从一维到多维理解卡尔曼滤波(通俗易懂)
从一维到多维理解卡尔曼滤波
写在前面
- 本文以移动机器人定位问题(Localization)为例
- 借鉴Udacity课程:AI for Robotics
- 对于一切问题,降维思考都是个好办法
卡尔曼滤波的核心思想
- 根据上一个状态得到当前状态的 “带误差的预测值”;
- 在当前状态使用某种测量工具得到 “带误差的测量值”;
- 根据上述两个值计算得到当前状态的最优值;
- 在当前状态的最优值基础上,加上该状态要发生的动作,得到下一状态带误差的预测值
一维卡尔曼滤波
一维高斯分布 (Gaussian Distribution)
要讲卡尔曼滤波,就不得不说高斯分布,因为**“带误差的预测值”和“带误差的测量值”均为高斯分布**,卡尔曼滤波的工作就是整合这两个值的高斯分布。
任意高斯分布都可以由 ( μ , σ 2 ) (\mu , \sigma^2) (μ,σ2)来表征, μ \mu μ 为高斯分布的均值, σ 2 \sigma^2 σ2则为方差
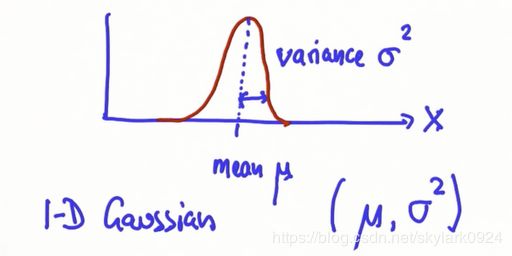
由图可明显看出, ( μ , σ 2 ) (\mu , \sigma^2) (μ,σ2)大小对高斯分布的影响如下:
- μ \mu μ决定了高斯分布对称轴或者说峰值的位置
- σ 2 \sigma^2 σ2决定了高斯分布的宽度(和高度)。
- σ 2 \sigma^2 σ2越大,误差越大,Gaussian越矮胖;
- 反之,误差越小,Gaussian越高瘦;
- 由于Gaussian曲线下的面积恒等于1,就决定了越宽的Gaussian峰值越小,越窄的Gaussian峰值越高。
公式
这里有必要给出Gaussian的公式:
f ( x ) = 1 2 π σ 2 exp [ − 1 2 ( x − μ ) 2 σ 2 ] f(x)=\frac{1}{\sqrt{2 \pi \sigma^{2}}} \exp \left[\frac{-1}{2} \frac{(x-\mu)^{2}}{\sigma^{2}}\right] f(x)=2πσ21exp[2−1σ2(x−μ)2]
卡尔曼滤波利用Gaussian在重复地做这两件事:
- 测量值更新(Measurement updates)
- 预测值(动作)更新(Prediction/Motion updates)
上述两个值的更新方式分两种:直接乘积(product) 和 卷积(convolution)
- 对于测量值使用直接乘积,贝叶斯定理来计算
- 对于预测值使用卷积,
测量值更新(Measurement updates)
现假设你正在定位一个机器人,位置的先验分布(上一步的预测值,在下一节介绍)为黑色曲线,接着由传感器测量得到了如蓝色曲线一样的测量值曲线。

