搭建ResNet18神经网络对cifar10数据集进行训练
搭建ResNet18神经网络对cifar10数据集进行训练
本博客以pytorch1.3框架搭建ResNet18层网络结构进行cifar10数据集训练。
1、ResNet18网络结构的说明
如图1所示:蓝色方框表示18层ResNet网络结构
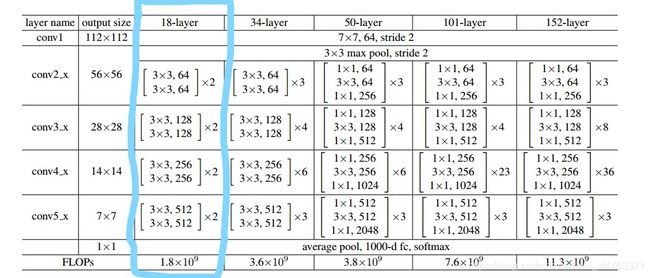
用流程图来看更加直观,如图二所示:

由图2可知:每两层卷积层有一个shotrcut层,相当于一个短路链接,当下面的卷积层达不到更好的效果时,可以保证目前已有的神经网络最好的效果。
2、代码实现ResNet18层结构
import torch
from torch import nn
from torch.nn import functional as F
#定义ResBlk类,包含两层卷积层及shortcut计算。
class ResBlk(nn.Module):
'''
resnet block
'''
def __init__(self,ch_in,ch_out,stride=1):
'''
:param ch_in:
:param ch_out:
:param stride:
:return:
'''
super(ResBlk,self).__init__()
self.conv1 = nn.Conv2d(ch_in,ch_out,kernel_size=3,\
stride=stride,padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out,ch_out,kernel_size=3,\
stride=stride,padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
#shortcut计算,当输入输出通道不相等时,通过1*1的卷积核,转化为相等的通道数。
self.shortcut = nn.Sequential()
if ch_out != ch_in:
self.shortcut = nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),
nn.BatchNorm2d(ch_out)
)
#前项传播运算
def forward(self,x):
'''
:param x:
:return:
'''
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
#shortcut
#extra module:[b,ch_in,h,w] => [b,ch_out, h,w]
out += self.shortcut(x)
out = F.relu(out)
return out
#ResNet18结构框架
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.pre = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(64)
)
#followed blocks
#重复的layer,分别为2个resblk.
self.blk1 = self.make_layer(64,64,2,stride=1)
self.blk2 = self.make_layer(64,128,2,stride=1)
self.blk3 = self.make_layer(128,256,2,stride=1)
self.bll4 = self.make_layer(256,512,2,stride=1)
self.outlayer = nn.Linear(512*1*1,10)
def make_layer(self,ch_in,ch_out,block_num,stride=1):
'''
#构建layer,包含多个ResBlk
:param ch_in:
:param ch_out:
:param block_num:为每个blk的个数
:param stride:
:return:
'''
layers = []
layers.append(ResBlk(ch_in,ch_out,stride))
for i in range(1,block_num):
layers.append(ResBlk(ch_out,ch_out))
return nn.Sequential(*layers)
def forward(self,x):
'''
:param x:
:return:
'''
x = self.pre(x)
#[b,64,h,w] => [b,1024,h,w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
#[b,512,h,w] => [b,512,1,1]
x = F.adaptive_avg_pool2d(x,[1,1])
#print('after pool:', x.shape)
x = x.view(x.size(0),-1)
x = self.outlayer(x)
return x
#测试函数,能否运行
def main():
blk = ResBlk(1,8,stride=1)
tmp = torch.randn(2,1,32,32)
out = blk(tmp)
print('block:',out.shape)
x = torch.randn(3,64,32,32)
model = ResNet18()
out = model(x)
print('resnet:',out.shape)
if __name__ == '__main__':
main()
3、main()函数,训练及测试
mport torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from resnet18 import ResNet18
def main():
#加载图像批次为32
batchsz = 32
#训练集测试集加载
cifar_train = datasets.CIFAR10(root='cifar/', train=True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]),download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10(root='cifar/', train=False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]),download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
#加载图像及标签
x, label = iter(cifar_train).next()
print('x:', x.shape, 'label:', label.shape)
device = torch.device('cuda')
# model = Lenet5().to(device)
model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
#模型训练
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
#模型测试
model.eval()
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
if __name__ == '__main__':
main()
测试时,发现GPU利用很低,同样的结构,减少layer层数GPU利用率会变高,可能是数据加载的问题或其他问题导致GPU利用率下降。
参考博客:https://www.jianshu.com/p/085f4c8256f1