PointNet训练与测试github开源代码(PointNet实现第5步骤pytorch版)
PointNet第5步——PointNet训练与测试github开源代码
在运行github上的代码时,经常版本不匹配会出现大量的不同,或者报错,这篇主要记录我解决相关报错的方法。
本次测试的是github上的yanx27Pointnet_Pointnet2_pytorch
源码资源【点击此处】在此,感激git主的贡献。
第一步:下载代码
本次程序不太适合用自己笔记本的cpu还跑,还是比较适合用服务器。
下载代码链接如上源码资源

第2步:下载保存数据集
改源码数据集,源码作者已经给出1.59GB
数据集链接【点击此处下载】
下载建议通过服务器来实现,服务器如何下载,命令行直接输入下面:
wget https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip
将下载后的数据集解压保存在代码文件目录下data/modelnet40_normal_resampled/
解压保存(服务器端口操纵)如下:
unzip -d 源代码路径+/data modelnet40_normal_resampled.zip

其他后台操作可参考我的【这篇博客】
第3步:实现与调错
cd 到源码保存的文件路径下,然后

报错1:no model ‘ModelNetDataLoader’
代码路径的问题
报错点在train_cls.py第5行
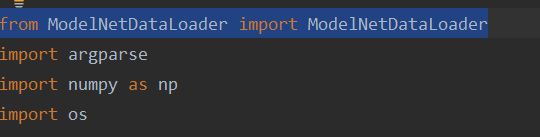
from data_utils.ModelNetDataLoader import ModelNetDataLoader

简单粗暴法:
直接将在data_utils中的ModelNetDataLoader.py复制到train_cls.py同目录下。
然后将from data_utils.ModelNetDataLoader import ModelNetDataLoader 改为from ModelNetDataLoader import ModelNetDataLoader
其他方法:1.添加路径,这个你可以百度一下,sys.path,这里我只介绍最简单的方法。
2.转变为模块,这你也可以在CSDN中查一下,这里忘记截图了,也不打算介绍了。
报错2:no model pathlib
解决:
pip install pathlib
报错3:makedir(exist_ok=True)
原来是版本的不同,python3.5以下版本跟pytorch3.5以上不同,pytorch3.5以下版本没有exist_ok。
解决方法:
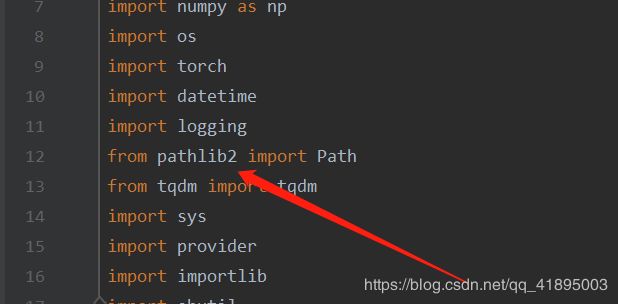
pip install pathlib2
将train_cls.py代码中的pathlib改为pathlib2
如果上述方法不可以,可以参考【这里】
报错4:SyntaxError: Non-ASCII character ‘\xef’ in file pointnet_util.py
原因:Python的默认编码文件是用的ASCII码,你将文件存成了UTF-8也没用
解决方法:
1.简单粗暴法:
将pointnet_util.py中的所有注释(""" “”")删除。
2. 方法2:
在文件开头加入 # -- coding: UTF-8 -- 或者 #coding=utf-8 就行了
# -*- coding: utf-8 -*-
#!/usr/bin/env python
报错5:cuda out of memory
显存不足
解决方法:
1.加显存(够壕)
2.将batch_size改小,在这里的话我改成8。
在train_cls.py中将默认值修改为8:

仍然·解决?——》计算一下网络的计算量,再查看一下你自己的GPU容量,看一下是否超过?如果没有,可能是其他设置原因。
报错6:RuntimeError: cuDNN error: CUDNN_STATUS_NOT_SUPPORTED. This error may appear if you passed in a non-contiguous input.
原因:版本不匹配
解决方法:
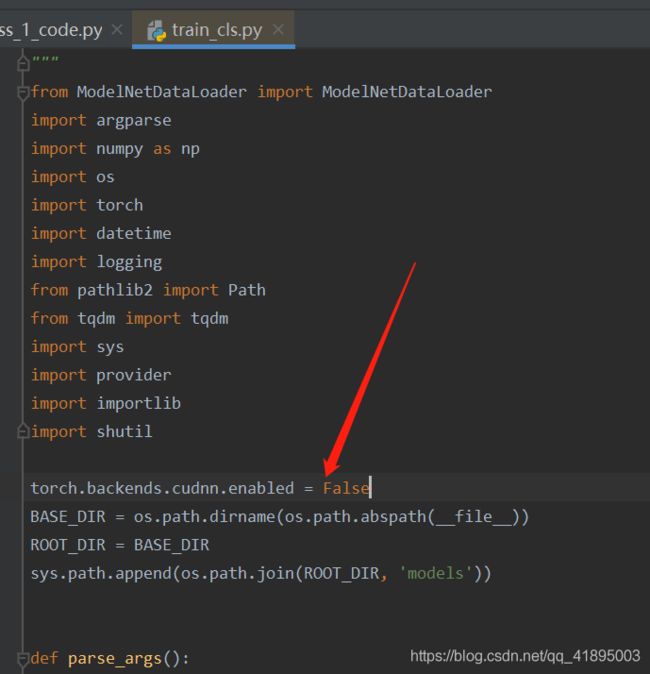
在train_cla.py 前面加上:
torch.backends.cudnn.enabled = False
报错7:
ValueError: Expected more than 1 value per channel when training, got input size torch.Size......
问题分析: 模型中用了batchnomolization,训练中用batch训练的时候,应该是有单数,比如dataset的总样本数为17,你的batch_size为8,就会报这样的错误。输入批次只有一个数据点,而由于BatchNorm操作需要多于一个数据计算平均值,因此造成该错误。
解决方法:
从dataset中删掉一个sample,在获取数据集时,将DataLoader中drop_last设置为True,把不够一个批次的数据丢弃。
如果这操作不可以,请参考【这篇博客】
至此,报错结束,可以运行,上面只记述自己记得的一些报错。
![]()