那么很明显两个数据融合之后的Gaussian变为
- 均值在 μ \mu μ 和 ν \nu ν之间,且更靠近 ν \nu ν(因为蓝色曲线的方差更小,对位置的估计更加精确,所以我们更信任它),
- 峰值也较两个组成的Gaussian更高(因为在借鉴了两组数据之后,我们对位置更加确信,方差更小)
公式
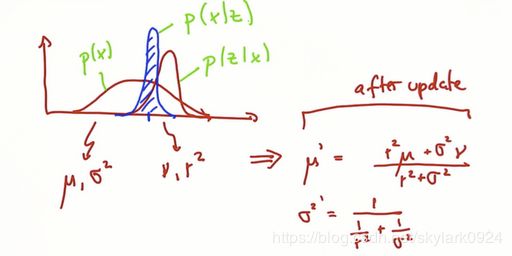
测量值Gaussian参数按如下公式更新
μ ′ = r 2 μ + σ 2 ν r 2 + σ 2 \mu^{\prime}=\frac{r^{2} \mu+\sigma^{2} \nu}{r^{2}+\sigma^{2}} μ′=r2+σ2r2μ+σ2ν
σ 2 ′ = 1 1 r 2 + 1 σ 2 {\sigma^{2}}^{\prime}=\frac{1}{\frac{1}{r^{2}}+\frac{1}{\sigma^{2}}} σ2′=r21+σ211
预测值(动作)更新(Prediction/Motion updates)
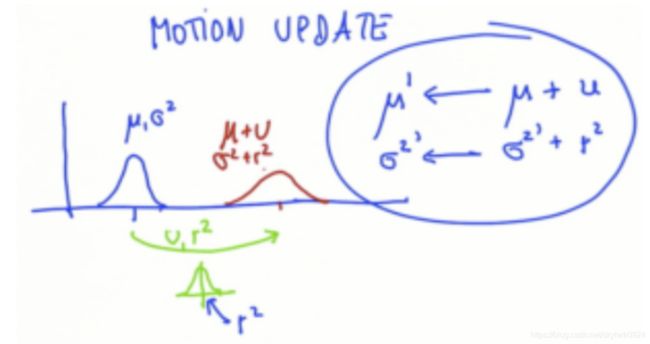
预测值的更新就简单了,均值和方差都是直接求和。当我们将预测值视作机器人的动作更新的话,就好理解了。蓝色曲线代表目前位置的最优估计(根据上一节的测量值更新得到),绿色曲线代表下一步要运动的距离(有误差,可以理解为要让电机转多少圈)。那么下一时刻的预测位置是不是就是目前位置+运动距离了?误差是不是也变成了二者误差的和了?
预测值Gaussian参数按如下公式更新:
μ ′ = μ + ν σ 2 ′ = σ 2 + r 2 \begin{array}{l}{\mu^{\prime} = \mu+\nu} \\ {{\sigma^{2}}^{\prime} = \sigma^{2}+r^{2}}\end{array} μ′=μ+νσ2′=σ2+r2
总结
以上即为一维卡尔曼滤波。总结一下:
- 我们使用测量值更新来融合 传感器测量到的带误差的位置信息 以及 基于上一状态的预测信息,得到当前状态的最优位置估计 (Measurement updates)
- 根据 下一步要进行的动作 以及 当前状态的最优位置估计,得到下一状态的预测值 (Prediction/Motion updates)
卡尔曼滤波就是这么简单的两步循环,不断借助多方数据,逼近实际值。
多维卡尔曼滤波
在多维空间中,卡尔曼滤波不仅能估计位置(传感器仅能够测量位置),还能够根据数据估计出速度信息,因此多为卡尔曼滤波可以综合速度信息估计出未来位置。
多元高斯
设空间维度为n
- 均值是一个n维的向量
- 方差变为协方差,是一个 n × n n \times n n×n 阶矩阵
以二维高斯为例, ( x 0 , y 0 ) (x_0,y_0) (x0,y0)表示均值,两个维度之间是相关的。
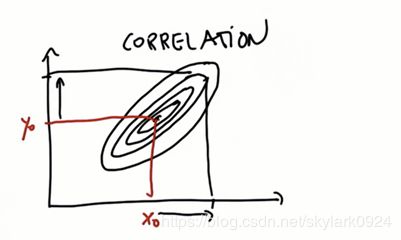
等高线越小的Gaussian不确定性越小,下图横轴上的不确定性很小,但纵轴方向的不确定性很大。如果将横轴视作位置,纵轴视作速度,我们根据单次测量值得到的Gaussian就是这样。(因为我们假设传感器只能测量到位置信息,所以速度的不确定性巨大)

以(1,0)为起点,速度为1,则下一时刻应在(2,1)点
同理,以(1,0)为起点,速度为2,则下一时刻应在(3,2)点
由此可知蓝色的一维信息和红色的二维信息是有关系的。
测量值更新
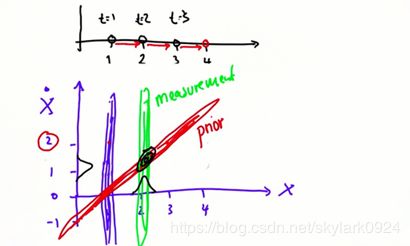
接下来,单看第二状态的测量值(绿色等高线),将其与状态先验(红色等高线)相乘,即得到该状态速度和位置的最优估计(黑色等高线),很明显得到的估计值只有很小的不确定性。
预测值更新
新位置的预测值只有位置信息,和一维的情况一样,公式为
x ′ = x + u x^{\prime}=x+u x′=x+u
新位置也可以视作当前位置加上速度
多维卡尔曼滤波器设计


| 参数说明 | 预测值更新公式 |
|---|---|
| x x x: 当前位置估计 | x ′ = F x + u x'=Fx+u x′=Fx+u |
| P P P: 协方差矩阵 | P ′ = F P F T P'=FPF^T P′=FPFT |
| F : F: F: 状态转移矩阵 | 测量值更新公式 |
| u u u: 动作向量 | y = Z − H x y=Z-Hx y=Z−Hx |
| Z : Z: Z: 测量值 | S = H P H T + R S=HPH^T+R S=HPHT+R |
| H : H: H: 测量矩阵 | K = P H T S − 1 K=PH^TS^{-1} K=PHTS−1 |
| R : R: R: 测量误差 | x ′ = x + K y x'=x+Ky x′=x+Ky |
| I : I: I: 单位矩阵 | P ′ = ( I − K H ) P P'=(I-KH)P P′=(I−KH)P |