k近邻法(三)|构造平衡kd树+搜索kd树| 《统计学习方法》学习笔记(十四)
k近邻法的实现:kd树
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这点在特征空间的维数大及训练数据容量大时尤其必要。
k近邻法最简单的实现方法是线性扫描(linear scan)。这时要计算输入实例与每一个训练实例的距离。当训练集很大时,计算非常耗时,这种方法是不可行的。
为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。
1. 构造kd树(kd tree)
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。
构造kd树方法:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点。在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)为切分点,这样得到的kd树是平衡的。注意,平衡的kd树搜索时的效率未必是最优的。
算法:构造平衡kd树
输入:k维空间数据集 T = { x 1 , x 2 , . . . , x N } T=\{x_1,x_2,...,x_N\} T={x1,x2,...,xN},
其中 x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( k ) ) T , i = 1 , 2 , . . , N x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(k)})^T,i=1,2,..,N xi=(xi(1),xi(2),...,xi(k))T,i=1,2,..,N
输出:kd树
(1)开始:构造根结点,根结点对应于包含T的k维空间的超矩形区域。
选择 x ( 1 ) x^{(1)} x(1)为坐标轴,以T中所有实例的 x ( 1 ) x^{(1)} x(1)坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 x ( 1 ) x^{(1)} x(1)垂直的超平面实现。
由根结点生成深度为1的左、右子结点:左子结点对应坐标 x ( 1 ) x^{(1)} x(1)小于切分点的子区域,右子结点对应坐标 x ( l ) x^{(l)} x(l)大于切分点的子区域。
将落在切分超平面上的实例点保存在根结点。
(2)重复:对深度为j的结点,选择 x ( l ) x^{(l)} x(l)为切分的坐标轴, l = j ( m o d k ) + 1 l=j(mod\space k)+1 l=j(mod k)+1,以该结点的区域中所有实例的 x ( l ) x^{(l)} x(l)坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 x ( l ) x^{(l)} x(l)垂直的超平面实现。
由该结点生成深度为 j + 1 j+1 j+1的左、右子结点:左子结点对应坐标 x ( l ) x^{(l)} x(l)小于切分点的子区域,右子结点对应坐标 x ( l ) x^{(l)} x(l)大于切分点的子区域。
将落在切分超平面上的实例点保存在该结点。
(3)直到两个子区域没有实例存在时停止,从而形成kd树的区域划分。
例:给定一个二维空间的数据集:
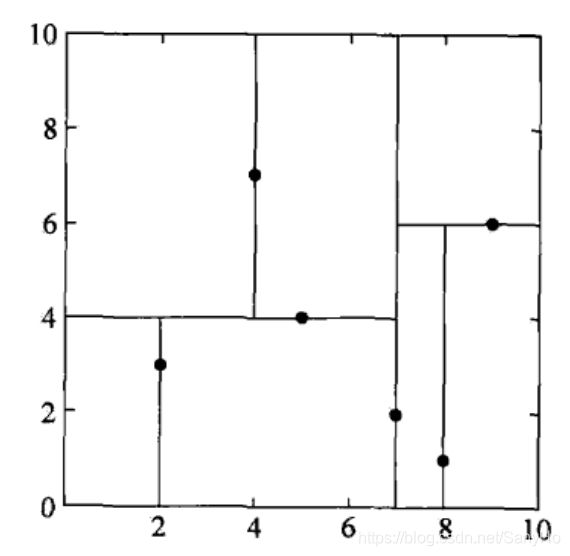
T = { ( 2 , 3 ) T , ( 5 , 4 ) T , ( 9 , 6 ) T , ( 4 , 7 ) T , ( 8 , 1 ) T , ( 7 , 2 ) T } T=\{(2,3)^T,(5,4)^T,(9,6)^T,(4,7)^T,(8,1)^T,(7,2)^T\} T={(2,3)T,(5,4)T,(9,6)T,(4,7)T,(8,1)T,(7,2)T}
