伯克利分校曾经尝试修改Apache Hive以使其运行在Spark上,进而提出了组件Shark。然而随着Spark SQL的提出与发展,其与Spark引擎和API结合得更加紧密,使得Shark已经被Spark SQL所取代。
sparksql 的介绍详见:https://spark.apache.org/sql/
Datasets和DataFrames
DataFrames
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。

如何创建DF
1.通过 case class 创建 DataFrames(反射)
//定义case class,相当于表结构
case class People(var name:String,var age:Int)
object TestDataFrame1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDDToDataFrame").setMaster("local")
val sc = new SparkContext(conf)
val context = new SQLContext(sc) // 等同与新版的sparksession
// 将本地的数据读入 RDD, 并将 RDD 与 case class 关联
val peopleRDD = sc.textFile("E:\\666\\people.txt")
.map(line => People(line.split(",")(0), line.split(",")(1).trim.toInt))
import context.implicits._
// 将RDD 转换成 DataFrames
val df = peopleRDD.toDF
//将DataFrames创建成一个临时的视图
df.createOrReplaceTempView("people")
//使用SQL语句进行查询
context.sql("select * from people").show()
}
}
2.通过 structType 创建 DataFrames(编程接口)
object TestDataFrame2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val fileRDD = sc.textFile("E:\\666\\people.txt")
// 将 RDD 数据映射成 Row,需要 import org.apache.spark.sql.Row
val rowRDD: RDD[Row] = fileRDD.map(line => {
val fields = line.split(",")
Row(fields(0), fields(1).trim.toInt)
})
// 创建 StructType 来定义结构
val structType: StructType = StructType(
//字段名,字段类型,是否可以为空
StructField("name", StringType, true) ::
StructField("age", IntegerType, true) :: Nil
)
/**
* rows: java.util.List[Row],
* schema: StructType
* */
val df: DataFrame = sqlContext.createDataFrame(rowRDD,structType)
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
}
}
3.外部数据源创建 DataFrames
object TestDataFrame3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.json("E:\\666\\people.json")
df.createOrReplaceTempView("people")
sqlContext.sql("select * from people").show()
}
}
DataFrame的read和save和savemode
数据的读取
object TestRead {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//方式一
val df1 = sqlContext.read.json("E:\\666\\people.json")
val df2 = sqlContext.read.parquet("E:\\666\\users.parquet")
//方式二
val df3 = sqlContext.read.format("json").load("E:\\666\\people.json")
val df4 = sqlContext.read.format("parquet").load("E:\\666\\users.parquet")
//方式三,默认是parquet格式
val df5 = sqlContext.load("E:\\666\\users.parquet")
// hive 需要依赖spark-hive包
// 创建时加上enableHiveSupport()就可以直接连hive了
}
}
数据的保存
object TestSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestDataFrame2").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df1 = sqlContext.read.json("E:\\666\\people.json")
//方式一
df1.write.json("E:\\111")
df1.write.parquet("E:\\222")
//方式二
df1.write.format("json").save("E:\\333")
df1.write.format("parquet").save("E:\\444")
//方式三
df1.write.save("E:\\555")
}
}
数据的保存模式
df1.write.format("parquet").mode(SaveMode.Ignore).save("E:\\444")

