python爬取前程无忧宁波职位薪酬进行初步分析
python爬取前程无忧宁波职位薪酬进行初步分析
对自己的学习经历做个记录。
一、用Scrapy爬取数据并存入MongoDB
spider.py
import scrapy
from www51job.items import Www51JobItem
class nbcaiwu(scrapy.Spider):#要使用 scrapy 爬虫,继承 scrapy.Spider 这个类,这样才能使用它定义的一些方法
name = "nbcaiwu" #定义一个爬虫的名称
#定义请求
def start_requests(self):
urls =[
'https://search.51job.com/list/080300,000000,0000,00,3,99,%25E8%25B4%25A2%25E5%258A%25A1,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
content_list_div = response.css('div#resultList.dw_table div.el')
for content_div in content_list_div:
item = Www51JobItem()
item['职位名'] = content_div.css('p.t1 span a::text').get()
item['公司名'] = content_div.css('span.t2 a::attr(title)').get()
item['工作地点'] = content_div.css('span.t3::text').get()
item['薪资'] = content_div.css('span.t4::text').get()
yield item
next_page = response.xpath('//*[@id="resultList"]/div[55]/div/div/div/ul/li[8]/a').attrib['href']
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
配置管道文件pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class Www51JobPipeline(object):
collection_name = '51job宁波IT' # 这里的地方是连接的数据库表的名字
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'), # get中有两个参数,一个是 配置的MONGO_URL ,另一个是localhost
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items') # 这里的两个参数,第一个是数据库配置的.第二个是它的表的数据库的名字
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
爬完保存入MongoDB
这里爬了财务数据和IT类的数据,了解行情
二、pandas分析一下
# -- coding:utf-8 --
import pymongo
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
conn = pymongo.MongoClient('127.0.0.1',port=27017)
db = conn['51job']['51job宁波财务']
data = pd.DataFrame(list(db.find()))
df = data[['薪资']]
#删除‘薪资’列,值为‘薪资’的所有行
df = df[(True^df['薪资'].isin(['薪资']))]
#删除所有包含空值的行
df = df.dropna()
df['薪资范围'],df['年月'] = df['薪资'].str.split('/',n=1).str
df.drop("薪资",axis=1,inplace=True)#删除原有的列
df['最低薪资'],df['最高薪资0'] = df['薪资范围'].str.split('-',n=1).str
df.drop("薪资范围",axis=1,inplace=True)#删除原有的列
df['单位'] = df['最高薪资0'].str.extract(r'([\u4E00-\u9FA5])')
df['最高薪资'] = df['最高薪资0'].str.extract(r'(\d+.\d+|\d+)')
df.drop("最高薪资0",axis=1,inplace=True)#删除原有的列
df.单位[df['单位']=='千']=1000
df.单位[df['单位']=='万']=10000
df.年月[df['年月']=='年']=12
df.年月[df['年月']=='月']=1
df = df.dropna()
df['最低薪资']=df['最低薪资'].astype(float)
df['最高薪资']=df['最高薪资'].astype(float)
df['单位']=df['单位'].astype(float)
df['年月']=df['年月'].astype(float)
df['最低薪资(元)']=(df['最低薪资']*df['单位']/df['年月']).round(0)
df['最高薪资(元)']=(df['最高薪资']*df['单位']/df['年月']).round(0)
df.drop("最高薪资",axis=1,inplace=True)#删除原有的列
df.drop("最低薪资",axis=1,inplace=True)#删除原有的列
df.drop("单位",axis=1,inplace=True)#删除原有的列
df.drop("年月",axis=1,inplace=True)#删除原有的列
df['最低薪资(元)'] = df[ df['最低薪资(元)'] < 50000]
df['最高薪资(元)'] = df[ df['最高薪资(元)'] < 50000]
iq = df['最低薪资(元)']
mean = iq.mean()
std = iq.std()
#normfun正态分布函数,mu: 均值,sigma:标准差,pdf:概率密度函数,np.exp():概率密度函数公式
def normfun(x,mu, sigma):
pdf = np.exp(-((x - mu)**2) / (2* sigma**2)) / (sigma * np.sqrt(2*np.pi))
return pdf
# x的范围为1000-10000,以1为单位,需x根据范围调试
x = np.arange(0,30000,300)
# x数对应的概率密度
y = normfun(x, mean, std)
# 参数,颜色,线宽
plt.plot(x,y, color='g',linewidth = 3)
#数据,数组,颜色,颜色深浅,组宽,显示频率
plt.hist(iq, bins =50, color = 'r',alpha=0.5,rwidth= 0.9, normed=True)
from matplotlib.font_manager import FontProperties
font_set = FontProperties(fname=r"c:\windows\fonts\msyh.ttf", size=12)
plt.title(u'51job宁波财务薪资分布表',fontproperties=font_set)
plt.xlabel(u'薪资',fontproperties=font_set)
plt.ylabel(u'概率',fontproperties=font_set)
plt.show()
一开始没去除极值

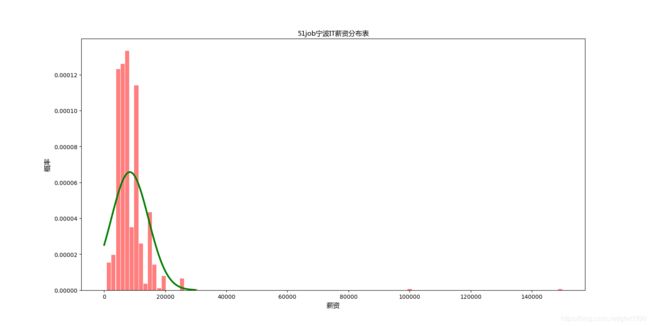
明显看出财务和IT的极值很高,但概率都不高,尤其是财务,极值居然比IT高。
这种基本招的是大神或者干脆写错了,于是把代码改下删除>50000的数值。
在这里插入图片描述

图上来看,宁波财务基本在3k-6k之间,另有一些8k ,10k的数据。
正态分布高峰在6k
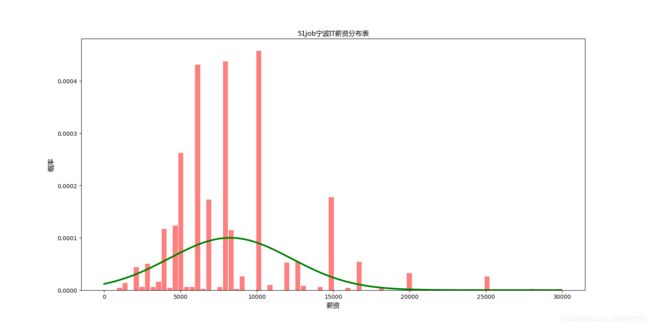
宁波IT基本在6k,8k,10k这几个档位吧,另有一些5k,15k的。
正态分布高峰在8k
总体看来IT薪资更高啊。
不过51job上财务的招聘有4300条,IT的就只有1300条,需求差距也是差的不小的。