构造一个平衡kd树。
解:根结点对应包含数据集T的矩形,选择 x ( 1 ) x^{(1)} x(1)轴,6个数据点的 x ( 1 ) x^{(1)} x(1)坐标的中位数是7,以平面 x ( 1 ) = 7 x^{(1)}=7 x(1)=7将空间分为左、右两个子矩形(子结点);接着,左矩形以 x ( 2 ) = 4 x^{(2)}=4 x(2)=4分为两个子矩形,左矩形以 x ( 2 ) = 4 x^{(2)}=4 x(2)=4分为两个子矩形,右矩形以 x ( 2 ) = 6 x^{(2)}=6 x(2)=6分为两个子矩形,如此递归,最后得到下图所示的特征空间划分和kd树。

2. 搜索kd树
利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。这里以最近邻为例加以叙述,同样的方法可以应用到k近邻。
给定一个目标点,搜索其最近邻。首先找到包含目标点的叶结点;然后从该叶结点出发,依次回退到父结点;不断查找与目标点最邻近的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
包含目标点的叶结点对应包含目标点的最小超矩形区域。以此叶结点的实例点作为当前最近点。目标点的最近邻一定在以目标点为中心并通过当前最近点的超球体的内部。然后返回当前结点的父结点,如果父结点的另一子结点的超矩形区域与超球体相交,那么在相交的区域内寻找与目标点更近的实例点。如果存在这样的点,将此点作为新的当前最近点。算法转到更上一级的父结点,继续上述过程。如果父结点的另一子结点的超矩形区域与超球体不相交,或不存在比当前最近点更近的点,则停止搜索。
算法:用kd树的最近邻搜索法
输入:已构造的kd树;目标点x;
输出:x的最近邻
(1)在kd树中找出包含目标点x的叶结点,从根结点出发,递归地向下访问kd树。若目标点x当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止。
(2)以此叶结点为”当前最近点“。
(3)递归地向上回退,在每个结点进行以下操作:
(a)如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为”当前最近点“。
(b)当前最近点一定存在于该结点一个子结点所对应的区域。检查该子结点的父结点的另一个结点对应的区域是否有更近的点。具体地,检查另一子结点对应的区域是否与以目标点为球心、以目标点与”当前最近点“间的距离为半径的超球体相交。 如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点。接着,递归地进行最近邻搜索。如果不相交,向上回退。
(4)当回退到根结点时,搜索结束。最后的”当前最近点“即为x的最近邻点。
如果实例点是随机分布的,kd树搜索的平均计算复杂度是 O ( l o g N ) O(logN) O(logN),这里N是训练实例数。kd数更适合用于训练实例数远大于空间维数时的看近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
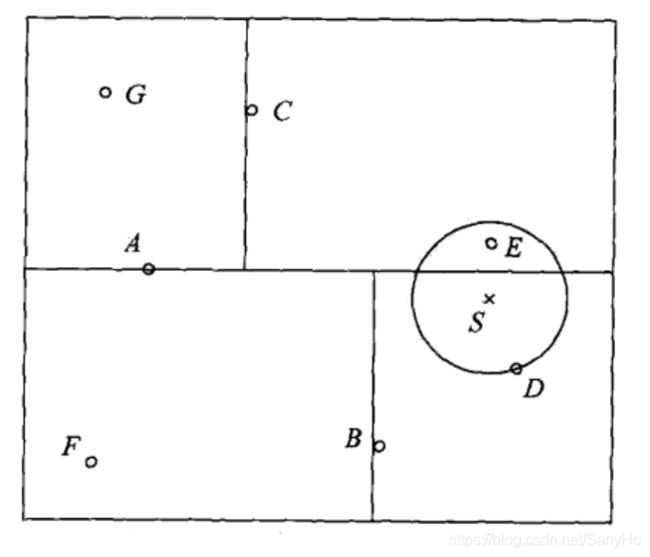
例:给定一个下图所示的kd树,根结点为A,其子结点为B,C等。树上共存储7个实例点;另有一个输入目标实例点S,求S的最近邻。
解: 首先在kd树中找到包含点S的叶结点D(图中的右下区域),以点D作为近似最近邻。真正最近邻一定在以点S为中心通过点D的圆的内部。然后返回结点D的父结点B,在结点B的另一子结点F的区域内搜索最近邻。结点F的区域与圆不相交,不可能有最近邻点。继续返回上一级父结点A,在结点A的另一结点的区域内搜索最近邻。结点C的区域与圆相交;该区域在圆内的实例点有点E,点E比点D更近,成为新的最近邻近似。最后得到点E是点S的最近邻。