关于读写MySQL
object JdbcDatasourceTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("JdbcDatasourceTest")
.master("local")
.getOrCreate()
//url:
// jdbc:mysql://master:3306/test
// jdbc:oracle://master:3306/test
// jdbc:db2://master:3306/test
// jdbc:derby://master:3306/test
// jdbc:sqlserver://master:3306/test
// jdbc:postgresql://master:3306/test
// val mysqlUrl = "jdbc:mysql://master:3306/test"
val mysqlUrl = "jdbc:mysql://localhoast:3306/test"
val basepath = "F:\\spark-dataset\\src\\main\\resources"
//1: 读取csv文件数据 header 保留头信息 inferSchema自动推断类型
val optsMap = Map("header" -> "true", "inferSchema" -> "true")
val df = spark.read.options(optsMap).csv(s"${BASE_PATH}/jdbc_demo_data.csv")
df.show()
val properties = new Properties()
properties.put("user", "root")
properties.put("password", "root")
//向Mysql数据库写数据
df.write.mode(SaveMode.Overwrite).jdbc(mysqlUrl, "person", properties)
//从mysql数据库读取数据
// 注意,这种方式读小表还可以,但是读大数据的时候,问题就大了
// 因为sparkSQL jdbc只是一个分区去读,会很慢,解决方法在下面
val jdbcDFWithNoneOption = spark.read.jdbc(mysqlUrl, "person", properties)
jdbcDFWithNoneOption.show()
// jdbcDFWithNoneOption.join(jdbcDFWithNoneOption)
//写数据的过程:
//1 : 建表
//第一次写的时候,需要创建一张表,建表语句类似如下:
//CREATE TABLE t (name string) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1
//ENGINE=InnoDB使用innodb引擎 DEFAULT CHARSET=utf8 数据库默认编码为utf-8 AUTO_INCREMENT=1 自增键的起始序号为1
//.InnoDB,是MySQL的数据库引擎之一,为MySQL AB发布binary的标准之一
//属性配置ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1可以通过参数createTableOptions传给spark
var writeOpts =
Map[String, String]("createTableOptions" -> "ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1")
df.write.mode(SaveMode.Overwrite).options(writeOpts).jdbc(mysqlUrl, "person", properties)
//2: 设置表的schema
// 一般表的schema是和DataFrame是一致的,字段的类型是从spark sql的DataType翻译到各个数据库对应的数据类型
// 如果字段在数据库中的类型不是你想要的,
// 你可以通过参数createTableColumnTypes来设置createTableColumnTypes=age long,name string
writeOpts = Map[String, String]("createTableColumnTypes" -> "id long,age long")
df.write.mode(SaveMode.Overwrite).options(writeOpts).jdbc(mysqlUrl, "person", properties)
//3: 事务隔离级别的设置,通过参数isolationLevel设置
// NONE 不支持事物
// READ_UNCOMMITTED 会出现脏读、不可重复读以及幻读
// READ_COMMITTED 不会出现脏读,但是还是会出现不可重复读以及幻读
// REPEATABLE_READ 不会出现脏读以及不可重复读,但是还会出现幻读
// SERIALIZABLE 脏读、不可重复读以及幻读都不会出现了
writeOpts = Map[String, String]("isolationLevel" -> "READ_UNCOMMITTED")
df.write.mode(SaveMode.Overwrite).options(writeOpts).jdbc(mysqlUrl, "person", properties)
//4:写数据
//写数据的过程中可以采用批量写数据,每一批写的数据量的大小可以通过参数batchsize设置,默认是:1000
writeOpts = Map[String, String]("batchsize" -> "100")
df.write.mode(SaveMode.Overwrite).options(writeOpts).jdbc(mysqlUrl, "person", properties)
//5:第二次写数据的时候,这个时候表已经存在了,所以需要区分SaveMode
//当SaveMode=Overwrite 的时候,需要先清理表,然后再写数据。清理表的方法又分两种:
// 第一种是truncate即清空表,如果是这种的话,则先清空表,然后再写数据
// 第二种是drop掉表,如果是这种的话,则先drop表,然后建表,最后写数据
//以上两种方式的选择,可以通过参数truncate(默认是false)控制。因为truncate清空数据可能会失败,所以可以使用drop table的方式
//而且不是所有的数据库都支持truncate table,其中PostgresDialect就不支持
//当SaveMode=Append 的时候,则直接写数据就行
//当SaveMode=ErrorIfExists 的时候,则直接抛异常
//当SaveMode=Ignore 的时候,则直接不做任何事情
writeOpts = Map[String, String]("truncate" -> "false")
df.write.mode(SaveMode.Overwrite).options(writeOpts).jdbc(mysqlUrl, "person", properties)
//按照某个分区字段进行分区读数据 分区读数据,就会快很多
//partitionColumn 分区的字段,这个字段必须是integral类型的
//lowerBound 用于决定分区步数的partitionColumn的最小值
//upperBound 用于决定分区步数的partitionColumn的最大值
//numPartitions 分区数,和lowerBound以及upperBound一起来为每一个分区生成sql的where字句
//如果upperBound - lowerBound >= numPartitions,那么我们就取numPartitions个分区,
// 否则我们取upperBound - lowerBound个分区数
// 8 - 3 = 5 > 3 所以我们取3个分区
// where id < 3 + 1 这个1是通过 8/3 - 3/3 = 1得来的 3是lowerBound
// where id >= 3 + 1 and id < 3 + 1 + 1 1都是步长
// where id >= 3 + 1 + 1 剩下的那个分区
// fetchsize 批量查的数据量 一次性读多少数据
//配置的方式
val readOpts = Map[String, String]("numPartitions" -> "3", "partitionColumn" -> "id",
"lowerBound" -> "3", "upperBound" -> "8", "fetchsize" -> "100")
val jdbcDF = spark.read.options(readOpts).jdbc(mysqlUrl, "person", properties)
jdbcDF.rdd.partitions.size // 看多少分区
jdbcDF.rdd.glom().collect() // 每个分区的数据
jdbcDF.show()
//api的方式
spark.read.jdbc(mysqlUrl, "person", "id", 3, 8, 3, properties).show()
//参数predicates: Array[String],用于决定每一个分区对应的where子句,分区数就是数组predicates的大小
// 这里就是分成两个分区去读数据
val conditionDF = spark.read.jdbc(mysqlUrl,
"person", Array("id > 2 and id < 5", "id >= 5 and id < 8"), properties)
conditionDF.rdd.partitions.size
conditionDF.rdd.glom().collect()
conditionDF.show()
//每次读取的时候,可以采用batch的方式读取数据,batch的数量可以由参数fetchsize来设置。默认为:0,表示jdbc的driver来估计这个batch的大小
//不管是读还是写,都有分区数的概念,
// 读的时候是通过用户设置numPartitions参数设置的,
// 而写的分区数是DataFrame的分区数
//需要注意一点的是不管是读还是写,每一个分区都会打开一个jdbc的连接,所以分区不宜太多,要不然的话会搞垮数据库
//写的时候,可以通过DataFrame的coalease接口来减少分区数
spark.stop()
}
}
内置函数
参考:https://blog.csdn.net/weixin_42411818/article/details/98942225
RDD、DataFrame以及Dataset之间的区别
RDD是:不变的、分布式的数据集、在集群中是分区的、懒计算的以及是类型安全的
RDD是Spark的基础,Dataset和DataFrame最终还是会调用RDD的API来实现
DataFrame就是Row类型的Dataset,和RDD一样是不变的、分布式的数据集、在集群中是分区的、懒计算的,但不是类型安全的,没有提供类似于RDD中的函数式编程的接口,但是DataFrame的性能比RDD强很多
Dataset就是强类型、支持函数式变成的DataFrame,说白了Dataset就是RDD + DataFrame
PS:python目前不支持Dataset
DataFrame和Dataset比RDD性能好的原因
这个是因为Spark团队利用DataFrame或者Dataset中的Schema信息对DataFrame或者Dataset中的API做了很大的性能优化,如下:
1、在缓存DataFrame或者Dataset的时候,可以对基本类型的列按列进行存储
2、钨丝计划:第一、引入了一个显示的内存管理器让Spark操作可以直接针对二进制数据而不是Java对象,这样就可以减少Java对象的开销和无效率的GC;第二、设计了更加缓存友好的算法和数据结构,从而让Spark应用程序可以花费更少的时间等待CPU从内存中读取数据,也给有用的工作提供了更多的计算时间;第三、Code generation去掉了原始数据类型的封装和解封,更重要的是避免了昂贵的多态函数调度
3、Catalyst Optimizer,因为Spark的RDD是懒加载的,所在在触发Job之前可以对RDD的链做很多的优化,而Catalyst Optimizer就是给这个RDD链方便的加上优化的手段
Spark SQL的执行流程是什么样的
不管是SQL、Hive SQL还是DataFrame、Dataset触发Action Job的时候,都会经过解析变成unresolved的逻辑执行计划,然后利用元数据信息对unresolved的逻辑执行计算进行分析,得到逻辑执行计划,然后对逻辑执行计划进行优化,得到优化后的逻辑执行计划,然后利用优化后的逻辑执行计划生成多个物理执行计划,利用cost model分别对所有的物理执行计划进行测试看看哪个性能更好,然后选出性能最好的物理执行计划,根据选择好的物理执行计划进行代码生成,最终生成RDD链,开始执行并返回结果

sql Json处理常用的几个函数
get_json_object、from_json、to_json、explode以及getItem
object JsonSQLFunctionTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("JsonSQLFunctionTest")
.master("local").getOrCreate()
import spark.implicits._
// 组成一个row类型的rdd
val eventsRDD =
spark.sparkContext.textFile(s"${BASE_PATH}/example/device_info.txt").map(line => {
val data = line.split("::")
Row(data(0).toLong, data(1))
})
// 定义schema信息
val schema = StructType(StructField("id", LongType)
:: StructField("device", StringType) :: Nil) //StringType 需要导入types
// 创建df
val eventsDF = spark.createDataFrame(eventsRDD, schema)
eventsDF.printSchema()
eventsDF.show(false)
import org.apache.spark.sql.functions._
//get_json_object 获取device下的device_type
// get_json_object 拿到一个字符串类型的json里的值
eventsDF.select($"id", get_json_object($"device", "$.device_type").alias("device_type"),
get_json_object($"device", "$.ip").alias("ip"),
get_json_object($"device", "$.cca3").alias("cca3")).show()
//from_json 拿到json里的数据组成df
val fieldSeq = Seq(StructField("battery_level", LongType), StructField("c02_level", LongType),
StructField("cca3",StringType), StructField("cn", StringType),
StructField("device_id", LongType), StructField("device_type", StringType),
StructField("signal", LongType), StructField("ip", StringType),
StructField("temp", LongType), StructField("timestamp", TimestampType))
val jsonSchema = StructType(fieldSeq)
val devicesDF = eventsDF.select(from_json($"device", jsonSchema) as "devices")
devicesDF.printSchema()
devicesDF.show(false)
// .* 可以吧上面定义的所有字段都给展开
val devicesAll = devicesDF.select($"devices.*").filter($"devices.temp" > 10
and $"devices.signal" > 15)
devicesAll.show()
val devicesUSDF =
devicesAll.select($"*").where($"cca3" === "USA").orderBy($"signal".desc, $"temp".desc)
devicesUSDF.show()
//to_json 转成一个str类型的json字符串
val stringJsonDF = eventsDF.select(to_json(struct($"*"))).toDF("devices")
stringJsonDF.printSchema()
stringJsonDF.show(false)
stringJsonDF.write.mode(SaveMode.Overwrite).parquet(s"${BASE_PATH}/to_json")
val parquetDF = spark.read.parquet(s"${BASE_PATH}/to_json")
parquetDF.show(false)
//selectExpr 字段可以放表达式
val stringsDF = eventsDF.selectExpr("CAST(id AS INT)", "CAST(device AS STRING)")
stringsDF.show()
val selectExprDF =
devicesAll.selectExpr("c02_level",
"round(c02_level/temp, 2) as ratio_c02_temperature").orderBy($"ratio_c02_temperature" desc)
selectExprDF.show()
spark.stop()
}
}
case class DeviceData (id: Long, device: String)
object JsonComplexTypeTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("JsonComplexTypeTest")
.master("local")
.getOrCreate()
val dataRDD = spark.sparkContext.textFile(s"${BASE_PATH}/example/complex_type.json")
// 复杂的类型schema定义
val schema = new StructType().add("dc_id", StringType).add("source",
MapType(
StringType,
new StructType().add("description", StringType).add("ip", StringType).add("id", LongType).add("temp", LongType).add("c02_level", LongType).add("geo",
new StructType().add("lat", DoubleType).add("long", DoubleType)
)
)
)
import spark.implicits._
// 创建ds
val ds = spark.createDataset(dataRDD)
// 把schema用上
val df = spark.read.schema(schema).json(ds)
df.printSchema()
df.show(false)
import org.apache.spark.sql.functions._
import spark.implicits._
// explode 这个函数可以把复杂结构体展平
val explodedDF = df.select($"dc_id", explode($"source"))
explodedDF.printSchema()
//root
// |-- dc_id: string (nullable = true)
// |-- key: string (nullable = false)
// |-- value: struct (nullable = true)
// | |-- description: string (nullable = true)
// | |-- ip: string (nullable = true)
// | |-- id: long (nullable = true)
// | |-- temp: long (nullable = true)
// | |-- c02_level: long (nullable = true)
// | |-- geo: struct (nullable = true)
// | | |-- lat: double (nullable = true)
// | | |-- long: double (nullable = true)
explodedDF.show()
//getItem 用这个方式去获取到值
val devicesDF = explodedDF.select( $"dc_id" as "dcId",
$"key" as "deviceType",
'value.getItem("ip") as 'ip,
'value.getItem("id") as 'deviceId,
'value.getItem("c02_level") as 'c02_level,
'value.getItem("temp") as 'temp,
'value.getItem("geo").getItem("lat") as 'lat,
'value.getItem("geo").getItem("long") as 'lon)
devicesDF.printSchema()
devicesDF.show()
spark.stop()
}
}
SparkStreaming
概要
Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,Twitter,ZeroMQ,Kinesis,hdfs或者TCP接口等,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和HDFS。

在内部,其按如下方式运行。Spark Streaming接收到实时数据流同时将其划分为分批,这些数据的分批将会被Spark的引擎所处理从而生成同样按批次形式的最终流。

Spark Streaming提供了被称为离散化流或者DStream的高层抽象,这个高层抽象用于表示数据的连续流。
创建DStream的两种方式:
1.由Kafka,Flume等取得的数据作为输入数据流。
2.在其他DStream进行的高层操作。
在内部,DStream被表达为RDDs的一个序列。
原理
Spark Streaming应用也是Spark应用,Spark Streaming生成的DStream最终也是会转化成RDD,然后进行RDD的计算,所以Spark Streaming最终的计算是RDD的计算,那么Spark Streaming的原理当然也包含了Spark应用通用的原理。Spark Streaming作为实时计算的技术,和其他的实时计算技术(比如Storm)不太一样,我们可以将Spark Streaming理解为micro-batch模式的实时计算,也就是说Spark Streaming本质是批处理,就是这个批处理之间的时间间隔是非常的小,这个时间间隔最小是500ms,基本上可以适合企业中80%的实时计算场景。
在实时计算的步骤中,Spark Streaming当然也包含了实时接收数据过程、数据的transformation过程以及数据结果输出过程三个最基本的过程。Spark Streaming在数据接收的部分包括基于Receiver模式以及Direct模式(Kafka Direct),接下来详细的讲解下基于Receiver模式的Spark Streaming应用的原理。
当我们使用spark-submit提交一个Spark Streaming应用的时候,向集群申请到资源并且初始化需要的Executor后,Spark Streaming应用的执行过程包括两部分:一个是StreamingContext的初始化,一个是Spark Streaming应用对Receiver实时接收到的数据的实时计算。以下分别介绍
StreamingContext的初始化:
Spark Streaming应用对Receiver实时接收到的数据的实时计算
Receiver将实时接收到的数据存储在Executor的内存中,由BlockManager管理,存储完数据后会告诉ReceiverTracker数据块存储的位置,方便ReceiverTracker跟踪定位;当我们设定的batch interval时间到了的时候,JobGenerator就会告诉ReceiverTracker定位所有这个batch interval收集到的数据,并且生成一个定时任务,这个定时任务就会根据ReceiverTracker定位到的所有的数据块生成一个BlockRDD(这个是RDD链中的第一个需要执行的),并且根据InputDStream和OutputDStream两个DStream之间的一系列的业务Transformations生成RDD链,最后生成RDD DAG,进行RDD的计算任务的提交,这个时候就来到了Spark RDD的任务提交的原理的,可以参考Spark Core中的内容
注意:上面的原理是讲解基于Receiver模式的,还有比如Kafka Direct模式在数据接收的地方和这个稍有不同(Receiver是数据源推送,Direct是主动拉取),其他的数据处理流程是一样
离散数据流(DStreams)
离散数据流或者DStream是SS提供的基本抽象。其表现数据的连续流,这个输入数据流可以来自于源,也可以来自于转换输入流产生的已处理数据流。内部而言,一个DStream以一系列连续的RDDs所展现,这些RDD是Spark对于不变的,分布式数据集的抽象。一个DStream中的每个RDD都包含来自一定间隔的数据,如下图:

在DStream上使用的任何操作都会转换为针对底层RDD的操作。例如:之前那个将行的流转变为词流的例子中,flatMap操作应用于行DStream的每个RDD上 从而产生words DStream的RDD。如下图:

这些底层的RDD转换是通过Spark引擎计算的。DStream操作隐藏了大多数细节,同时为了方便为开发者提供了一个高层的API。这里的一些操作会在下文中详述。
简单的案例
tcp:
object NetworkWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// StreamingContext 编程入口 Seconds 1秒计算一次
val ssc = new StreamingContext(sc, Seconds(1))
//数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),
// 这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
// MEMORY_AND_DISK_SER_2 _2代表的意思是数据做备份,存储两份 SER代表序列化的意思
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER_2)
//数据处理(Process)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordPairs = words.map(x => (x, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
//结果输出(Output)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
hdfs文件的监控:
//1、监控目录下的文件的格式必须是统一的
//2、不支持嵌入文件目录
//3、一旦文件移动到这个监控目录下,是不能变的,往文件中追加的数据是不会被读取的
val sparkConf = new SparkConf().setAppName("HdfsFileStream")
val sc = new SparkContext(sparkConf)
// Create the context
val ssc = new StreamingContext(sc, Seconds(2))
// 实时监控一个文件是否有新的文件进来
val filePath = "hdfs://master:9999/user/hadoop-jrq/spark/streaming/filestream"
// Create the FileInputDStream on the directory and use the
// stream to count words in new files created
// filePath 表示监控的文件目录
// filter(Path => Boolean) 表示符合条件的文件路径
// isNewFile 表示streaming app启动的时候是否需要处理已经存在的文件
// key类型:LongWritable value类型:Text 输出的文件类型:TextInputFormat 文本类型
// (path: Path) => path.toString.contains("process") 这是一个文件过滤器,符合条件才进来
// false 参数的意思是,默认5分钟,true超过了就不会处理五分钟以前的文件了,而false还会去处理
val lines = ssc.fileStream[LongWritable, Text, TextInputFormat](filePath,
(path: Path) => path.toString.contains("process"), false).map(_._2.toString)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
重要的API
两个状态API
mapWithState
// currentBatchTime : 表示当前的Batch的时间
// key: 表示需要更新状态的key
// value: 表示当前batch的对应的key的对应的值
// currentState: 对应key的当前的状态
val stateSpec = StateSpec.function((currentBatchTime: Time, key: String, value: Option[Int], currentState: State[Long]) => {
val sum = value.getOrElse(0).toLong + currentState.getOption.getOrElse(0L)
val output = (key, sum)
if (!currentState.isTimingOut()) {
currentState.update(sum)
}
Some(output)
}).initialState(initialRDD).numPartitions(2).timeout(Seconds(30)) //timeout: 当一个key超过这个时间没有接收到数据的时候,这个key以及对应的状态会被移除掉
val result = wordsDStream.mapWithState(stateSpec)
result.print()
// stateSnapshots 将它维护的所有key和值都展示出来,直到超时
result.stateSnapshots().print()
updateStateByKey
val wordsDStream = words.map(x => (x, 1))
// updateStateByKey 这个api必须要checkpoint因为它是一开始到现在为止的所有RDD都有,他对所有的RDD都会有依赖
// 累加key出现的次数
wordsDStream.updateStateByKey(
// 第一个values 这个key在这个时间段内收集到的值有多少,对应的就是一个Seq
// (1,1,1,1,1) ...
// currentState 当前的key对应的状态是什么样的 因为可能没有,所以是一个option
// 后面那个就是对当前的key记总数
// getOrElse 没有的话就置为0
// values.sum 对所有的值进行累加
(values: Seq[Int], currentState: Option[Int]) => Some(currentState.getOrElse(0) + values.sum)).print()
//updateStateByKey的另一个API 可以只关注符合条件的key
// 第一个是key 第二个是接收到的数据 第三个是这个key当前的状态
wordsDStream.updateStateByKey[Int]((iter: Iterator[(String, Seq[Int], Option[Int])]) => {
val list = ListBuffer[(String, Int)]()
while (iter.hasNext) { // 对key进行跌带
val (key, newCounts, currentState) = iter.next
val state = Some(currentState.getOrElse(0) + newCounts.sum) // 当前状态
val value = state.getOrElse(0)
if (key.contains("error")) { // 只有error才会统计
list += ((key, value)) // Add only keys with contains error
}
}
list.toIterator
}, new HashPartitioner(4), true).print() // true 表示使用
window
//每过1秒钟,然后显示前3秒的数据
val windowDStream = lines.window(Seconds(3), Seconds(1))
// 每5秒中,统计前20秒内每个单词出现的次数
val wordCounts =
wordPair.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(5))
updateStateByKey和mapWithState的区别
1、updateStateByKey,这个API根据一个key的之前的状态和新的接收到的数据来计算并且更新新状态。使用这个API需要做两步:第一就是为每一个key定义一个初始状态,这个状态的类型可以实任意类型;第二就是定义一个更新状态的函数,这个函数根据每一个key之前的状态和新接收到的数据计算新的状态。
2、mapWithState,这个API的功能和updateStateByKey是一样的,只不过在性能方面做了很大的优化,这个函数对于没有接收到新数据的key是不会计算新状态的,而updateStateByKey是会重新计算任何的key的新状态的,由于这个原因所以导致mapWithState可以处理的key的数量比updateStateByKey多10倍多,性能也比updateStateByKey快很多。mapWithState还支持timeout API
kafka 数据源
Receiver模式
// Receiver模式,尽量不用
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount " )
System.exit(1)
}
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master")
val sparkConf = new SparkConf()
sparkConf.setAppName("KafkaWordCount")
sparkConf.setMaster("local[5]")
val sc = new SparkContext(sparkConf)
// zk的ip group topics:可以消费多个主题 numThreads:对应的分区数是对少
val Array(zkQuorum, group, topics, numThreads) = args
val ssc = new StreamingContext(sc, Seconds(2))
ssc.checkpoint("hdfs://master:8020/user/spark-data/streaming/checkpoint")
// 有多少分区就开多少线程 值是对应的分区数
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// kafka的一些配置
val kafkaParams = Map[String, String](
"zookeeper.connect" -> zkQuorum, "group.id" -> group,
"zookeeper.connection.timeout.ms" -> "10000",
// largest 最新的数据
"auto.offset.reset" -> "largest") // smallest 这个意思就是从最小的topic消费数据
val numStreams = 3
// 创建多个接收器 因此这里最少需要5个core,3个接收,2个处理
val kafkaStreams = (1 to numStreams).map { _ =>
// String key的类型 String value的类型 StringDecoder 编码器 StringDecoder 解码
KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER_2)
}
val unifiedStream = ssc.union(kafkaStreams) // 如果需要增加消费数据源的并行度,那么就需要对个union
// val kafkaDStream = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
// ssc, kafkaParams, topicMap, StorageLevel.MEMORY_AND_DISK_SER_2)
val lines = unifiedStream.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
}
}
Direct模式
// Simplified Parallelism 不需要union多个InputDStreaming
// Efficiency 不需要写WAL就可以达到不会丢失数据
// Exactly-once(只有一次) semantics Spark Streaming自己跟踪消费的offset,消除了与zk的不一致
// 如果需要控制接收的速率,用spark.streaming.kafka.maxRatePerPartition来控制
// 能用这种模式就用这种模式
// 使用代理和主题创建直接的kafka流
val topicsSet = topics.split(",").toSet
// kafka地址列表
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
提高Spark Streaming的性能和Spark Streaming的稳定性
参考:https://blog.csdn.net/weixin_42411818/article/details/99333370
Spark Streaming容错
1、Executor失败容错:Executor的失败会重新启动一个新的Executor,这个是Spark自身的特性。如果Receiver所在的Executor失败了,那么Spark Streaming会在另外一个Executor上启动这个Receiver(这个Executor上可能存在已经接收到的数据的备份)
2、Driver失败的容错:如果Driver失败的话,那么整个Spark Streaming应用将会全部挂掉。所以Driver端的容错是非常重要的,我们首先可以配置Driver端的checkpoint,用于定期的保存Driver端的状态;然后我们可以配置Driver端失败的自动重启机制(每一种集群管理的配置都不一样);最后我们需要打开Executor端的WAL机制
3、一个Task失败的容错:Spark中的某个Task失败了可以重新运行,这个Task所在的Stage失败的话呢,也可以根据RDD的依赖重新跑这个Stage的父亲Stage,进而重新跑这个失败的Stage
4、在实时计算的过程,肯定不能容忍某个Task的运行时间过长,Spark Streaming对于某个运行时间过长的Task会将这个Task杀掉重新在另一个资源比较充足的Executor上执行。这个就是利用了Spark的Task调度的推测机制(见下图)。

Flume和Spark Streaming集成(认识)
Spark Streaming通过push模式和pull模式两种模式来集成Flume
push模式:Spark Streaming端会启动一个基于Avro Socket Server的Receiver来接收Flume中的avro sink发来的数据,这个时候Flume avro sink就是作为客户端
pull模式:这种模式是Spark自定义了一个Flume的sink作为Avro Server,flume收集到的数据发往这个sink,然后数据存储在这个sink的缓存中,然后Spark Streaming启动包含有Avro Client的Recevier从自定义的Flume的sink中拉取数据。相对于push模式,这种模式更加的可靠不会丢失数据,这个是因为以下两点原因:
1、pull模式的Receiver是一个可靠的Receiver,就是这个Receiver接收到了数据,并且将这个数据存储并且备份了后会发送一个ack响应给Flume的sink
2、结合Flume的事务特性,保证了数据不会丢失,一定会拉取到数据,如果没有拉取成功的话(就是Flume Sink没有接收到Receiver发送的ack),则事务失败
Kafka和Spark Streaming集成(认识)
Spark Streaming通过Receiver模式和Direct模式两种模式来集成Kafka
Receiver模式:Spark Streaming作为Consumer实时消费Kafka中的数据,如果启动多个Receiver的话就是启动多个Consumer,这些Consumer必须属于同一个Consumer Group
两种模式的对比:
1、基于Receiver模式有两种Receiver,一种是KafkaReceiver,这种Receiver会丢失数据,符合At most once语义;一种是ReliableKafkaReceiver,这种是开启了WAL的Receiver,不会丢失数据,符合At least once语义
2、Direct模式简化了并行度,不需要union多个InputDStreaming就可以做到并行消费数据,topic的partition的数量就是并行度的数量
3、Direct模式不需要写WAL就可以达到不会丢失数据,因为Direct模式是直接消费存储在Kafka中的数据,所以这种方式更加的高效
4、Direct模式是Spark Streaming自己跟踪消费的offset,消除了与zk的不一致(Receiver模式消费的Kafka topic的offset是保存在zk中的),所在在Spark Streaming应用的处理过程和输出过程符合Exactly-once语义的情况下,基于Direct模式就可以使得Spark Streaming应用完全达到Exactly-once语义
Spark Streaming程序怎么做到不丢数据
因为Spark Streaming在接收数据的时候有两种模式,第一种是基于Receiver模式,第二种是Kafka Direct模式,两者不丢数据的处理方式不一样,所以我们需要了解掌握这两种模式不丢数据的处理策略:
基于Receiver模式:
在这种模式下,我们可以使用checkpoint + WAL + ReliableReceiver的方式保证不丢失数据,就是说在driver端打开chechpoint,用于定期的保存driver端的状态信息到HDFS上,保证driver端的状态信息不会丢失;在接收数据Receiver所在的Executor上打开WAL,使得接收到的数据保存在HDFS中,保证接收到的数据不会丢失;因为我们使用的是ReliableReceiver,所以在Receiver挂掉的期间,是不会接收数据,当这个Receiver重启的时候,会从上次消费的地方开始消费。
所以我们可以总结Spark Streaming的checkpoint机制包括driver端元数据的checkpoint以及Executor端的数据的checkpoint(WAL以及updateStateByKey等也需要checkpint),Executor端的checkpoint机制除了保证数据写到HDFS之外,还有切断很长的RDD依赖的功效
Kafka Direct模式:
这种模式下,因为数据源都是存储在Kafka中的,所以一般不会丢数据,但是有一种情况下可能会丢失数据,就是当Spark Streaming应用失败后或者升级重启的时候因为没有记住重启之前消费的topic的offset,使得重启后Spark Streaming从topic的最新的offset开始消费(这个是默认的行为),这样就导致Spark Streaming消费不到失败或者重启过程中Kafka接收到的消息,解决这个问题的办法有三个:
1.使用Spark Streaming自带的Driver端checkpoint机制,因为Driver端checkpoint机制会定期的保存Driver端的状态信息,当然也包括当前批次消费的Kafka中topic的offset信息啦,这样下次重启的时候就可以从checkpoint文件中直接读取上次消费到的offset信息,然后从这个offset开始消费。但是Driver端的checkpoint机制有一个很明显的缺陷,因为Driver端的checkpoint机制保存的Driver端的状态信息还包含DStreamGraph的状态信息,说白了就是将Driver端的代码序列化到checkpoint文件中,这样的话,如果我们对代码做了很大的改动或者升级的话,那么升级后的代码和checkpoint文件中的代码不兼容,这样的话会导致重启失败,解决这个问题的方法就是每次升级的时候将checkpoint文件清除掉,但是这样做的话也清除了保存在checkpoint文件中上次消费到的offset信息,这个不是我们想要的,所以这种方式不可取
2.我们可以在每一个批次开始之前将我们消费到的offset手动的保存到其他第三方存储系统中,可以是zookeeper或者Hbase
3.也可以直接调用Kafka中高级的API,将消费的offset信息保存到zookeeper中当重启Spark Streaming应用的时候,Spark Streaming会自动的从zookeeper中拿到上次消费的offset信息
保存offset的案例
/**
* 将Spark Streaming消费的kafka的offset信息保存到zookeeper中
* @param zkHosts zookeeper的主机信息
* @param zkPath offsets存储在zookeeper的路径
*/
class ZooKeeperOffsetsStore(zkHosts: String, zkPath: String) extends OffsetsStore with Serializable {
private val logger = LoggerFactory.getLogger("ZooKeeperOffsetsStore")
@transient // transient意思是在写磁盘的时候会忽略掉这个属性
private val client = CuratorFrameworkFactory.builder() // 创建ZK的客户端
.connectString(zkHosts)
.connectionTimeoutMs(10000) // 超时时间
.sessionTimeoutMs(10000) // 重试间隔时间
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build()
client.start()
/**
* 从zookeeper上读取Spark Streaming消费的指定topic的所有的partition的offset信息
* @param topic
* @return
*/
override def readOffsets(topic: String): Option[Map[TopicPartition, Long]] = {
logger.info("Reading offsets from ZooKeeper")
val stopwatch = new Stopwatch()
val offsetsRangesStrOpt = Some(new String(client.getData.forPath(zkPath))) // 从zkpath去读消费情况的数据
offsetsRangesStrOpt match {
case Some(offsetsRangesStr) =>
logger.info(s"Read offset ranges: ${offsetsRangesStr}")
if (offsetsRangesStr.isEmpty) {
None
} else { // 不是空的话就对数据进行解析
val offsets = offsetsRangesStr.split(",")
.map(s => s.split(":"))
.map { case Array(partitionStr, offsetStr) => (new TopicPartition(topic, partitionStr.toInt) -> offsetStr.toLong) }
.toMap
logger.info("Done reading offsets from ZooKeeper. Took " + stopwatch)
Some(offsets)
}
case _ =>
logger.info("No offsets found in ZooKeeper. Took " + stopwatch)
None
}
}
/**
* 将指定的topic的所有的partition的offset信息保存到zookeeper中
* @param topic
* @param rdd
*/
override def saveOffsets(topic: String, rdd: RDD[_]): Unit = {
logger.info("Saving offsets to ZooKeeper")
val stopwatch = new Stopwatch()
val offsetsRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetsRanges.foreach(offsetRange => logger.info(s"Using $offsetRange"))
// 分区和offset进行拼接
val offsetsRangesStr = offsetsRanges.map(offsetRange => s"${offsetRange.partition}:${offsetRange.fromOffset}")
.mkString(",") //partition1:220,partition2:320,partition3:10000
logger.info(s"Writing offsets to ZooKeeper: $offsetsRangesStr")
client.setData().forPath(zkPath, offsetsRangesStr.getBytes())
//ZkUtils.updatePersistentPath(zkClient, zkPath, offsetsRangesStr)
logger.info("Done updating offsets in ZooKeeper. Took " + stopwatch)
}
}
优雅的停止Spark Streaming程序
参考:https://blog.csdn.net/weixin_42411818/article/details/100849698
Spark Ml和MLlib
导读
机器学习(machine learning, ML)是一门涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域的交叉学科。ML专注于研究计算机模拟或实现人类的学习行为,以获取新知识、新技能,并重组已学习的知识结构使之不断改善自身。
MLlib是Spark提供的可扩展的机器学习库。MLlib已经集成了大量机器学习的算法,由于MLlib涉及的算法众多,读者如果想要对公式进行推理,需要自己寻找有关概率论、数理统计、数理分析等方面的专门著作。
更多参考:https://www.cnblogs.com/swordfall/p/9456222.html
ml和mllib的主要区别和联系如下
1.ml和mllib都是Spark中的机器学习库,目前常用的机器学习功能2个库都能满足需求。
2.spark官方推荐使用ml, 因为ml功能更全面更灵活,未来会主要支持ml,mllib很有可能会被废弃(据说可能是在spark3.0中deprecated)。
3.ml主要操作的是DataFrame, 而mllib操作的是RDD,也就是说二者面向的数据集不一样。相比于mllib在RDD提供的基础操作,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低。
4.DataFrame和RDD什么关系?DataFrame是Dataset的子集,也就是Dataset[Row], 而DataSet是对RDD的封装,对SQL之类的操作做了很多优化。
5.相比于mllib在RDD提供的基础操作,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低。
6.ml中的操作可以使用pipeline, 跟sklearn一样,可以把很多操作(算法/特征提取/特征转换)以管道的形式串起来,然后让数据在这个管道中流动。大家可以脑补一下Linux管道在做任务组合时有多么方便。
7.ml中无论是什么模型,都提供了统一的算法操作接口,比如模型训练都是fit;不像mllib中不同模型会有各种各样的trainXXX。
8.mllib在spark2.0之后进入维护状态, 这个状态通常只修复BUG不增加新功能。
浅谈推荐系统的种类
推荐系统的种类

1.推荐系统中的推荐算法 - 基于内容的推荐算法(Content-based)


2.推荐系统中的推荐算法 - 协同过滤的推荐算法(Collaborative Filtering - CF) 目前比较常用的

Rating: 1、Ratings可以是数字类型的1-5分,也可以是类似于 strongly agree, agree, neutral, disagree, strongly disagree这样的文本数据 2、Rating可以是二元模型选择,比如:agree/disagree 或者 good/bad 3、Rating可以是一元的,比如可以表示用户是否浏览过或者购买过产品 计算Rating的手段: Explicit ratings(显示打分): 用户直接给产品打分 Implicit ratings(隐式打分): 从用户行为中推断出来的分数,比如一个用户浏览了产品或者 购买了产品,表示用户喜欢这个产品 Explicit ratings(显示打分) + Implicit ratings(隐式打分) 联合

3.推荐系统中的推荐算法 - 基于用户的协同过滤(User-Based CF)

4.推荐系统中的推荐算法 - 基于产品的协同过滤(Item-Based CF)

5.推荐系统中的推荐算法 - 相似度计算



6.推荐系统中的推荐算法 - 隐语义模型(Latent Factor Model) 也比较常用


推荐系统中的推荐算法 - 隐语义模型(Latent Factor Model) - 正则化
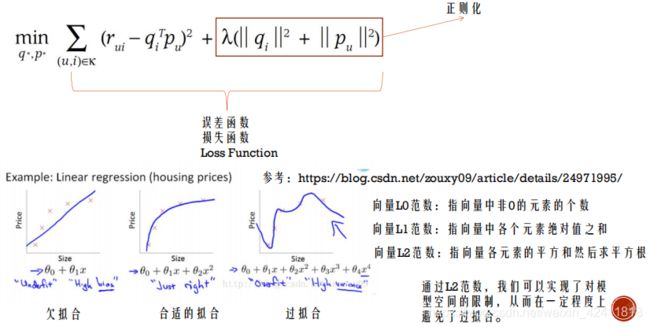

推荐算法的常见架构 – Lambda架构
机器学习的7大步骤
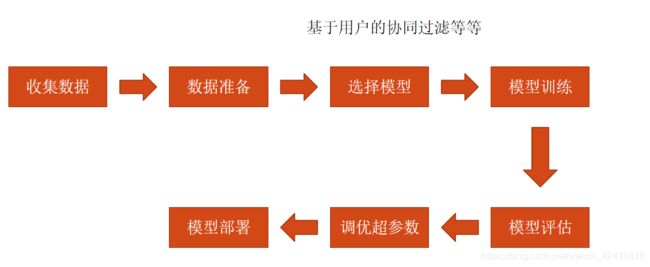
真正的推荐系统的大概流程图

实时训练的模型:因为数据只有新来的,所以推荐的结果是近似的,但是满足实时的要求
离线训练的模型:因为数据是全量的,所以推荐的结果更加的准确,但是不能满足实时
架构流程图
流程架构

具体的架构


浅谈利用spark ml ALS和RegressionEvaluator实现推荐
object ALSExample {
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = { // 解析数据
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("ALSExample")
.getOrCreate()
import spark.implicits._ // 导入所有的隐式转换
// 读取数据,转成DF
val ratings = spark.read.textFile("data/mllib/als/sample_movielens_ratings.txt")
.map(parseRating)
.toDF()
val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2)) // 将数据源分成0.8分做建模,0.2做测试使用
// 利用ALS训练数据建立推荐模型
val als = new ALS()
.setMaxIter(5) // 最大的迭代次数,直接影响模型的准确性
.setRegParam(0.01) // 正则化参数 0-1 直接影响模型的准确性 这两个参数由为重要,感兴趣的可以去看看怎么设置参数批量的选择性建模
.setUserCol("userId") // 为哪个字段做推荐
.setItemCol("movieId") // 推荐的字段
.setRatingCol("rating") // 打分的字段
val model = als.fit(training) // 导入模型
// 通过计算测试数据上的RMSE(线性回归)来评估模型
// 注意,我们将冷启动(可以去参考:https://blog.csdn.net/weixin_41843918/article/details/88607777)策略设置为“drop”,以确保不获得NaN评估指标
model.setColdStartStrategy("drop")
val predictions = model.transform(test) // 导入测试数据,以便测试
val evaluator = new RegressionEvaluator()
.setMetricName("rmse") // 标准是 均方根误差
.setLabelCol("rating") // 测试的是打分的字段
.setPredictionCol("prediction") // 测试结果的字段 预测字段
val rmse = evaluator.evaluate(predictions) // 计算标准的均方根误差 RMSE小说明你的模式对于所有区域的预报水平都相当,反之,RMSE较大,那么你的模式在不同区域的预报水平存在着较大的差异
println(s"Root-mean-square error = $rmse")
// 为每个用户推荐十部电影
val userRecs = model.recommendForAllUsers(10)
// 为每部电影生成前10名用户推荐
val movieRecs = model.recommendForAllItems(10)
// 查看结果
userRecs.show()
movieRecs.show()
spark.stop()
}
}
Spark GraphX
参考:https://www.jianshu.com/p/ad5cedc30ba4,https://www.cnblogs.com/mengrennwpu/p/10543237.html
源码导读
部署的流程
Spark任务划分、调度、执行
Spark 通讯架构